你知道的越多,不知道的就越多,业余的像一棵小草!
你来,我们一起精进!你不来,我和你的竞争对手一起精进!
一般来说,使用原生ribbon而不搭配feign的话,使用的都是RestTemplate,通过这个RestTemplate 来访问其他的服务,看起来是这样的!
@LoadBalanced@BeanpublicRestTemplategetRestTemplate(){returnnewRestTemplate();}
RestTemplate本身并没有负载均衡的功能,只是一个单纯的http请求组件而已,通过上面的代码,我们可以发现多了一个@LoadBalanced注解,这个注解就是ribbon实现负载均衡的一个入口,我们就从这里开始看。
/***AnnotationtomarkaRestTemplatebeantobeconfiguredtouseaLoadBalancerClient*@authorSpencerGibb*/@Target({ElementType.FIELD,ElementType.PARAMETER,ElementType.METHOD})@Retention(RetentionPolicy.RUNTIME)@Documented@Inherited@Qualifierpublic@interfaceLoadBalanced{}
乍一眼看过去,这个注解好像是没啥东西,这个时候就需要一些技巧了,一般的Spring Boot项目都会有一个XXXAutoConfigration类作为自动配置类,这里面都会提供一些有用的信息,在同一个包下稍微找找就能发现一个类叫做LoadBalancerAutoConfiguration,我们接着往里面看。
在这个类里面,最重要的就是给RestTemplate 添加了一个拦截器,那么这个拦截器的作用是什么呢?其实这个拦截器就是将请求交给了ribbon来处理,之后的负载均衡就由ribbon全权负责了。
@Configuration@ConditionalOnMissingClass(“org.springframework.retry.support.RetryTemplate”)staticclassLoadBalancerInterceptorConfig{@BeanpublicLoadBalancerInterceptorribbonInterceptor(LoadBalancerClientloadBalancerClient,LoadBalancerRequestFactoryrequestFactory){returnnewLoadBalancerInterceptor(loadBalancerClient,requestFactory);}@Bean@ConditionalOnMissingBeanpublicRestTemplateCustomizerrestTemplateCustomizer(finalLoadBalancerInterceptorloadBalancerInterceptor){returnnewRestTemplateCustomizer(){@Overridepublicvoidcustomize(RestTemplaterestTemplate){List<ClientHttpRequestInterceptor>list=newArrayList<>(restTemplate.getInterceptors());list.add(loadBalancerInterceptor);//将拦截器加入到restTemplate中restTemplate.setInterceptors(list);}};}}
接下来就是看看这个拦截器具体在做些什么,首先进入这个拦截器的类,发现里面有一个intercept方法。
@OverridepublicClientHttpResponseintercept(finalHttpRequestrequest,finalbyte[]body,finalClientHttpRequestExecutionexecution)throwsIOException{//获取请求urlfinalURIoriginalUri=request.getURI();//获取服务名称StringserviceName=originalUri.getHost();Assert.state(serviceName!=null,”RequestURIdoesnotcontainavalidhostname:” originalUri);returnthis.loadBalancer.execute(serviceName,requestFactory.createRequest(request,body,execution));}
拦截器最后又调用了loadBalancer的execute方法,那就接着往下看吧。
@Overridepublic<T>Texecute(StringserviceId,LoadBalancerRequest<T>request)throwsIOException{ILoadBalancerloadBalancer=getLoadBalancer(serviceId);Serverserver=getServer(loadBalancer);if(server==null){thrownewIllegalStateException(“Noinstancesavailablefor” serviceId);}RibbonServerribbonServer=newRibbonServer(serviceId,server,isSecure(server,serviceId),serverIntrospector(serviceId).getMetadata(server));returnexecute(serviceId,ribbonServer,request);}
这里的loadBalancer默认是ZoneAwareLoadBalancer,下面的方法就是getServer方法,光从方法名也可以猜出来这个方法就会根据多个服务实例负载均衡出来一个机器出来,那么在此之前就有一个问题了,我们是如何取到所有服务实例的信息的呢?
这就得依靠服务注册中心了,因为服务实例的信息都注册到了服务注册中心中了,这里以Eureka为例,那么ribbon是如何从Eureka中获取到服务实例信息呢?
这里的奥秘就在ZoneAwareLoadBalancer中。
publicZoneAwareLoadBalancer(IClientConfigclientConfig,IRulerule,IPingping,ServerList<T>serverList,ServerListFilter<T>filter,ServerListUpdaterserverListUpdater){super(clientConfig,rule,ping,serverList,filter,serverListUpdater);}
在ZoneAwareLoadBalancer的构造函数中,我们发现其实就是调用了父类(DynamicServerListLoadBalancer)的构造方法,接着往下走。
publicDynamicServerListLoadBalancer(IClientConfigclientConfig,IRulerule,IPingping,ServerList<T>serverList,ServerListFilter<T>filter,ServerListUpdaterserverListUpdater){super(clientConfig,rule,ping);this.serverListImpl=serverList;this.filter=filter;this.serverListUpdater=serverListUpdater;if(filterinstanceofAbstractServerListFilter){((AbstractServerListFilter)filter).setLoadBalancerStats(getLoadBalancerStats());}restOfInit(clientConfig);}
重点在restOfInit方法中。
voidrestOfInit(IClientConfigclientConfig){booleanprimeConnection=this.isEnablePrimingConnections();//turnthisofftoavoidduplicatedasynchronousprimingdoneinBaseLoadBalancer.setServerList()this.setEnablePrimingConnections(false);enableAndInitLearnNewServersFeature();updateListOfServers();if(primeConnection&&this.getPrimeConnections()!=null){this.getPrimeConnections().primeConnections(getReachableServers());}this.setEnablePrimingConnections(primeConnection);LOGGER.info(“DynamicServerListLoadBalancerforclient{}initialized:{}”,clientConfig.getClientName(),this.toString());}
enableAndInitLearnNewServersFeature方法我们之后再说,先来看updateListOfServers方法,很明显这个方法就是在更新服务实例列表的信息,可以直接理解为从Eureka中获取服务实例注册表中的信息。
@VisibleForTestingpublicvoidupdateListOfServers(){List<T>servers=newArrayList<T>();if(serverListImpl!=null){servers=serverListImpl.getUpdatedListOfServers();LOGGER.debug(“ListofServersfor{}obtainedfromDiscoveryclient:{}”,getIdentifier(),servers);if(filter!=null){servers=filter.getFilteredListOfServers(servers);LOGGER.debug(“FilteredListofServersfor{}obtainedfromDiscoveryclient:{}”,getIdentifier(),servers);}}updateAllServerList(servers);}
serverListImpl.getUpdatedListOfServers()这段代码就是从Eureka中获取服务注册信息,走得是DiscoveryEnabledNIWSServerList的getUpdatedListOfServers方法,具体这边就不再展开细讲了,反正这里就获取到了所有的服务实例信息,以供后面的负载均衡算法来进行选择
回过头再看看之前跳过的enableAndInitLearnNewServersFeature方法。
publicvoidenableAndInitLearnNewServersFeature(){LOGGER.info(“UsingserverListUpdater{}”,serverListUpdater.getClass().getSimpleName());serverListUpdater.start(updateAction);}protectedfinalServerListUpdater.UpdateActionupdateAction=newServerListUpdater.UpdateAction(){@OverridepublicvoiddoUpdate(){updateListOfServers();}};
发现这个方法里面还是调用的updateListOfServers方法,这里其实就是一个线程,每隔30秒再去Eureka同步一下最新的服务注册信息。
如果你还有印象的话,我们之前就是分析到了获取负载均衡的算法的地方,也就是getServer方法。
protectedServergetServer(ILoadBalancerloadBalancer){if(loadBalancer==null){returnnull;}returnloadBalancer.chooseServer(“default”);//TODO:betterhandlingofkey}
chooseServer就是实际进行负载均衡的地方,这里会根据你使用的负载均衡算法从服务实例中选择一台机器来发送请求,跳过中间的代码跳转,直接来分析一下默认的RoundRobinRule,轮询算法。
publicServerchoose(ILoadBalancerlb,Objectkey){if(lb==null){log.warn(“noloadbalancer”);returnnull;}Serverserver=null;intcount=0;//count在这里其实是一个重试的次数while(server==null&&count <10){//所有启动的服务实例List<Server>reachableServers=lb.getReachableServers();//通过Eureka获取的服务实例List<Server>allServers=lb.getAllServers();intupCount=reachableServers.size();intserverCount=allServers.size();//没有可用服务实例的话返回nullif((upCount==0)||(serverCount==0)){log.warn(“Noupserversavailablefromloadbalancer:” lb);returnnull;}//轮询算法的核心,也很好理解,递增并根据服务实例数量取模intnextServerIndex=incrementAndGetModulo(serverCount);//从所有服务实例中取出选择的那台机器server=allServers.get(nextServerIndex);if(server==null){/*Transient.*/Thread.yield();continue;}//服务实例是可用的话则返回它if(server.isAlive()&&(server.isReadyToServe())){return(server);}//Next.server=null;}if(count>=10){log.warn(“Noavailablealiveserversafter10triesfromloadbalancer:” lb);}returnserver;}
到这里为止就已经分析完了整个ribbon负载均衡的流程,之后就可以根据选择的服务实例,去发送我们的请求了。
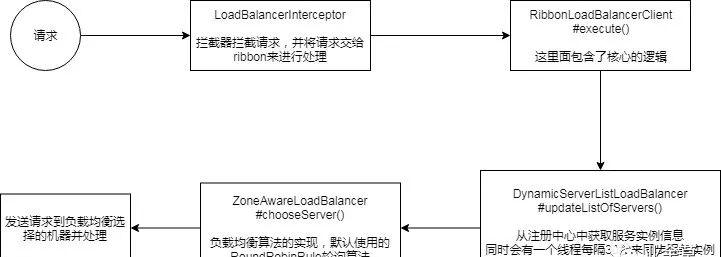
通过这张图来总结一下整个ribbon负载均衡的流程。
发送请求,被LoadBalancerInterceptor拦截器拦截,请求被交给ribbon来处理拦截器拦截请求,交给了RibbonLoadBalancerClient的execute方法(下面的逻辑都是包含在这个方法中)在进行负载均衡之前首先得知道有哪些服务实例信息,所以通过DynamicServerListLoadBalancer的updateListOfServers方法从注册中心(Eureka)那里获取到了所有的服务实例信息,并且会定时更新使用负载均衡算法(默认轮询算法)从所有的服务实例信息中选择一台机器出来将请求发送给负载均衡选择出来的服务实例上去