基本介绍
DE算法和GA算法的相同点:
(1)随机生成初始种群
(2)以种群中个体适应度值为选择标准
(3)主要过程包括变异、交叉、选择三个步骤
DE算法和GA算法的区别:
(1)DE算法的变异向量是由父代差分向量生成,与父代个体向量交叉生成新个体向量。
(2)新个体向量与父代个体一起进行选择。
差分进化算法尤其利于求解高维的函数优化问题。
基本差分进化算法
初始化:在差分进化算法研究中,一般假设所有初始化种群均符合均匀概率分布。
 如果可以预先得到问题的初步解,则初始化种群也可以通过对初步解加入正态分布随机偏差来产生,这样可以提高重建效果。
如果可以预先得到问题的初步解,则初始化种群也可以通过对初步解加入正态分布随机偏差来产生,这样可以提高重建效果。
变异:需要注意的地方是,下方所示公式中r1,r2,r3和向量序号i互不相同,所以必须保证NP>=4;变异算子 F 在[0 2]范围内,是一个实常数因数,它控制偏差变量的放大比例。

交叉:CR为交叉算子,其取值范围为[0,1]。

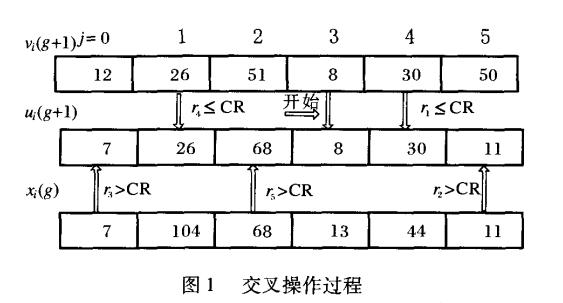
选择:为了决定试验向量 u是否会成为下一代中的成员,差分进化算法按照贪婪准则将试验向量与当前种群中的目标向量 x 进行比较。如果目标函数要被最小化,那么具有较小目标函数值的向量将在下一代种群中出现。下一代中的所有个体都比当前种群的对应个体更佳或者至少一样好。注意:在差分进化算法选择程序中,试验向量 u 只与一个个体相比较,而不是与现有种群中的所有个体相比较。
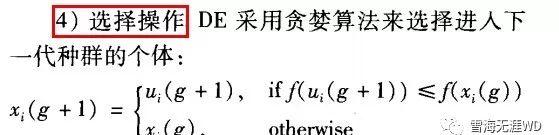
边界处理条件:在有边界约束的问题中,必须保证产生新个体的参数值位于问题的可行域中,一个简单的方法是将不符合边界约束的新个体用在可行域中随机产生的参数向量代替。另外一种方法是进行边界吸收处理,即将超过边界约束的个体值设置为临近的边界值。
测试函数:
Rastrigr函数:
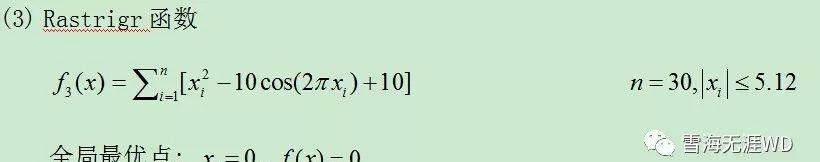
自适应差分进化算法:

离散差分进化算法:
差分进化算法采用浮点数编码,在连续空间进行优化计算,是一种求解实数变量优化问题的有效方法。要将差分进化算法用于求解整数规划或者混合整数规划问题,必须对差分进化算法进行改进。对于整数变量,可对差分进化算法变异操作中的差分矢量进行向下取整运算,从而保证整数变量直接在整数空间进行寻优,即
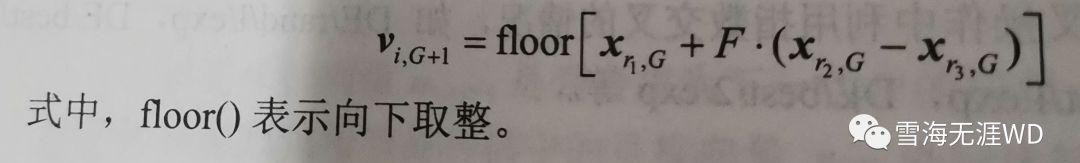
关键参数说明:
种群数量NP:种群数量,根据经验,种群数量NP的合理选择在5D~10D之间(D为变量的维数)。必须满足NP>=4,以确保差分进化算法具有足够的不同的变异向量
变异算子 F:变异算子([0,2]范围内)是一个实常数因数初始变异算子。它控制偏差变量的放大比例。F过小,则可能造成算法“早熟”。随着F的增大,防止算法陷入局部最优的能力增强,但当F>1时,想要算法快速收敛到最优值会变得十分不易;这是由于当差分向量的扰动大于两个个体之间的距离时,种群的收敛性会变得很差。目前的研究表明,F小于0.4和大于1的值仅偶尔有效,F = 0.5通常是一个较好的初始选择。若种群过早收敛,那么
F或NP应该增大。
交叉算子 CR :交叉算子CR是一个范围在[0,1]内的实数,它控制着一个试验向量参数来自于随机选择的变异向量而不是原来向量的概率。交叉算子CR越大,发生交叉的可能性就越大。CR的一个较好的选择是0.1,但较大的CR通常会加速收敛,为了看看是否可能获得一个快速解,可以先尝试CR = 0.9或CR = 1.0。
最大进化代数:一般,G取100~500.
终止条件:除最大进化代数可作为差分进化算法的终止条件外,还可以增加其他判定准则。一般当目标函数值小于阈值时程序终止,阈值常选为10^-6。
上述参数中,F、CR于NP一样,在搜索过程中是常数,一般F和CR影响搜索过程的收敛速度和稳健性,他们的优化值不仅依赖于目标函数的特性,还与NP有关。通常可通过对不同值做一些试验之后,利用试验和结果误差找到F、CR和NP的合适值。(最好自己在程序中随意修改参数,看看效果)
MATLAB仿真实例

源代码如下所示:
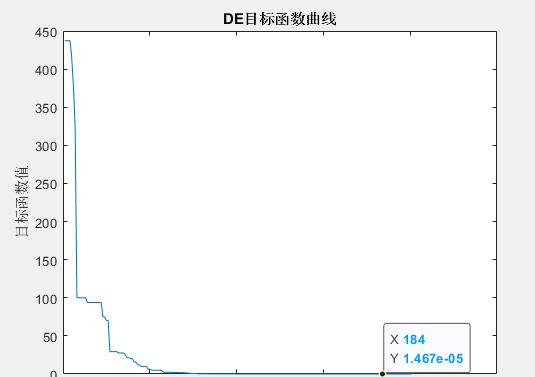
%%%%%%%%%%%%%%%%%%%%%差分进化算法求函数极值%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%初始化%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%clear;%清除所有变量close all;%清图clc;%清屏NP = 50;%种群数量,根据经验,种群数量NP的合理选择在5D~10D之间(D为变量的维数)。必须满足NP>=4,以确保差分进化算法具有足够的不同的变异向量D = 10;%变量的维数G = 200;%最大进化代数,一般G取 100~500F0 = 0.4;%初始变异算子。F小于0.4和大于1的值偶尔有效,F = 0.5通常是一个较好的初始选择。若种群过早收敛,那么F或NP应该增大。CR = 0.1;%交叉算子。CR的一个较好的选择是0.1,但较大的CR通常会加速收敛,为了看看是否可能获得一个快速解,可以先尝试CR=0.9或CR=1.0。Xs = 20;%上限Xx = -20;%下限yz = 10^-6;%阈值。一般当目标函数小于阈值时程序终止,阈值通常选为10^-6.%%%%%%%%%%%%%%%%%赋初值%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%x = zeros(D,NP);%初始种群v = zeros(D,NP);%变异种群u = zeros(D,NP);%选择种群x = rand(D,NP)*(Xs-Xx) Xx;%赋初值%%%%%%%%%%%%%%%%%%%%%%%%%计算目标函数%%%%%%%%%%%%%%%%%%%%%%%%%%for m = 1:NP Ob(m) = func31(x(:,m));endtrace(1) = min(Ob);%%最优解%%%%%%%%%%%%%%%%%%%%%%差分进化循环%%%%%%%%%%%%%%%%%%%%%%%for gen = 1:G %%%%%%%%%%%%%%%%%%%%%%%%变异操作%%%%%%%%%%%%%%%%%%%%%%%%%% %%%%%%%%%%%%%%%%%%%%%%%自适应变异算子%%%%%%%%%%%%%%%%%%%%%%%%% lamda = exp(1-G/(G 1-gen)); F = F0*2^(lamda); %%%%%%%%%%%%%%%%%%%%%r1,r2,r3和m互不相同%%%%%%%%%%%%%%%%%%%% for m = 1:NP r1 = randi(NP);%%%生成1*1的随机矩阵,矩阵元素为1~NP内的整数 while (r1 == m) r1 = randi(NP); end r2 = randi(NP); while (r2 == m)||(r2 == r1) r2 = randi(NP); end r3 = randi(NP); while (r3 == r1)||(r3 == r2)||(r3 == m) r3 = randi(NP); end v(:,m) = x(:,r1) F*(x(:,r2)-x(:,r3)); end %%%%%%%%%%%%%%%%%%%%%%%交叉操作%%%%%%%%%%%%%%%%%%%%%%%% r = randi(D);% r 属于[1,D]表示一个随机选择序列,用它确保试验向量u至少从变异向量v至少获得一个变量。 for n = 1:D cr = rand(1);%cr 表示产生[0,1]之间随机数发生器的估计值 if (cr <=CR) || (n == r) u(n,:) = v(n,:); else u(n,:) = x(n,:); end end %%%%%%%%%%%%%%%%%%边界条件的处理%%%%%%%%%%%%%%%%%%%%%%%% %在有边界约束的问题中,必须保证产生新个体的参数值位于问题的可行域中,一个简单方法就是将不符合边界约束的新个体用在可行域中随机产生的参数向量代替。 %另外一个方法是进行边界吸收处理,即将超过边界约束的个体值设置为临近的边界值。 for n = 1:D for m = 1:NP if (u(n,m)<Xx)||(u(n,m)>Xs) u(n,m) = rand*(Xs-Xx) Xx;%这里采用的是第一种边界处理方法。 end end end %%%%%%%%%%%%%%%%%%%选择操作%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% for m = 1:NP Ob1(m) = func31(u(:,m)); end for m = 1:NP if Ob1(m) < Ob(m) x(:,m) = u(:,m); end end for m = 1:NP Ob(m) = func31(x(:,m)); end trace(gen 1) = min(Ob); if min(Ob(m)) < yz break;%除进化代数可作为差分进化算法的终止条件外,还可以增加其他判定准则。一般当目标函数值小于阈值时程序终止,阈值常选为10^-6. endend[SortOb,Index] = sort(Ob);%sort(),默认是按照升序排列,如果想按照降序排列sort(,‘descend’)x = x(:,Index); %最优变量X = x(:,1);%最优值%%%%%%%%%%%%%%%%%%%画图%%%%%%%%%%%%%%%%%%%%%%%%%%%%%figureplot(trace);%绘制最优解xlabel(‘迭代次数’);ylabel(‘目标函数值’);title(‘DE目标函数曲线’);
仿真结果: