——金融电子化

文 / 中信银行软件开发中心?? 马良有
背 景
信息化、数字化时代,大量姓名含生僻字的公民在金融、电信、出行等各行业办理业务经常受阻,这是“数字鸿沟”的一种表现。通过检查相关页面的HTML代码,我们发现造成这一共性问题的重要技术原因是各行业IT系统用户注册页面大量使用了一个过时的正则表达式判断用户输入姓名是否合法的汉字字符,导致GBK(《汉字内码扩展规范》)之外的合法生僻字都被错误地当作非法字符。
正则表达式是早已出现且又很强大的文本处理技术手段,仅仅用一段非常简短的表达式语句,便能够快速实现一个非常复杂的业务逻辑,其中编写正确的表达式非常重要。但在互联网上搜索“中文正则表达式”“汉字正则表达式”“验证姓名正则表达式”的结果,或者查看“常用正则表达式”“正则表达式大全”相关文章里关于验证汉字正则表达式的部分,几乎百分之百出现“\u4e00-\u9fa5”的过时写法,这是1995年发布的GBK里20902个汉字的GB13000UCS(通用编码字符集)/Unicode(统一码)编码范围。而GBK里另外52个汉字,如U 4DAE的“”、U 4D16的“”等字,无论其正式UCS/Unicode编码,还是GBK收录时被定为PUA(私用区)的临时编码(“”字为E863、“”字为E85F),都不在该正则表达式范围,更别说GBK后陆续被收录的几万个CJK(中、日、韩统一编码)汉字了。1995年时,Windows95只能使用GBK的21003个汉字字符,第一代居民身份证遇到的生僻字还是手写的,所以当时这个不完整的正则表达式影响不大。但20多年之后,GB18030-2000、GB18030-2005、GB13000-2010等国家标准发布已有十几年,且自2004年开始换发的第二代居民身份证芯片里也有不少姓名生僻字是以PUA临时编码(E000~F8FF)存储,Unicode等国际标准更新频繁,收录了大量的生僻汉字并在身份证姓名里有实际使用,所以大量的姓名用字都不在该正则表达式的4E00~9FA5范围。另外,部分少数民族公民的姓名里存在间隔符“·”,其编码00B7也不在该表达式范围。由于大量的程序开发书籍、互联网文章都采纳该正则表达式,广大的前端或后端开发程序员受这些书籍和文章的影响,开发的各类系统几乎都按此不完整的正则表达式对录入的姓名进行校验(其中甚至包括一些近期开发的政府网站和面向公众服务的应用系统),导致大量生僻字姓名公民以及姓名里含间隔符的少数民族公民无法正常注册、使用相关服务。因此,非常有必要对这个流传久远的正则表达式进行纠正,才能帮助广大程序员修复存量系统的问题并避免新建系统再次出现相同的问题。当然,也有后端工程师提议前端没必要进行精准的过滤,在报文中对姓名等字段做好特殊字符转义以防止注入攻击,剩下的检查交由后端去做即可。笔者的意见则是如果原先有不完善的正则表达式,建议还是把它改正确更能被人接受。本文对支持汉字生僻字姓名以及少数民族姓名间隔符的正则表达式的编写方法进行了初步探讨,并已应用到本行的业务系统中。
合法的姓名汉字完整编码范围
查看GB13000-2010国家标准、更新的ISO/IEC10646国际标准及最新的Unicode13.0的资料,可以发现下面表格所述的区域都有汉字或偏旁部首(见表1)。
表 1?? 汉字或偏旁部首及其 UCS 编码范围与归类
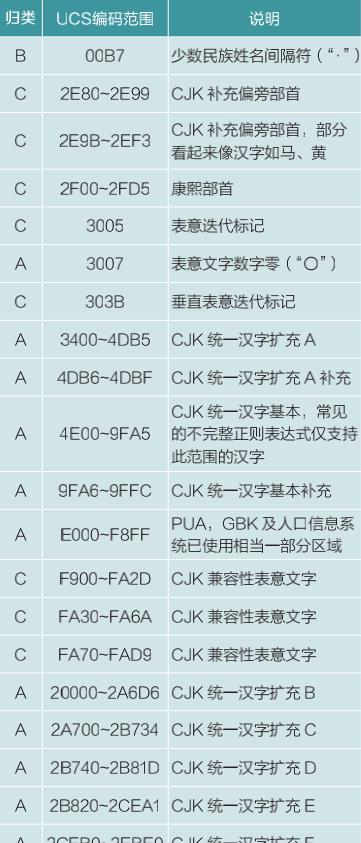
按理,汉字偏旁部首不应作为姓名用字。按有关部门规定,“〇”(U 3007)这个数字汉字不应用于姓名,但前不久我行发现有姓名含“〇”的客户,故该字也是合法的姓名用字。按《关于在政府管理和社会公共服务信息系统中统一姓名采集应用规范的通知》(民委发﹝2016﹞33号),少数民族姓名中间隔符使用“·”(U 00B7)。既然是姓名间隔符,“·”就只能用在姓名汉字中间,不能用于开头和结尾。为便于读者理解形成的正则表达式,我们在表1中把“·”归为B类字,其他可用于姓名的汉字归为A类字,而偏旁部首以及日本、韩国、越南的一些汉字都不用于中国大陆人名,则归为C类字。表1中一些区域尾部还有少量空闲的码位有可能被后续加字填满,考虑扩展性(如后续“CJK统一汉字扩充H”等发布),所以合法的姓名汉字应是如下的UCS/Unicode编码范围(每个平面最后两个编码保留)。
A类字:3007,3400-9FFF,E000-F8FF,20000-2FFFD,30000-3FFFD
B类字:00B7
形成正确的汉字姓名核验
正则表达式
正确的汉字姓名核验正则表达式需要表达下面的意思:(1)正确的汉字姓名必须是一个或多个上述A类字开头。(2)中间允许有0个或多个上述B类字。(3)B类字不能连续两个挨着。(4)B类字不能作为姓名结尾。(5)只要出现过B类字,B类字之后必须有一个或多个A类字。(6)开头和结尾都不能有空格等字符,即头尾都必须遵守上述要求。
根据正则表达式规则,满足这6条要求的正则表达式可以写成“^A (BA )*$”。其中,加号表示其左边的表达式出现一次或多次,两个“A ”都表示A至少出现一次,圆括号的作用是对字符进行分组,“*”号表示0个或更多个,所以“(BA )”的分组可以不出现,也可以出现多次,而圆括号中“BA ”表示的意思就是B的后面必须有一个或多个A。“^”表示匹配字符串开始,“$”表示匹配字符串结束。
由于A类字包含多个范围,因此也需要用圆括号分组,在分组中使用“|”进行多个数据选一,用中括号括起及减号“-”表示两者中编码范围内的任意一个字符。因为对BMP(基本多语言平面)之外的SP(supplementaryplanes,辅助平面)编码,不同的语言甚至不同版本支持格式不一样,存在技术难点,相关书籍或互联网文章很少提及,所以这样完整的正则表达式先用部分伪码形成如下,后面根据具体的语言详细描述实现。

(以上代码因排版原因折行分成多行,实际使用应书写为一行,下同。)
几种常用语言的完整姓名核验
正则表达式示例及验证效果
考虑文章篇幅问题,以下的代码示例不列出完整的多行代码,只列出包含正则表达式的一条语句供参考。基本上将笔者列出的正则表达式部分替换原先代码中不完整的正则表达式即可。
1.Java语言。(1)JDK1.4-1.6。自Sun的JavaJDK1.4版本开始,Java自带了支持正则表达式的包java.util.regex。由于JDK1.7之前SP的字符在正则表达式中必须采用UTF-16的格式表示,所以完整姓名核验正则表达式需要这样写:

(2)JDK1.7及更高版本。因UTF-16的格式表示SP的字符不直观,JDK1.7开始的java.util.regex.Pattern类支持用花括号(”\\x{hhhhh}”)括起超过4位的UCS/Unicode16进制编码,所以完整姓名核验正则表达式可以直观方便地写成:

2.JavaScript语言。ECMAScript6(简称ES6)可用“\u{hhhhh}”格式处理SP(即大于\uFFFF)的UCS/Unicode字符,但IE11等浏览器的JavaScript都还不支持ES6而只支持ES5,所以还是要采用UTF-16的格式表示(与JDK1.6不同的是,其都按UCS2编码的单独char来对待),无论是JS自身的,还是使用jQuery的完整姓名核验正则表达式需要这样写:

3.Python语言。Python3支持”\Uhhhhhhhh”的格式表示超过4位(即SP)的UCS/Unicode16进制编码,但大写的“U”后需左补0填满8位,所以完整姓名核验正则表达式可以直观方便地写成:

4.其他语言。其他语言建议参考上面几种语言的做法,按各自语言和当前版本支持的格式写出完整姓名核验正则表达式。
我们通过使用实际在用的一些姓名生僻字,如“”(由页,U 2CC56)、“”(U 4DAE)、“??”(U E863)、“??”(U 3D65)等,以及包含一个或多个间隔符的少数民族姓名,对上述Java、JavaScript、Python语言的正则表达式进行测试验证,与预期结果一致。在我行的业务系统支持生僻字的改造项目中,我们进行了具体应用,从而成为正在开源的金融业生僻字解决方案的一部分。
关于姓名长度的校验问题
网络上搜索到的一些姓名校验正则表达式除了汉字范围不完整外,有的还对姓名长度进行了过小的限制。按《关于在政府管理和社会公共服务信息系统中统一姓名采集应用规范的通知》(民委发﹝2016﹞33号),在信息系统设置中规定姓名数据项最大长度不少于50个字符(25个汉字)。考虑到前述汉字姓名核验正则表达式的复杂性,笔者不建议在同一正则表达式同时限定姓名长度,而是建议单独检查输入的姓名字符串长度,且不少于50个字符(25个汉字)。我行的对公/对私户名的数据库字段是按不少于120字节或60个汉字来设计的,供参考。
其他特殊情况
1.英文姓名、中英文夹杂/混合姓名的问题。按照有关部门规定,居民身份证、港澳台居住证都不允许中英文夹杂/混合姓名。2009年2月26日,全国瞩目的中国姓名权第一案——“赵C改名案”终审达成庭上和解,“赵C”最终还是要改名才能换领第二代身份证。公安部明确要求姓名登记项目使用汉字填写,未使用规范汉字填写的应请本人协助更正。因此,姓名校验的正则表达式不需要支持“赵C”这样的中英文混合姓名。而对于外国人的英文姓名,笔者建议单独判断,不在同一个正则表达式里同时支持英文姓名和中文姓名,这样程序逻辑相对简单明了。
2.身份证芯片与人口信息系统曾用的替代字符问题。据了解,在人口信息系统的建设过程中,曾用过U FF0E(一个点:“.”)或U 258C(半个小黑块“▌”)作为当时未编码的生僻字替代字符写入身份证芯片与人口信息系统,但身份证表面制发时印刷的还是正确的生僻字字形。后续,人口信息系统数据库中生僻字可能会更新为与户口本一致的生僻字正确编码,但身份证未更换时芯片读出还是U FF0E或U 258C。对于能直接读身份证芯片的渠道系统,如果采用正则表达式判断姓名合法性,可以考虑将编码U FF0E、U 258C加入前述的A类字写入正则表达式,但笔者的意见还是建议提示客户去更换身份证才能保证芯片信息与身份证表面及人口信息系统数据库一致。
3.U 00B7及相似“点”字符的问题。按前述民委发﹝2016﹞33号文,只有U 00B7才是标准的少数民族姓名分隔符,但翻看最新的Unicode13.0资料,各种实心“点”字符至少有19个。
一些“点”字符,由于用户不同输入法的原因,都有可能被用户当作少数民族姓名分隔符输入,一般用户也难以察觉这些“点”的差异。为了提升用户输入的体验,可以考虑将这些特殊“点”或者用户常用的输入法可能输入的那些“点”加入表1都作为B类字写入正则表达式,然后在前端程序发送后端时将姓名中非标准的“点”自动转化为标准的“点”(U 00B7),或者在后端程序中对姓名做这种格式化操作。
结论与展望
针对流传甚广的一个检测中文的正则表达式不支持汉字姓名生僻字和少数民族姓名的问题,我们对其进行了初步修复探讨,并应用于本行的各业务系统及我行提出的开源金融业生僻字解决方案。部分语言的正则表达式目前需用不直观的UTF-16编码格式表示SP的编码,随着其不断升级,未来有可能得到改进,从而有更简便直观的解决方法。中信银行开源金融业生僻字解决方案目前正致力于给行业内IT系统开发人员积极修复存在生僻字问题的业务系统以帮助,金融IT人将以此为人民群众切实办实事、办好事,为填平“数字鸿沟”而努力。
往期精选:
●实战 | 持续测试在商业银行的本地化实践
●实战 | 数据中心IT设备硬件智能化运维探索与实践
●实战 | 商户客户地理大数据营销法
●实战 | 基于大数据的资金交易智能风险引擎实践
●实战 | 运维基础能力中台化,营造场景建设生态圈