Python专栏
比如下面这篇文档1.txt
怎么办呢?

这里为方便大家阅读
在实际应用中,可能有几千、几万、
不过,不论文档中有多少文字、有多少号码
都是适用的
这里示例的文档是txt文件
其它格式的文档
进行一定的调整,也是可以的
第1步
读取txt文件中的文字
示例的文件是1.txt
该文件保存在E盘下的100文件夹下
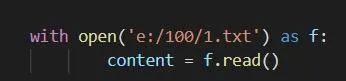
输入以上代码
1.txt文件中的内容就被全部读取
并保存到content变量
接下来就通过正则表达式
对content变量中的文字
进行筛选和提取
第2步
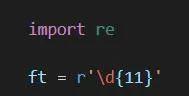
首先导入正则表达式的库
即import re
的正则表达式
也就是匹配出连续的11位数字
当然,有人会说,连续11位的数字
根据实际情况需要,可以对ft的
正则表达式进行调整
使其能够适应更多情况的需要
第3步
调用re库的findall函数
按照ft表达式,提取content变量中
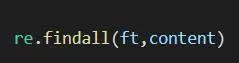
提取的结果如下
都被筛选出来了

以上步骤和pyhton代码
是不是很简单
尤其是大量的、批量的文档
从中筛查出所需的数据
按照人工的处理方式
往往很耗时、费力
结果可能不一定完全准确
而使用简单的几行代码、几分钟
就可以解决几个小时、几天
才能完成的工作量
而且是保质地完成所有工作
其它要说的
还可以筛选:
某个词出现的次数
某些词分别出现的次数
指定文字前或后的文字
等等
总之
通过恰当地使用
python代码及相应的方法
可以大大提高我们的工作效率
提升我们的工作质量和效果