小时候的你在游戏中搓着手柄,在现实中是否也会模仿这《拳皇》的动作?用身体控制游戏角色的体感游戏很早就已出现,但需要体感手柄(Wii)或体感摄像头(微软Kinect)配合。而现在,笔记本就能帮你做到这一切!
最近,有一位名叫Minko Gechev的软件工程师实现了在笔记本上玩《真人快打》(Mortal Kombat),只需要一颗前置摄像头即可。

早在5年前,他就曾展示过体感玩格斗游戏的项目成果:
当时实现方案很简单,也没有利用时下流行的AI技术。但是这套算法离完美还相去甚远,因为需要单色画面背景作为参照,使用条件苛刻。
5年间,无论是网络浏览器的API,还是WebGL都有了长足的发展。于是这名工程师决定用TensorFlow.js来改进他的游戏程序,并在他个人Blog上放出了完整教程。
量子位对文章做了编译整理,主要内容是训练模型识别《真人快打》这款游戏主要有拳击、踢腿两种动作,并通过模型输出结果控制游戏人物做出对应动作。
以下就是他Blog的主要内容:
简介
我将分享用TensorFlow.js和MobileNet创建动作分类算法的一些经验,全文将分为以下几部分:
为图片分类收集数据
使用imgaug进行数据增强
使用MobileNet迁移学习
二元分类和N元分类
在浏览器中使用TensorFlow.js模型训练图片分类
简单讨论使用LSTM进行动作分类
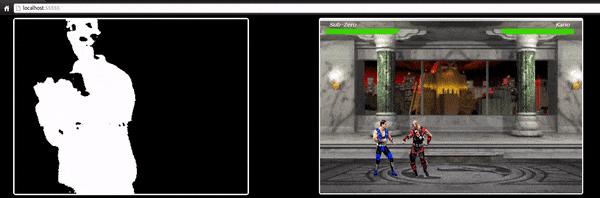
我们将开发一种监督深度学习模型,利用笔记本摄像头获取的图像来分辨用户是在出拳、出腿或者没有任何动作。最终演示效果如下图:

理解本文内容需要有基本的软件工程和JavaScript知识。如果你有一些基本的深度学习知识会很有帮助,但非硬性要求。
收集数据
深度学习模型的准确性在很大程度上取决于训练数据的质量。因此,我们首要的目标是建立一个丰富的训练数据集。
我们的模型需要识别人物的拳击和踢腿,所以应当从以下三个分类中收集图像:
拳击
踢腿
其他
为了这个实验,我找到两位志愿者帮我收集图像。我们总共录制了5段视频,每段都包含2-4个拳击动作和2-4个踢腿动作。由于收集到的是视频文件,我们还需要使用ffmpeg将之转化为一帧一帧的图片:
ffmpeg-ivideo.mov$filenamed.jpg
最终,在每个目录下,我们都收集了大约200张图片,如下:

注:除了拳击和踢腿外,图片目录中最多的是“其他”部分,主要是走动、转身、开关视频录制的一些画面。如果这部分内容太多,会有风险导致训练后的模型产生偏见,把应该归于前两类的图片划分到“其他”中,因此我们减少了这部分图片的量。
如果只使用这600张相同环境、相同人物的图片,我们将无法获得很高的准确度。为了进一步提高识别的准确度,我们将使用数据增强对样本进行扩充。
数据增强
数据增强是一种通过已有数据集合成新样本的技术,可以帮助我们增加数据集的样本量和多样性。我们可以将原始图片处理一下转变成新图,但处理过程不能太过激烈,好让机器能够对新图片正确归类。
np.random.seed(44)ia.seed(44)defmain():foriinrange(1,191):draw_single_sequential_images(str(i),”others”,”others-aug”)foriinrange(1,191):draw_single_sequential_images(str(i),”hits”,”hits-aug”)foriinrange(1,191):draw_single_sequential_images(str(i),”kicks”,”kicks-aug”)defdraw_single_sequential_images(filename,path,aug_path):image=misc.imresize(ndimage.imread(path “/” filename “.jpg”),(56,100))sometimes=lambdaaug:iaa.Sometimes(0.5,aug)seq=iaa.Sequential([iaa.Fliplr(0.5),#horizontallyflip50%ofallimages#cropimagesby-5%to10%oftheirheight/widthsometimes(iaa.CropAndPad(percent=(-0.05,0.1),pad_mode=ia.ALL,pad_cval=(0,255))),sometimes(iaa.Affine(scale={“x”:(0.8,1.2),”y”:(0.8,1.2)},#scaleimagesto80-120%oftheirsize,individuallyperaxistranslate_percent={“x”:(-0.1,0.1),”y”:(-0.1,0.1)},#translateby-10to 10percent(peraxis)rotate=(-5,5),shear=(-5,5),#shearby-5to 5degreesorder=[0,1],#usenearestneighbourorbilinearinterpolation(fast)cval=(0,255),#ifmodeisconstant,useacvalbetween0and255mode=ia.ALL#useanyofscikit-image’swarpingmodes(see2ndimagefromthetopforexamples))),iaa.Grayscale(alpha=(0.0,1.0)),iaa.Invert(0.05,per_channel=False),#invertcolorchannels#execute0to5ofthefollowing(lessimportant)augmentersperimage#don’texecuteallofthem,asthatwouldoftenbewaytoostrongiaa.SomeOf((0,5),[iaa.OneOf([iaa.GaussianBlur((0,2.0)),#blurimageswithasigmabetween0and2.0iaa.AverageBlur(k=(2,5)),#blurimageusinglocalmeanswithkernelsizesbetween2and5iaa.MedianBlur(k=(3,5)),#blurimageusinglocalmedianswithkernelsizesbetween3and5]),iaa.Sharpen(alpha=(0,1.0),lightness=(0.75,1.5)),#sharpenimagesiaa.Emboss(alpha=(0,1.0),strength=(0,2.0)),#embossimagesiaa.AdditiveGaussianNoise(loc=0,scale=(0.0,0.01*255),per_channel=0.5),#addgaussiannoisetoimagesiaa.Add((-10,10),per_channel=0.5),#changebrightnessofimages(by-10to10oforiginalvalue)iaa.AddToHueAndSaturation((-20,20)),#changehueandsaturation#eitherchangethebrightnessofthewholeimage(sometimes#perchannel)orchangethebrightnessofsubareasiaa.OneOf([iaa.Multiply((0.9,1.1),per_channel=0.5),iaa.FrequencyNoiseAlpha(exponent=(-2,0),first=iaa.Multiply((0.9,1.1),per_channel=True),second=iaa.ContrastNormalization((0.9,1.1)))]),iaa.ContrastNormalization((0.5,2.0),per_channel=0.5),#improveorworsenthecontrast],random_order=True)],random_order=True)im=np.zeros((16,56,100,3),dtype=np.uint8)forcinrange(0,16):im[c]=imageforiminrange(len(grid)):misc.imsave(aug_path “/” filename “_” str(im) “.jpg”,grid[im])
每张图片最后都被扩展成16张照片,考虑到后面训练和评估时的运算量,我们减小了图片体积,每张图的分辨率都被压缩成100*56。

建立模型
现在,我们开始建立图片分类模型。处理图片使用的是CNN(卷积神经网络),CNN适合于图像识别、物体检测和分类领域。
迁移学习
迁移学习允许我们使用已被训练过网络。我们可以从任何一层获得输出,并把它作为新的神经网络的输入。这样,训练新创建的神经网络能达到更高的认知水平,并且能将源模型从未见过的图片进行正确地分类。
在浏览器中运行模型
在这一部分,我们将训练一个二元分类模型。
首先,我们浏览器的游戏脚本MK.js中运行训练过的模型。代码如下:
constvideo=document.getElementById(‘cam’);constLayer=’global_average_pooling2d_1′;constmobilenetInfer=m=>(p):tf.Tensor<tf.Rank>=>m.infer(p,Layer);constcanvas=document.getElementById(‘canvas’);constscale=document.getElementById(‘crop’);constImageSize={Width:100,Height:56};navigator.mediaDevices.getUserMedia({video:true,audio:false}).then(stream=>{video.srcObject=stream;});
以上代码中一些变量和函数的注释:
video:页面中的HTML5视频元素
Layer:MobileNet层的名称,我们从中获得输出并把它作为我们模型的输入
mobilenetInfer:从MobileNet接受例子,并返回另一个函数。返回的函数接受输入,并从MobileNet特定层返回相关的输出
canvas:将取出的帧指向HTML5的画布
scale:压缩帧的画布
第二步,我们从摄像头获取视频流,作为视频元素的源。对获得的图像进行灰阶滤波,改变其内容:
constgrayscale=(canvas:HTMLCanvasElement)=>{constimageData=canvas.getContext(‘2d’).getImageData(0,0,canvas.width,canvas.height);constdata=imageData.data;for(leti=0;i<data.length;i =4){constavg=(data[i] data[i 1] data[i 2])/3;data[i]=avg;data[i 1]=avg;data[i 2]=avg;}canvas.getContext(‘2d’).putImageData(imageData,0,0);};
第三步,把训练过的模型和游戏脚本MK.js连接起来。
letmobilenet:(p:any)=>tf.Tensor<tf.Rank>;tf.loadModel(‘http://localhost:5000/model.json’).then(model=>{mobileNet.load().then((mn:any)=>mobilenet=mobilenetInfer(mn)).then(startInterval(mobilenet,model));});
在以上代码中,我们将MobileNet的输出传递给mobilenetInfer方法,从而获得了从网络的隐藏层中获得输出的快捷方式。此外,我还引用了startInterval。
conststartInterval=(mobilenet,model)=>()=>{setInterval(()=>{canvas.getContext(‘2d’).drawImage(video,0,0);grayscale(scale.getContext(‘2d’).drawImage(canvas,0,0,canvas.width,canvas.width/(ImageSize.Width/ImageSize.Height),0,0,ImageSize.Width,ImageSize.Height));const[punching]=Array.from((model.predict(mobilenet(tf.fromPixels(scale)))astf.Tensor1D).dataSync()asFloat32Array);constdetect=(windowasany).Detect;if(punching>=0.4)detect&&detect.onPunch();},100);};
startInterval正是关键所在,它每间隔100ms引用一个匿名函数。在这个匿名函数中,我们把视频当前帧放入画布中,然后压缩成100*56的图片后,再用于灰阶滤波器。
在下一步中,我们把压缩后的帧传递给MobileNet,之后我们将输出传递给训练过的模型,通过dataSync方法返回一个一维张量punching。
最后,我们通过punching来确定拳击的概率是否高于0.4,如果是,将调用onPunch方法,现在我们可以控制一种动作了:

用N元分类识别拳击和踢腿
在这部分,我们将介绍一个更智能的模型:使用神经网络分辨三种动作:拳击、踢腿和站立。
constpunches=require(‘fs’).readdirSync(Punches).filter(f=>f.endsWith(‘.jpg’)).map(f=>`${Punches}/${f}`);constkicks=require(‘fs’).readdirSync(Kicks).filter(f=>f.endsWith(‘.jpg’)).map(f=>`${Kicks}/${f}`);constothers=require(‘fs’).readdirSync(Others).filter(f=>f.endsWith(‘.jpg’)).map(f=>`${Others}/${f}`);constys=tf.tensor2d(newArray(punches.length).fill([1,0,0]).concat(newArray(kicks.length).fill([0,1,0])).concat(newArray(others.length).fill([0,0,1])),[punches.length kicks.length others.length,3]);constxs:tf.Tensor2D=tf.stack(punches.map((path:string)=>mobileNet(readInput(path))).concat(kicks.map((path:string)=>mobileNet(readInput(path)))).concat(others.map((path:string)=>mobileNet(readInput(path)))))astf.Tensor2D;
我们对压缩和灰阶化的图片调用MobileNet,之后将输出传递给训练过的模型。 该模型返回一维张量,我们用dataSync将其转换为一个数组。 下一步,通过使用Array.from我们将类型化数组转换为JavaScript数组,数组中包含我们提取帧中三种姿势的概率。
如果既不是踢腿也不是拳击的姿势的概率高于0.4,我们将返回站立不动。 否则,如果显示高于0.32的概率拳击,我们会向MK.js发出拳击指令。 如果踢腿的概率超过0.32,那么我们发出一个踢腿动作。
以下就是完整的演示效果:
动作识别
如果我们收集到更大的多样性数据集,那么我们搭建的模型就能更精确处理每一帧。但这样就够了吗?显然不是,请看以下两张图:

它们都是踢腿动作,但实际上在视频中有很大的不同,是两种不同的动作。

为了识别动作,我们还需要使用RNN(循环神经网络),RNN的优势在处理时间序列问题,比如
自然语言处理,词语的意思需要联系上下文
根据历史记录,预测用户将要访问的页面
识别一系列帧中的动作
若要识别动作,我们还需要将数帧画面输入CNN,再将输出结果输入RNN。
总结
在本文中,我们开发了一个图像分类模型。为此,我们手动提取视频帧并收集数据集,将它们分成三个不同的类别,然后使用imgaug进行数据增强。
之后,我们通过MobileNet来解释什么是迁移学习,以及我们如何利用MobileNet。经过训练,我们的模型达到了90%以上的准确率!
为了在浏览器中使用我们开发的模型,我们将它与MobileNet一起加载,并从用户的相机中每100ms取出一帧,识别用户的动作,并使用模型的输出来控制《真人快打3》中的角色。
最后,我们简单讨论了如何通过RNN来进一步改进我们的模型。
我希望你们能够和我一样喜欢这个小项目。
附录:
imgaug:https://github.com/aleju/imgaug
MobileNet神经网络:https://www.npmjs.com/package/@tensorflow-models/mobilenet
— 完 —
加入社群
此外,量子位专业细分群(自动驾驶、CV、NLP、机器学习等)正在招募,面向正在从事相关领域的工程师及研究人员。
活动策划招聘









