https://infogalactic.com/info/Design_of_experiments
The design of experiments (or experimental design) is the design of any task that aims to describe or explain the variation of information under conditions that are hypothesized to reflect the variation. The term is generally associated with true experiments in which the design introduces conditions that directly affect the variation, but may also refer to the design of quasi-experiments, in which natural conditions that influence the variation are selected for observation.
实验设计(The Design of Experiments 或 Experimental Design)是指任何任务的设计,旨在描述或解释信息在假设条件下的变化,以反映变化。该术语通常与真实实验相关,在真实实验中,设计引入了直接影响变化的条件,但也可能指准实验的设计,在准实验中,选择影响变化的自然条件进行观察。
In its simplest form, an experiment aims at predicting the outcome by introducing a change of the preconditions, which is reflected in a variable called the predictor. The change in the predictor is generally hypothesized to result in a change in the second variable, hence called the outcome variable. Experimental design involves not only the selection of suitable predictors and outcomes, but planning the delivery of the experiment under statistically optimal conditions given the constraints of available resources.
在最简单的形式中,实验旨在通过引入先决条件的变化来预测结果,这反映在一个称为预测器的变量中。通常假设预测因子的变化会导致第二个变量的变化,因此称为结果变量。实验设计不仅包括选择合适的预测因子和结果,还包括在已知可用资源约束的统计最优条件下规划实验的交付。
Main concerns in experimental design include the establishment of validity, reliability, and replicability. For example, these concerns can be partially addressed by carefully choosing the predictor, reducing the risk of measurement error, and ensuring that the documentation of the method is sufficiently detailed. Related concerns include achieving appropriate levels of statistical power and sensitivity.
Correctly designed experiments advance knowledge in the natural and social sciences and engineering. Other applications include marketing and policy making.
正确设计的实验提高了自然科学、社会科学和工程方面的知识。其他应用包括营销和政策制定。
History (历史)
Systematic clinical trials(系统临床试验)
In 1747, while serving as surgeon on HMS Salisbury, James Lind carried out a systematic clinical trial to compare remedies for scurvy.[1] This systematic clinical trial constitutes a type of DOE.[citation needed][dubious – discuss]
1747年,詹姆斯·林德(James Lind)在英国皇家海军索尔兹伯里号(HMS Salisbury)担任外科医生期间,进行了一项系统的临床试验,以比较坏血病的治疗方法。[1] 这项系统的临床试验构成了一种DOE。[需要引用][可疑-讨论]
Lind selected 12 men from the ship, all suffering from scurvy. Lind limited his subjects to men who “were as similar as I could have them”, that is he provided strict entry requirements to reduce extraneous variation. He divided them into six pairs, giving each pair different supplements to their basic diet for two weeks. The treatments were all remedies that had been proposed:
林德从船上挑选了12名男子,他们都患有坏血病。林德将他的研究对象限制在“尽可能相似”的男性身上,也就是说,他提供了严格的进入要求,以减少外来变异。他将他们分为六对,在两周的时间里为每一对提供不同的基本饮食补充剂。这些治疗方法都是已经提出的补救措施:
A quart of cider every day.
每天一夸脱苹果酒。
Twenty five gutts (drops) of vitriol (sulphuric acid) three times a day upon an empty stomach.
每天空腹服三次硫酸,每次25滴。
One half-pint of seawater every day.
每天喝半品脱海水。
A mixture of garlic, mustard, and horseradish in a lump the size of a nutmeg.
一种大蒜、芥末和辣根的混合物,大小像肉豆蔻。
Two spoonfuls of vinegar three times a day.
每天三次,每次两勺醋。
Two oranges and one lemon every day.
每天两个橙子和一个柠檬。
The citrus treatment stopped after six days when they ran out of fruit, but by that time one sailor was fit for duty while the other had almost recovered. Apart from that, only group one (cider) showed some effect of its treatment. The remainder of the crew presumably served as a control, but Lind did not report results from any control (untreated) group.
柑橘的治疗在六天后停止,因为水果用完了,但到那时,一名水手已经能胜任工作,而另一名几乎已经康复。除此之外,只有第一组(苹果酒)表现出一定的治疗效果。其余船员可能作为对照,但林德没有报告任何对照组(未经治疗)的结果。
Statistical experiments, following Charles S. Peirce
统计实验,根据查尔斯·S·皮尔斯
Main article: Frequentist statistics
主要文章:频率派统计
See also: Randomization
另见:随机化
A theory of statistical inference was developed by Charles S. Peirce in “Illustrations of the Logic of Science” (1877–1878) and “A Theory of Probable Inference” (1883), two publications that emphasized the importance of randomization-based inference in statistics.
查尔斯·S·皮尔斯(Charles S.Peirce)在《科学逻辑图解》(1877–1878)和《概率推理理论》(1883)中提出了一种统计推理理论,这两份出版物强调了统计学中基于随机化的推理的重要性。
Randomized experiments
随机实验
Main article: Random assignment
主要文章:随机分配
See also: Repeated measures design
另见:重复测量设计
Charles S. Peirce randomly assigned volunteers to a blinded, repeated-measures design to evaluate their ability to discriminate weights.[2][3][4][5] Peirce’s experiment inspired other researchers in psychology and education, which developed a research tradition of randomized experiments in laboratories and specialized textbooks in the 1800s.[2][3][4][5]
查尔斯·S·皮尔斯随机分配志愿者进行盲法重复测量设计,以评估他们辨别体重的能力。[2] [3][4][5]皮尔斯的实验启发了心理学和教育领域的其他研究人员,他们在19世纪发展了在实验室和专业教科书中进行随机实验的研究传统。[2][3][4][5]
Optimal designs for regression models
回归模型的最优设计
Main article: Response surface methodology
主要文章:响应面方法
See also: Optimal design
另见:优化设计
Charles S. Peirce also contributed the first English-language publication on an optimal design for regression models in 1876.[6] A pioneering optimal design for polynomial regression was suggested by Gergonne in 1815. In 1918 Kirstine Smith published optimal designs for polynomials of degree six (and less).
查尔斯·S·皮尔斯还在1876年出版了第一本关于回归模型优化设计的英文出版物。[6] 1815年,Gergonne提出了多项式回归的开创性优化设计。1918年,Kirstine Smith发表了六次(及以下)多项式的优化设计。
Sequences of experiments
实验顺序
Main article: Sequential analysis
主要文章:序列分析
See also: Multi-armed bandit problem, Gittins index, and Optimal design
另请参见:多武装匪徒问题、Gittins索引和优化设计
The use of a sequence of experiments, where the design of each may depend on the results of previous experiments, including the possible decision to stop experimenting, is within the scope of Sequential analysis, a field that was pioneered[7] by Abraham Wald in the context of sequential tests of statistical hypotheses.[8] Herman Chernoff wrote an overview of optimal sequential designs,[9] while adaptive designs have been surveyed by S. Zacks.[10] One specific type of sequential design is the “two-armed bandit”, generalized to the multi-armed bandit, on which early work was done by Herbert Robbins in 1952.[11]
使用一系列实验,其中每个实验的设计可能取决于之前实验的结果,包括停止实验的可能决定,属于顺序分析的范围,这是亚伯拉罕·瓦尔德[7]在统计假设的顺序测试背景下开创的一个领域。[8] 赫尔曼·切尔诺夫(Herman Chernoff)撰写了最佳顺序设计概述[9],而S.Zacks则对自适应设计进行了调查。[10] 顺序设计的一种特殊类型是“双臂赌博机”,它被推广到多臂赌博机,赫伯特·罗宾斯(Herbert Robbins)在1952年对其进行了早期研究。[11]
Fisher’s principles
费希尔原理
A methodology for designing experiments was proposed by Ronald Fisher, in his innovative books: The Arrangement of Field Experiments (1926) and The Design of Experiments (1935). Much of his pioneering work dealt with agricultural applications of statistical methods. As a mundane example, he described how to test the lady tasting tea hypothesis, that a certain lady could distinguish by flavour alone whether the milk or the tea was first placed in the cup. These methods have been broadly adapted in the physical and social sciences, are still used in agricultural engineering and differ from the design and analysis of computer experiments.
罗纳德·费希尔(Ronald Fisher)在他的创新著作《野外实验的安排》(1926)和《实验的设计》(1935)中提出了一种设计实验的方法。他的许多开创性工作涉及统计方法的农业应用。作为一个平凡的例子,他描述了如何检验女士品茶假说,某位女士仅凭味道就能分辨出是牛奶还是茶先放在杯子里。这些方法已在物理和社会科学中得到广泛应用,仍在农业工程中使用,并与计算机实验的设计和分析不同。
Comparison 比较
In some fields of study it is not possible to have independent measurements to a traceable metrology standard. Comparisons between treatments are much more valuable and are usually preferable, and often compared against a scientific control or traditional treatment that acts as baseline.
在某些研究领域,不可能对可追溯的计量标准进行独立测量。治疗之间的比较更有价值,而且通常更可取,并且经常与作为基线的科学对照或传统治疗进行比较。
Randomization 随机性
Random assignment is the process of assigning individuals at random to groups or to different groups in an experiment, so that each individual of the population has the same chance of becoming a participant in the study. The random assignment of individuals to groups (or conditions within a group) distinguishes a rigorous, “true” experiment from an observational study or “quasi-experiment”.[12] There is an extensive body of mathematical theory that explores the consequences of making the allocation of units to treatments by means of some random mechanism such as tables of random numbers, or the use of randomization devices such as playing cards or dice. Assigning units to treatments at random tends to mitigate confounding, which makes effects due to factors other than the treatment to appear to result from the treatment. The risks associated with random allocation (such as having a serious imbalance in a key characteristic between a treatment group and a control group) are calculable and hence can be managed down to an acceptable level by using enough experimental units. However, if the population is divided into several subpopulations that somehow differ, and the research requires each subpopulation to be equal in size, stratified sampling can be used. In that way, the units in each subpopulation are randomized, but not the whole sample. The results of an experiment can be generalized reliably from the experimental units to a larger statistical population of units only if the experimental units are a random sample from the larger population; the probable error of such an extrapolation depends on the sample size, among other things.
随机分配是将个体随机分配到实验组或不同组的过程,这样每个个体都有相同的机会成为研究的参与者。将个体随机分配到群体(或群体内的条件)将严格的“真实”实验与观察性研究或“准实验”区分开来。[12]有大量的数学理论探讨了通过一些随机机制(如随机数表)或使用随机设备(如扑克牌或骰子)将单位分配给治疗的后果。随机分配治疗单元有助于减轻混淆,这使得治疗以外的因素产生的影响似乎是治疗的结果。与随机分配相关的风险(例如治疗组和对照组之间的关键特征严重失衡)是可计算的,因此可以通过使用足够的实验装置将其控制在可接受的水平。然而,如果将人口分为几个不同的亚群体,并且研究要求每个亚群体的规模相等,则可以使用分层抽样。这样一来,每个亚群中的单位是随机的,而不是整个样本。只有当实验单元是来自较大总体的随机样本时,才能可靠地将实验结果从实验单元推广到较大的统计总体;这种推断的可能误差取决于样本量等因素。
Statistical replication 统计复制
Measurements are usually subject to variation and measurement uncertainty; thus they are repeated and full experiments are replicated to help identify the sources of variation, to better estimate the true effects of treatments, to further strengthen the experiment’s reliability and validity, and to add to the existing knowledge of the topic.[13] However, certain conditions must be met before the replication of the experiment is commenced: the original research question has been published in a peer-reviewed journal or widely cited, the researcher is independent of the original experiment, the researcher must first try to replicate the original findings using the original data, and the write-up should state that the study conducted is a replication study that tried to follow the original study as strictly as possible.[14]
Blocking 分块
Blocking is the arrangement of experimental units into groups (blocks/lots) consisting of units that are similar to one another. Blocking reduces known but irrelevant sources of variation between units and thus allows greater precision in the estimation of the source of variation under study.
分块是将实验单元分成组(块/批次),由彼此相似的单元组成。阻断减少了单位间已知但不相关的变异源,因此可以更精确地估计研究中的变异源。
Orthogonality 正交性
Orthogonality concerns the forms of comparison (contrasts) that can be legitimately and efficiently carried out. Contrasts can be represented by vectors and sets of orthogonal contrasts are uncorrelated and independently distributed if the data are normal. Because of this independence, each orthogonal treatment provides different information to the others. If there are T treatments and T – 1 orthogonal contrasts, all the information that can be captured from the experiment is obtainable from the set of contrasts.
正交性涉及可以合法有效地进行的比较(对比)形式。对比度可以用向量表示,如果数据正常,正交对比度集是不相关且独立分布的。由于这种独立性,每个正交处理向其他正交处理提供不同的信息。如果存在T处理和T–1正交对比,则可以从对比集合中获得从实验中获取的所有信息。
Factorial experiments(析因试验)
Use of factorial experiments instead of the one-factor-at-a-time method. These are efficient at evaluating the effects and possible interactions of several factors (independent variables). Analysis of experiment design is built on the foundation of the analysis of variance, a collection of models that partition the observed variance into components, according to what factors the experiment must estimate or test.
使用析因实验,而不是一次一个因素的方法。这些方法可以有效地评估多个因素(自变量)的影响和可能的相互作用。实验设计的分析是建立在方差分析的基础上的,该模型是根据实验必须估计或测试的因素,将观察到的方差划分为组分的模型。
Example(案例)
This example is attributed to Harold Hotelling.[9] It conveys some of the flavor of those aspects of the subject that involve combinatorial designs.
这个例子由哈罗德·霍特林(Harold Hotelling)所做。[9] 其中涉及组合设计的主题。
Weights of eight objects are measured using a pan balance and set of standard weights. Each weighing measures the weight difference between objects in the left pan vs. any objects in the right pan by adding calibrated weights to the lighter pan until the balance is in equilibrium. Each measurement has a random error. The average error is zero; the standard deviations of the probability distribution of the errors is the same number σ on different weighings; and errors on different weighings are independent. Denote the true weights byθ1,……θ8.We consider two different experiments:
使用天平和一组标准砝码测量八个物体的重量。每次称重都会通过向较轻的盘中添加校准砝码来测量左盘中的物体与右盘中任何物体之间的重量差,直到天平处于平衡状态。每个测量值都有一个随机误差。平均误差为零;不同权重下误差概率分布的标准差为相同数σ;不同重量的误差是独立的。用θ1,…θ8表示真实权重。我们考虑两个不同的实验:
Weigh each object in one pan, with the other pan empty. Let Xi be the measured weight of the ith object, for i = 1, …, 8.
在一个盘中称量每个物体,另一个盘为空。设“Xi”为第i个物体的测量重量,其中i=1。。。,8.
Do the eight weighings according to the following schedule and let Yi be the measured difference for i = 1, …, 8:
按照以下计划进行八次称重,并将“Yi”作为i=1……8的测量差值:
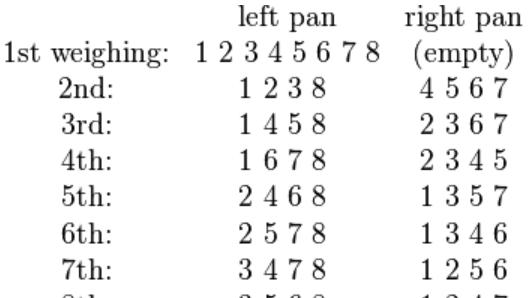
Then the estimated value of the weight θ1 is
那么权重θ1的估计值为
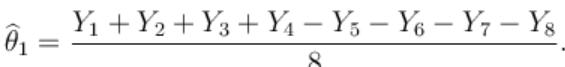
Similar estimates can be found for the weights of the other items. Forexample
其他的权重也有类似的估计。例如
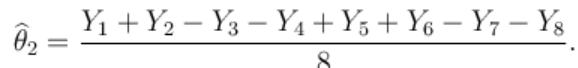
The question of design of experiments is: which experiment is better?
实验设计的问题是:哪个实验更好?
The variance of the estimate X1 of θ1 is σ2 if we use the first experiment. But if we use the second experiment, the variance of the estimate given above is σ2/8. Thus the second experiment gives us 8 times as much precision for the estimate of a single item, and estimates all items simultaneously, with the same precision. What the second experiment achieves with eight would require 64 weighings if the items are weighed separately. However, note that the estimates for the items obtained in the second experiment have errors that correlate with each other.
如果我们使用第一个实验,θ1的估计值“X1”的方差是σ2。但是如果我们使用第二个实验,上面给出的估计的方差是σ2/8。因此,第二个实验为我们提供了8倍于单个项目估计精度的结果,并且以相同的精度同时估计了所有项目。第二个实验用八个物体完成,如果这些物体分开称重,则需要64次称重。然而,请注意,在第二个实验中获得的项目估计值存在相互关联的误差。
Many problems of the design of experiments involve combinatorial designs, as in this example and others.[15]
实验设计的许多问题都涉及组合设计,如本例和其他例子。[15]
Avoiding false positives 避免误报
False positive conclusions, often resulting from the pressure to publish or the author’s own confirmation bias, are an inherent hazard in many fields. A good way to prevent biases potentially leading to false positives in the data collection phase is to use a double-blind design. When a double-blind design is used, participants are randomly assigned to experimental groups but the researcher is unaware of what participants belong to which group. Therefore the researcher can not affect the participants’ response to the intervention. Experimental designs with undisclosed degrees of freedom are a problem.[16] This can lead to conscious or unconscious “p-hacking”: trying multiple things until you get the desired result. It typically involves the manipulation – perhaps unconsciously – of the process of statistical analysis and the degrees of freedom until they return a figure below the p<.05 level of statistical significance.[17][18] So the design of the experiment should include a clear statement proposing the analyses to be undertaken. P-hacking can be prevented by preregistering researches, in which researchers have to send their data analysis plan to the journal they wish to publish their paper in before they even start their data collection, so no data mining is possible (https://osf.io). Another way to prevent this is taking the double-blind design to the data-analysis phase, where the data are sent to a data-analyst unrelated to the research who scrambles up the data so there is no way to know which participants belong to before they are potentially taken away as outliers.
Clear and complete documentation of the experimental methodology is also important in order to support replication of results.[19]
为了支持结果的复制,清晰完整的实验方法记录也很重要。[19]
Discussion topics when setting up an experimental design
设置实验设计时的讨论主题
An experimental design or randomized clinical trial requires careful consideration of several factors before actually doing the experiment.[20] An experimental design is the laying out of a detailed experimental plan in advance of doing the experiment. Some of the following topics have already been discussed in the principles of experimental design section:
实验设计或随机临床试验需要在实际进行实验之前仔细考虑几个因素。[20] 实验设计是在进行实验之前制定详细的实验计划。以下一些主题已经在“实验设计原则”一节中讨论过:
How many factors does the design have? and are the levels of these factors fixed or random?
设计有多少因素?这些因素的水平是固定的还是随机的?
Are control conditions needed, and what should they be?
是否需要控制条件,它们应该是什么?
Manipulation checks; did the manipulation really work?
操纵检查;操纵真的有效吗?
What are the background variables?
背景变量是什么?
What is the sample size. How many units must be collected for the experiment to be generalisable and have enough power?
样本量是多少。为了使实验具有通用性和足够的能量,必须收集多少个单位?
What is the relevance of interactions between factors?
因素之间相互作用的相关性是什么?
What is the influence of delayed effects of substantive factors on outcomes?
实质性因素的延迟效应对结果有什么影响?
How do response shifts affect self-report measures?
反应变化如何影响自我报告测量?
How feasible is repeated administration of the same measurement instruments to the same units at different occasions, with a post-test and follow-up tests?
在不同的情况下,对同一装置重复使用相同的测量仪器,并进行后测和后续测试,其可行性如何?
What about using a proxy pretest?
使用代理预测试怎么样?
Are there lurking variables?
是否存在潜在的变量?
Should the client/patient, researcher or even the analyst of the data be blind to conditions?
客户/患者、研究人员甚至数据分析师是否应该对情况视而不见?
What is the feasibility of subsequent application of different conditions to the same units?
对同一装置随后应用不同条件的可行性是什么?
How many of each control and noise factors should be taken into account?
每种控制和噪声因素应考虑多少?
The independent variable of a study often has many levels or different groups. In a true experiment, researchers can have an experimental group, which is where their intervention testing the hypothesis is implemented, and a control group, which has all the same element as the experimental group, without the interventional element. Thus, when everything else except for one intervention is held constant, researchers can certify with some certainty that this one element is what caused the observed change. In some instances, having a control group is not ethical. This is sometimes solved using two different experimental groups. In some cases, independent variables are not manipulable, for example when testing the difference between two groups who have a different disease, or testing the difference between genders (obviously variables that would be hard or unethical to assign participants to). In these cases, a quasi-experimental design may be used.
一项研究的自变量通常有多个层次或不同的群体。在一个真正的实验中,研究人员可以有一个实验组,在那里实施他们的干预测试假设,还有一个控制组,与实验组有相同的元素,没有干预元素。因此,当除一种干预措施外的所有其他因素保持不变时,研究人员可以确定地证明,这一因素是导致观察到的变化的原因。在某些情况下,有一个对照组是不道德的。有时可以通过两个不同的实验组来解决这个问题。在某些情况下,自变量是不可操作的,例如,在测试患有不同疾病的两组之间的差异时,或在测试性别之间的差异时(显然,很难或不道德地将参与者分配给变量)。在这些情况下,可以使用准实验设计。
Causal attributions 因果归因
In the pure experimental design, the independent (predictor) variable is manipulated by the researcher – that is – every participant of the research is chosen randomly from the population, and each participant chosen is assigned randomly to conditions of the independent variable. Only when this is done is it possible to certify with high probability that the reason for the differences in the outcome variables are caused by the different conditions. Therefore, researchers should choose the experimental design over other design types whenever possible. However, the nature of the independent variable does not always allow for manipulation. In those cases, researchers must be aware of not certifying about causal attribution when their design doesn’t allow for it. For example, in observational designs, participants are not assigned randomly to conditions, and so if there are differences found in outcome variables between conditions, it is likely that there is something other than the differences between the conditions that causes the differences in outcomes, that is – a third variable. The same goes for studies with correlational design. (Adér & Mellenbergh, 2008).
在纯实验设计中,独立(预测)变量由研究者操纵——也就是说,研究的每个参与者都是从人群中随机选择的,每个被选择的参与者都被随机分配到独立变量的条件下。只有这样,才有可能高概率证明结果变量差异的原因是由不同的条件引起的。因此,研究人员应尽可能选择实验设计而非其他设计类型。然而,自变量的性质并不总是允许操纵。在这些情况下,研究人员必须意识到,当他们的设计不允许因果归因时,他们不能证明因果归因。例如,在观察设计中,参与者不是随机分配到不同的条件下,因此,如果在不同条件下的结果变量存在差异,那么很可能是条件之间的差异以外的其他因素导致了结果的差异,即第三个变量。相关设计的研究也是如此。(Adér&Mellenbergh,2008年)。
Statistical control 统计控制
It is best that a process be in reasonable statistical control prior to conducting designed experiments. When this is not possible, proper blocking, replication, and randomization allow for the careful conduct of designed experiments.[21] To control for nuisance variables, researchers institute control checks as additional measures. Investigators should ensure that uncontrolled influences (e.g., source credibility perception) do not skew the findings of the study. A manipulation check is one example of a control check. Manipulation checks allow investigators to isolate the chief variables to strengthen support that these variables are operating as planned.
One of the most important requirements of experimental research designs is the necessity of eliminating the effects of spurious, intervening, and antecedent variables. In the most basic model, cause (X) leads to effect (Y). But there could be a third variable (Z) that influences (Y), and X might not be the true cause at all. Z is said to be a spurious variable and must be controlled for. The same is true for intervening variables (a variable in between the supposed cause (X) and the effect (Y)), and anteceding variables (a variable prior to the supposed cause (X) that is the true cause). When a third variable is involved and has not been controlled for, the relation is said to be a zero order[disambiguation needed] relationship. In most practical applications of experimental research designs there are several causes (X1, X2, X3). In most designs, only one of these causes is manipulated at a time.
实验研究设计最重要的要求之一是消除虚假、干预和先行变量的影响。在最基本的模型中,原因(X)导致结果(Y)。但可能还有第三个变量(Z)影响(Y),而X可能根本不是真正的原因。Z被认为是一个伪变量,因此必须对其进行控制。干预变量(假设原因(X)和影响(Y)之间的变量)和先行变量(假设原因(X)之前的变量,即真正原因)也是如此。当涉及第三个变量且未进行控制时,该关系称为零阶[需要消歧]关系。关系在实验研究设计的大多数实际应用中,有几个原因(X1、X2、X3)。在大多数设计中,一次只能操纵其中一个原因。
Experimental designs after Fisher
费希尔之后的实验设计
Some efficient designs for estimating several main effects were found independently and in near succession by Raj Chandra Bose and K. Kishen in 1940 at the Indian Statistical Institute, but remained little known until the Plackett-Burman designs were published in Biometrika in 1946. About the same time, C. R. Rao introduced the concepts of orthogonal arrays as experimental designs. This concept played a central role in the development of Taguchi methods by Genichi Taguchi, which took place during his visit to Indian Statistical Institute in early 1950s. His methods were successfully applied and adopted by Japanese and Indian industries and subsequently were also embraced by US industry albeit with some reservations.
1940年,拉杰·钱德拉·博斯(Raj Chandra Bose)和K.基申(K.Kishen)在印度统计研究所(Indian Statistical Institute)独立地、几乎连续地发现了一些用于估计几种主要效应的有效设计,但直到1946年Plackett-Burman设计在Biometrika上发表之前,人们对这些设计知之甚少。大约在同一时间,C.R.Rao(劳,印度裔统计学大师)将正交表的概念引入实验设计。这一概念在田口玄一 (Genichi Taguchi)开发田口方法的过程中起到了核心作用,田口玄一 (Genichi Taguchi)在1950年代初访问印度统计研究所期间开发了田口法。他的方法被日本和印度工业成功地应用和采用,随后也被美国工业所接受,尽管有些保留意见。
In 1950, Gertrude Mary Cox and William Gemmell Cochran published the book Experimental Designs, which became the major reference work on the design of experiments for statisticians for years afterwards.
1950年,格特鲁德·玛丽·考克斯(Gertrude Mary Cox)和威廉·杰梅尔·科克伦(William Gemmell Cochran)出版了《实验设计》一书,这本书后来成为统计学家设计实验的主要参考书。
Developments of the theory of linear models have encompassed and surpassed the cases that concerned early writers. Today, the theory rests on advanced topics in linear algebra, algebra and combinatorics.
As with other branches of statistics, experimental design is pursued using both frequentist and Bayesian approaches: In evaluating statistical procedures like experimental designs, frequentist statistics studies the sampling distribution while Bayesian statistics updates a probability distribution on the parameter space.
与统计学的其他分支一样,实验设计采用了频率统计和贝叶斯方法:在评估实验设计等统计程序时,频率统计研究抽样分布,而贝叶斯统计更新参数空间上的概率分布。
Some important contributors to the field of experimental designs are C. S. Peirce, R. A. Fisher, F. Yates, C. R. Rao, R. C. Bose, J. N. Srivastava, Shrikhande S. S., D. Raghavarao, W. G. Cochran, O. Kempthorne, W. T. Federer, V. V. Fedorov, A. S. Hedayat, J. A. Nelder, R. A. Bailey, J. Kiefer, W. J. Studden, A. Pázman, F. Pukelsheim, D. R. Cox, H. P. Wynn, A. C. Atkinson, G. E. P. Box and G. Taguchi.[citation needed] The textbooks of D. Montgomery and R. Myers have reached generations of students and practitioners.[22] [23] [24]
对实验设计领域做出重要贡献的有C.S.皮尔斯、R.A.费舍尔、F.耶茨、C.R.拉奥、R.C.Bose、J.N.斯利瓦斯塔瓦、施里坎德·S.S、D.拉格瓦拉奥、W.G.科克伦、O.坎普托恩、W.T.费德勒、V.费多洛夫、A.S.赫达亚特、J.A.内尔德、R.A.贝利、J.基弗、W.J.斯图登、A.Pázman、F.Pukelsheim、D.R.考克斯、金森、,G.E.P.Box和G.Taguchi。【需要引证】蒙哥马利和迈尔斯的教科书已经惠及了一代又一代的学生和实践者。[22] [23] [24]
Human participant experimental design constraints
人类参与者实验设计约束
Laws and ethical considerations preclude some carefully designed experiments with human subjects. Legal constraints are dependent on jurisdiction. Constraints may involve institutional review boards, informed consent and confidentiality affecting both clinical (medical) trials and behavioral and social science experiments.[25] In the field of toxicology, for example, experimentation is performed on laboratory animals with the goal of defining safe exposure limits for humans.[26] Balancing the constraints are views from the medical field.[27] Regarding the randomization of patients, “… if no one knows which therapy is better, there is no ethical imperative to use one therapy or another.” (p 380) Regarding experimental design, “…it is clearly not ethical to place subjects at risk to collect data in a poorly designed study when this situation can be easily avoided…”. (p 393)
法律和伦理考虑排除了一些精心设计的人体实验。法律约束取决于管辖权。制约因素可能涉及机构审查委员会、知情同意和保密,影响临床(医学)试验以及行为和社会科学实验。[25]例如,在毒理学领域,实验是在实验动物身上进行的,目的是确定人类的安全接触限值。[26]平衡这些限制是来自医学领域的观点。[27]关于患者的随机化,“……如果没有人知道哪种疗法更好,就没有必要使用一种或另一种疗法。”(第380页)关于实验设计,“……当这种情况很容易避免时,让受试者在设计不良的研究中收集数据,显然是不道德的……”。(第393页)
参考文献:
Dunn, Peter (January 1997). “James Lind (1716-94) of Edinburgh and the treatment of scurvy”. Archive of Disease in Childhood Foetal Neonatal. United Kingdom: British Medical Journal Publishing Group. 76 (1): 64–65. doi:10.1136/fn.76.1.F64. PMC 1720613. PMID 9059193. Retrieved 17 January 2009.
Peirce, Charles Sanders; Jastrow, Joseph (1885). “On Small Differences in Sensation”. Memoirs of the National Academy of Sciences. 3: 73–83.
Hacking, Ian (September 1988). “Telepathy: Origins of Randomization in Experimental Design”. Isis. 79 (3): 427–451. doi:10.1086/354775. JSTOR 234674. MR 1013489
Stephen M. Stigler (November 1992). “A Historical View of Statistical Concepts in Psychology and Educational Research”. American Journal of Education. 101 (1): 60–70. doi:10.1086/444032. JSTOR 1085417.
Trudy Dehue (December 1997). “Deception, Efficiency, and Random Groups: Psychology and the Gradual Origination of the Random Group Design”. Isis. 88 (4): 653–673. doi:10.1086/383850. PMID 9519574.
Peirce, C. S. (1876). “Note on the Theory of the Economy of Research”. Coast Survey Report: 197–201.actually published 1879, NOAA PDF Eprint.Reprinted in Collected Papers 7, paragraphs 139–157, also in Writings 4, pp. 72–78, and in Peirce, C. S. (July–August 1967). “Note on the Theory of the Economy of Research”. Operations Research. 15 (4): 643–648. doi:10.1287/opre.15.4.643. JSTOR 168276.CS1 maint: multiple names: authors list
Johnson, N.L. (1961). “Sequential analysis: a survey.” Journal of the Royal Statistical Society, Series A. Vol. 124 (3), 372–411. (pages 375–376)
Wald, A. (1945) “Sequential Tests of Statistical Hypotheses”, Annals of Mathematical Statistics, 16 (2), 117–186.
Herman Chernoff, Sequential Analysis and Optimal Design, SIAM Monograph, 1972.
Zacks, S. (1996) “Adaptive Designs for Parametric Models”. In: Ghosh, S. and Rao, C. R., (Eds) (1996). “Design and Analysis of Experiments,” Handbook of Statistics, Volume 13. North-Holland. ISBN 0-444-82061-2. (pages 151–180)
Robbins, H. (1952). “Some Aspects of the Sequential Design of Experiments”. Bulletin of the American Mathematical Society. 58 (5): 527–535. doi:10.1090/S0002-9904-1952-09620-8.
Creswell, J.W. (2008). Educational research: Planning, conducting, and evaluating quantitative and qualitative research (3rd). Upper Saddle River, NJ: Prentice Hall. 2008, p. 300. ISBN 0-13-613550-1
Dr. Hani (2009). “Replication study”. Retrieved 27 October 2011.
Burman, Leonard E.; Robert W. Reed; James Alm (2010). “A call for replication studies” (journal article). Public Finance Review. pp. 787–793. doi:10.1177/1091142110385210. Retrieved 27 October 2011.
Jack Sifri (8 December 2014). “How to Use Design of Experiments to Create Robust Designs With High Yield”. youtube.com. Retrieved 11 February 2015.
Simmons, Joseph; Leif Nelson; Uri Simonsohn (November 2011). “False-Positive Psychology: Undisclosed Flexibility in Data Collection and Analysis Allows Presenting Anything as Significant”. Psychological Science. Washington DC: Association for Psychological Science. 22 (11): 1359–1366. doi:10.1177/0956797611417632. ISSN 0956-7976. PMID 22006061. Retrieved 29 January 2012.
“Science, Trust And Psychology In Crisis”. KPLU. 2 June 2014. Retrieved 12 June 2014.
“Why Statistically Significant Studies Can Be Insignificant”. Pacific Standard. 4 June 2014. Retrieved 12 June 2014.
Chris Chambers (10 June 2014). “Physics envy: Do ‘hard’ sciences hold the solution to the replication crisis in psychology?”. theguardian.com. Retrieved 12 June 2014.
Ader, Mellenberg & Hand (2008) “Advising on Research Methods: A consultant’s companion”
Bisgaard, S (2008) “Must a Process be in Statistical Control before Conducting Designed Experiments?”, Quality Engineering, ASQ, 20 (2), pp 143 – 176
Montgomery, Douglas (2013). Design and analysis of experiments (8th ed.). Hoboken, NJ: John Wiley & Sons, Inc. ISBN 9781118146927.
Walpole, Ronald E.; Myers, Raymond H.; Myers, Sharon L.; Ye, Keying (2007). Probability & statistics for engineers & scientists (8 ed.). Upper Saddle River, NJ: Pearson Prentice Hall. ISBN 978-0131877115.
Myers, Raymond H.; Montgomery, Douglas C.; Vining, G. Geoffrey; Robinson, Timothy J. (2010). Generalized linear models : with applications in engineering and the sciences (2 ed.). Hoboken, N.J: Wiley. ISBN 978-0470454633.
Moore, David S.; Notz, William I. (2006). Statistics : concepts and controversies (6th ed.). New York: W.H. Freeman. pp. Chapter 7: Data ethics. ISBN 9780716786368.
Ottoboni, M. Alice (1991). The dose makes the poison : a plain-language guide to toxicology (2nd ed.). New York, N.Y: Van Nostrand Reinhold. ISBN 0442006608.
Glantz, Stanton A. (1992). Primer of biostatistics (3rd ed.). ISBN 0-07-023511-2.