由于@北冥乘海生 老师坚持传播负能量,不谈计算广告干货,犯了严重的右倾机会主义错误,现暂停发文一次,由@德川 替代。
特征之间独立性,经常对我们的结论影响很大。比如说,中国的癌症发病率上升,到底是“中国”这个因素的原因呢?还是“平均寿命”这个因素的原因呢?显然这两个因素有一些相关性,因此简单的分别统计,往往也是行不通的。
这个问题比较简单,我们就不多谈了。(想骂街的读者,请稍安勿躁,继续往下看。)
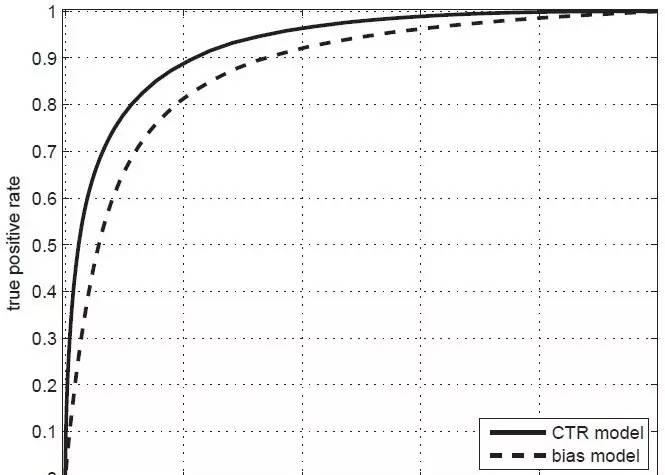
这样的指标是有一个,就是如下图所示的ROC曲线下的面积,术语上称为AUC。(关于ROC和AUC的详细介绍,请大家参考《计算广告》第*章。)AUC这个数值越大,对应的模型区别能力就越强。
那么,是不是小度的模型比小优真的好那么多呢?当然不是,我们看看该视频网站和网盟的广告位分布,就一目了然了。
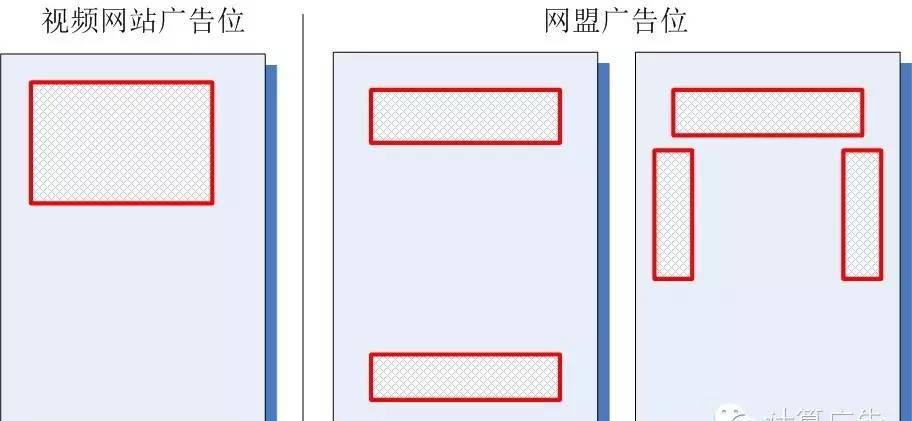
什么?你还没有明白,那么我建议你自己好好把这个问题想清楚。不论你是运营还是产品,经过了这样的思考,你的数据解读能力会上一个台阶。
LR 人工特征工程风光不再
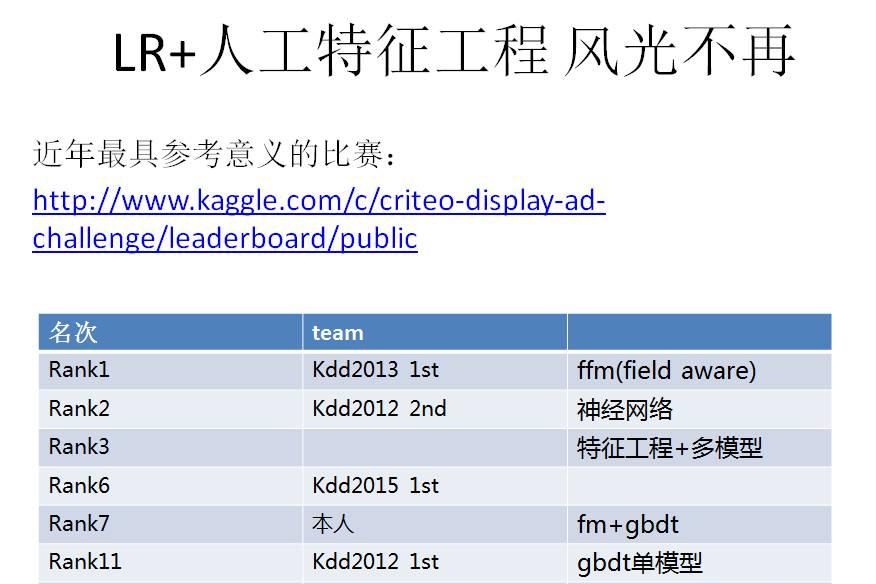
从leadboard中可以看到在700多支team里,Kdd 2012年起的各届冠军,这些比赛型的选手,基本占据了前十的位置,我是第7。其次,从使用的模型上,基本以fm和gbdt,还有神经网络这些非线性模型为主。可以这么说,在比赛里,逻辑回归加大量的人工特征工程的方案已经很难排到比赛前列,靠逻辑回归一个模型包打天下,已经成为过去时。
特征,特征

特征工程是各个公司相对模型来说更看重保密的部分,因为从其中会大致了解到该公司的数据分布,这方面的公开资料不会太多。大体来说,有这么俩部分工作:
首先了解行业的领域知识,去寻找和设计强信号依然重要,比如搜索广告里query和广告创意的相关性是强信号,电商领域图片和价格特征是强信号等。这部分工作是和各家公司业务紧密相关的。
其次如果采用的是逻辑回归这种广义线性模型,需要手动构造特征变换,才能更好处理非线性问题。常见的特征变换方法比如特征组合,特征选择,特征离散化归一化等,多数时候通过eyeballing和统计学的方法来完成。工程师自然是希望能将更多的精力放在设计业务上的强信号特征上面,而特征变换自动的由模型来完成。出于这样的考虑,非线性模型逐渐在取代LR,比如通过FM,GBDT去自动挖掘组合特征,通过GBDT去做特征选择,离散化等,正如上述比赛中看到的。
最后基于一些深度学习的方法,也能够做一些特征发现的事情,举个典型的例子就是语音识别里,dnn已经把MFCC这种人工特征取代了,wer有显著的降低。而在广告领域,DNN目前基本在百度等大公司也正在探索中,发展比较快,这部分今天简单提一下。
模型选择
第一,线性模型还是非线性模型。一般在模型的初期线性模型会作为首选方法采用,有经验的工程师对业务领域中的强信号比较熟悉,能够快速rush完几个版本的特征工程后达到一个不错的基线水平。而当从业务中抽象出强信号越来越困难时,往往就会伴随着比较暴力的特征工程去捕捉业务里的弱信号。随着这一过程的深入,模型训练的代价在快速增长,而收益却逐渐逼近上限。而非线性模型的长期优势则比较明显,模型泛化能力强,调参成本相对较小,能在训练代价和模型精度上达到更好的tradeoff,百度等大公司都已经从LR过渡到了DNN。
模型演进概述
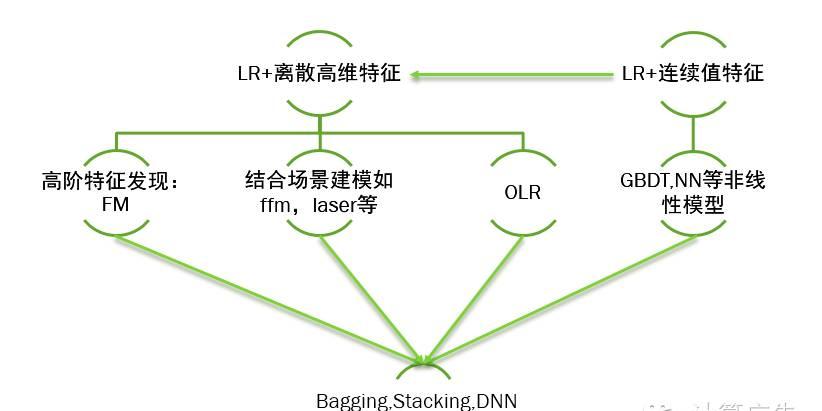
之前提及过,一般会以高维sparse特征的LR模型作为基线模型,也有用dense特征直接结合LR来建模的。由于LR是线性分类器,后者需要对dense特征手工加各种非线性变换,遇到瓶颈后会转向前者,或者改成使用GBDT,NN等非线性模型。而高维sparse特征结合LR的方案,人工在特征工程遇到一定瓶颈后,会采用FM等方案自动做特征发现,为了解决时效性的问题,会结合batch的训练加上Online的更新方式,或者直接转向完全Online的方案如ftrl。还有一个方向是会结合自身的业务场景,对模型的损失函数做一些创新,比如yahoo的laser,阿里的coupled group lasso,比赛里的field aware的ffm等等。
在比赛里为了提升效果,很常见的一个策略是把各个模型融合在一起,最简单的有把各个模型的结果做线性加权,也有把各个模型进行stacking的方案,比如Facebook的gbdt lr,再有把各个模型的信息喂给dnn去学习的。对这三种方案来说,效果最好的,我个人比较相信,是用dnn去做模型的blending(融合)。注意这里说的DNN不是指具体的某个模型dbn,cnn,而是指将各种浅层模型的中间权重,预估结果,原始的静态,动态特征等作为DNN的输入,使用dnn后馈的输入梯度来联合更新这些结构的参数。对DNN大家可能比较诟病的是其训练效率,但我觉得在大公司可能还好,听在百度的朋友说DNN的开发代价和训练开销随着探索在逐步降低,不一定比gbdt等非线性模型代价高很多。
当然,对小公司来说,直接走到DNN有点用力过猛,我在这里简要介绍一下FM gbdt去融合的方案:第一步当然也是基于大规模稀疏特征LR。第二步,为了更好的刻画长尾,自动发现组合特征,采用了FM。在同样的训练时间下,AUC提升,模型泛化性能可控。第三步:为了更好的fine tuning头部和提升时效性,采用了用gbdt加动态特征的模型。最后呢,把这两个模型简单的做线性融合,由于俩个模型的特征和模型差异性较大,融合后auc也有显著的提升。
对于gbdt,开源的实现有很多,但效果差别比较大,这里推荐一个开源实现xgboost,很多kaggle上的比赛借助这个工具都拿到了好名次。之前我写过一篇叫做xgboost导读和实战的文章,对原始paper中的公式给出了一些推导细节,这里不再详述。简单的说原始paper里是在函数空间上梯度下降求解,在求解步长时一般都是固定学习率。而xgboost对损失函数做了二阶的泰勒展开,考虑了损失函数的二阶梯度信息,并加入了正则项整体求最优解,有比较好的泛化性能。另外在具体建树的分裂节点过程也不是大多数实现里基于信息增益等,而是结合具体目标函数的真实下降量。有人做过各实现的评测,xgboost在性能和效果上都是相当不错的。
BSP->SSP
几个典型的模型基本就简要讲到这里,最后讲一下模型求解的优化算法,计算广告书里给出了不少经典的优化凸优化算法的原理和实现代码,LBFGS,trust region等,这些凸优化算法基本上都是扫一遍样本,迭代的更新一次模型参数,想要提升模型训练收敛的效率,主要思路是降低扫样本的成本,比如把样本cache在内存里,另外就是降低迭代轮数,比如书里提到的admm。
这样的batch做迭代的优化方法现在被称为一种叫做BSP(Bulk Synchronous Parallel)的方式,与之相对应的叫做SSP(StalenessSynchronous Parallel),主要是基于异步的minibatch sgd的优化算法来更新,加上了一个bounded的一致性协议来保证收敛。补充一点的是,很多实现中其实是完全异步来实现的,更为简单一些。SSP的方式虽然单轮迭代的网络开销不小,但是扫一遍样本,minibatch sgd可以更新很多次模型,迭代的次数相对LBFGS会降低很多,所以整体的时间开销相对也会少很多,另外可以结合online更新进一步降低训练时间。从底层消息通讯的工程架构上来说,ssp的方式主要是异步的push pull,基于消息队列如zeromq等去实现,相对bsp的这样的同步原语,实现起来相对简单优雅些,也有一些不错的开源实现比如李沐的dmlc。
ssp方式的缺点是数据量少的时候minibatch sgd的优势相对不明显,需要多调调参数,没有batch算法省事。总体说来,趋势是在从bsp的架构往ssp的架构在转,包括一些dnn的实现,基于SSP的方式加Online更新后训练模型的开销相对已经较小了。
参考文献
?? [STEFFEN RENDLE]Factorization Machines with libFM
?? [Jerome H. Friedman] Greedy Function Approximation-A GradientBoosting Machine
?? [li_mu]Scaling Distributed Machine Learning with the ParameterServer
?? https://www.kaggle.com/c/criteo-display-ad-challenge/forums

计算广告
ID: Comp_Ad