虽然爬虫不是一门主流技术,但因其抓取速度快和数据质量优的两大特点而受到越来越多的人追捧,互联网时代,有爬虫技术的加持对于职场人来说无疑是锦上添花。
随着爬虫技术的流行,网上的资源层出不穷,但对于初学者来说,可能难以选择,如果选错还会在爬虫学习上走一些弯路。
我们专门针对零基础的同学做了一份python爬虫资源汇总,包含书单、网站博客、框架、工具以及项目汇总。至于为什么选择python语言,是因为python对于小白来说更容易上手。
– 必读书单 –
不需要一大堆书单和教程,关于python爬虫,看这8本书就够了。
01
《Python编程:从入门到实践》
豆瓣评分:9.1

本书是一本针对所有层次的Python 读者而作的Python 入门书。
全书分两部分:第一部分介绍用Python 编程所必须了解的基本概念,第二部分将理论付诸实践,讲解如何开发三个项目。
??????
02
《Python编程快速上手》
豆瓣评分:9.0

本书是一本面向实践的Python编程实用指南。不仅介绍Python语言的基础知识,而且还通过项目实践教会读者如何应用这些知识和技能。
??????
03
《像计算机科学家一样思考Python》
豆瓣评分:8.7

本书以培养读者以计算机科学家一样的思维方式来理解Python语言编程,这是一本实用的学习指南,适合没有Python编程经验的程序员阅读。
??????
04
《“笨方法”学Python》
豆瓣评分:7.9

本书非常适合想通过语言的核心来学习Python编程的初学者。你将通过完成52个精心设计的习题来学会Python。
??????
05
《Python Cookbook 中文版》
豆瓣评分:9.2

本书覆盖了Python应用中的很多常见问题,并提出了通用的解决方案。
书中包含了大量实用的编程技巧和示例代码,非常适合具有一定编程基础的Python程序员阅读。
??????
06
《流畅的python》
豆瓣评分:9.4

从语言设计层面剖析编程细节,兼顾Python 3和Python 2。
告诉你Python中不亲自动手实践就无法理解的语言陷阱成因和解决之道,教你写出风格地道的Python代码。
??????
07
《深入浅出python》
豆瓣评分:8.5

如果你想要学习Python编程的基础知识,并且不想要看一堆乏味难懂的书籍和教程。那么Paul Barry的《Head First Python》就是你的不二之选。
??????
08
《python3 网络爬虫开发实战》
豆瓣评分:9.0
全面介绍了利用 Python3 开发网络爬虫的知识.
从各种类型的环境配置和爬虫基础知识出发,配合新鲜案例进行数据爬取,还教授一些爬虫技巧,是一本很好的实战书籍。
??????
/
我们已经将以上提及的书单资源进行了打包
/
– 网站博客 –
01
awesome-python-login-model
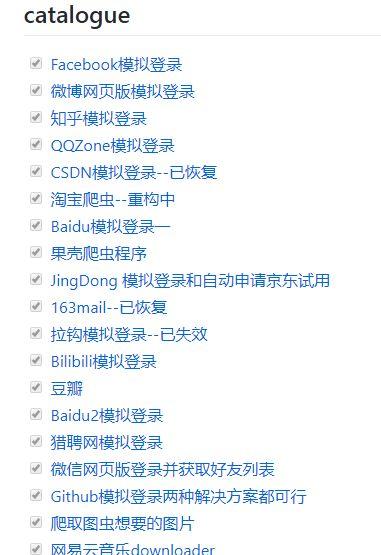
该项目收集了一些各大网站登陆方式和一些网站的爬虫程序,用于研究和分享各大网站的模拟登陆方式和爬虫程序。
网址:https://awesome-python
??????
02

网址:https://cuiqingcai.com
??????
03
Scraping.pro

Scraping.pro是一个专业的采集软件测评网站,上面有各种国外比较顶尖的采集软件测评文,比如scrapy、octoparse等
网址:http://www.scraping.com/
??????
04
Kdnuggets
相比scraping.pro,Kdnuggets涵盖范围更广,包括商业分析、大数据、数据挖掘、数据科学等。
网址:https://www.kdnuggets.com/
??????
05
Octoparse
Octoparse是一款功能强大的免费采集软件,它的博客提供的内容比较广,浅显易懂,比较适合初步的网站采集用户。
网址:https://www.octoparse.com
??????
06
Big Data News
Big data news和Kdnuggets类似,涵盖的范围主要是在大数据行业方面,网站采集是其下面的一个子栏目。
网址:https://www.bigdatanews
??????
07
Analytics Vidhya
跟Big data news类似,Analytics Vidhya是一个更专业的数据采集网站,内容涵盖数据科学、机器学习、网站采集等。
网址:https://www.analyticsvidhya
??????
-爬虫框架 –
01
Scrapy
是一个为了爬取网站数据,提取结构性数据而编写的应用框架。可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。
网址:https://scrapy.org
??????
02
PySpider
pyspider是一个用python实现的功能强大的网络爬虫系统,能在浏览器界面上进行脚本的编写,功能的调度和爬取结果的实时查看.
后端使用常用的数据库进行爬取结果的存储,还能定时设置任务与任务优先级等。
网址:https://pyspider
??????
03
Crawley

Crawley可以高速爬取对应网站的内容,支持关系和非关系数据库,数据可以导出为JSON、XML等。
网址:http://crawley-cloud.com/
??????
04
Portia
Portia是一个开源可视化爬虫工具,可让您在不需要任何编程知识的情况下爬取网站!
网址:https://portia
??????
05
Newspaper
Newspaper可以用来提取新闻、文章和内容分析。使用多线程,支持10多种语言等。
网址:https://newspaper
??????
06
Beautiful Soup

Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库。
它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式。
网址:https://BeautifulSoup/bs4/doc/
??????
07
Grab
Grab是一个用于构建Web刮板的Python框架。
您可以构建各种复杂的网页抓取工具,从简单的5行脚本到处理数百万个网页的复杂异步网站抓取工具。
网址:http://grab-spider-user-manual
??????
08
Cola
??????
-工具 –
01
4个HTTP代理工具
(1)Fiddler
Fiddler 是 Windows 平台最好用的可视化抓包工具,也是大家最熟知的 HTTP 代理工具。
功能非常强大,除了可以清晰的了解每个请求与响应之外,还可以进行断点设置,修改请求数据、拦截响应内容。
链接:https://www.telerik.com/fiddler
(2)Charles
Charles 是 macOS 平台下最好用的抓包分析工具之一。
同样提供GUI界面,界面简洁,基本功能包括HTTP、HTTPS 请求抓包,支持请求参数的修改,最新的 Charles 4 还支持 HTTP/2。
链接:https://www.charlesproxy.com/
(3)AnyProxy
AnyProxy 是 阿里巴巴开源的 HTTP 抓包工具,基于 NodeJS 实现。
优点是支持二次开发,可自定义请求处理逻辑,如果你会写JS的话,同时需要做一些自定义的处理,那么AnyProxy 是非常适合的。
(4)mitmproxy
mitmproxy 是一款基于 Python,支持 SSL 的抓包工具。它是跨平台的,而且提供的是命令行交互模式。
??????
02
python爬虫工具汇总
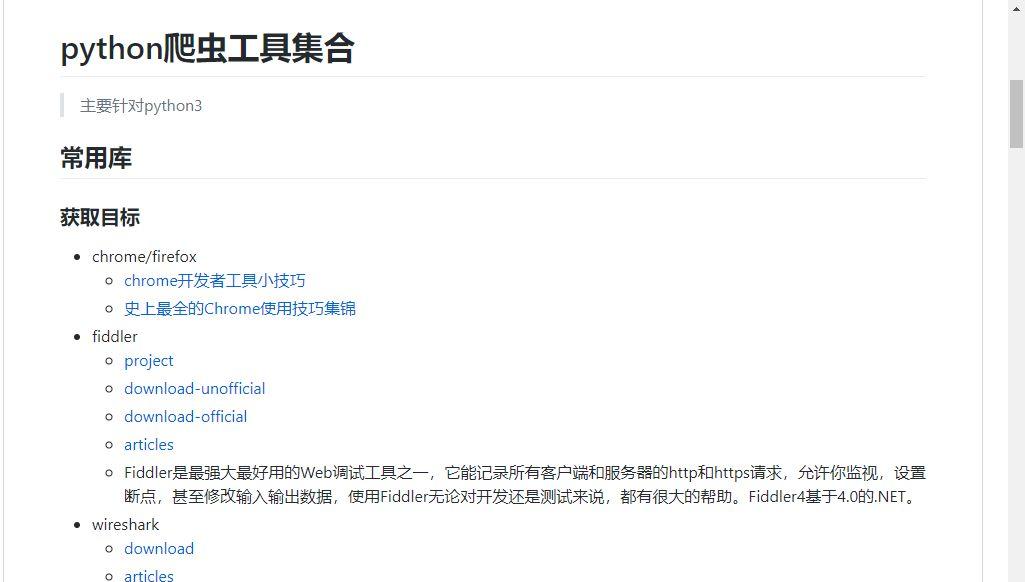
这是关于python爬虫的工具汇总,只要你能想到的几乎都能在这儿找到。
网址:https://lartpang/spyder_tool
??????
03
httpbin
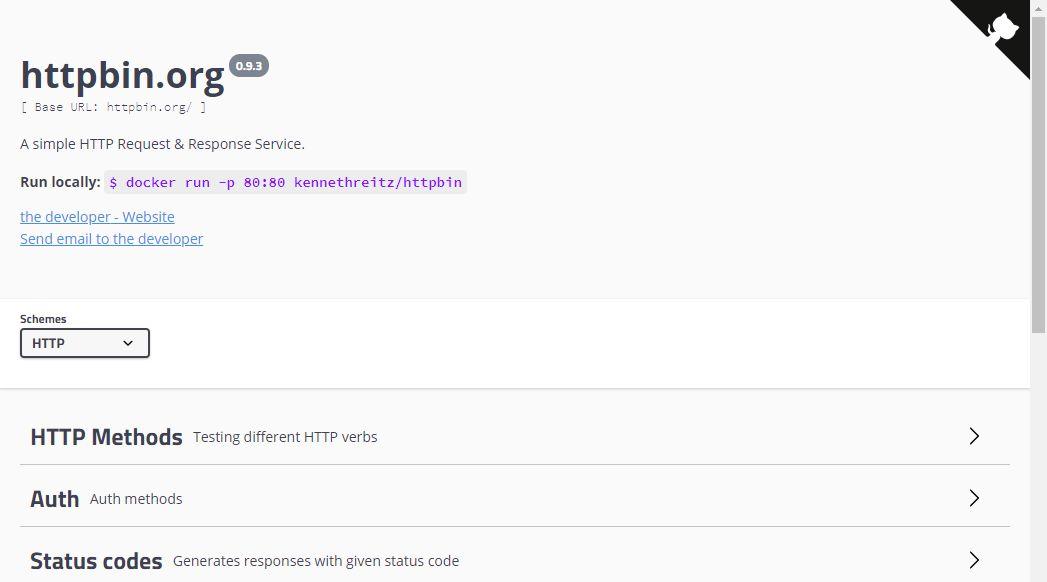
此网站可以用作爬虫的测试(http和https),会返回爬虫机器的一些信息,也可以做在线测试。
网址:httpbin.org
??????
04
curl to python
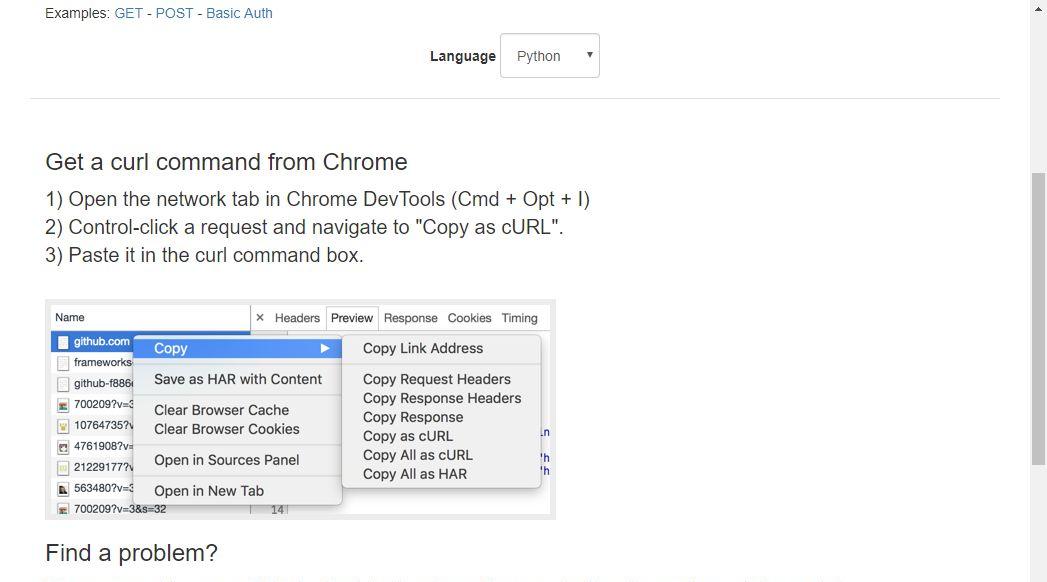
此网站可以将curl命令快速转为python的requests请求(其他语言也可以),而curl命令可以通过浏览器开发者工具快速获取。
网址:https://curl.trillworks.com
??????
05
在线转换
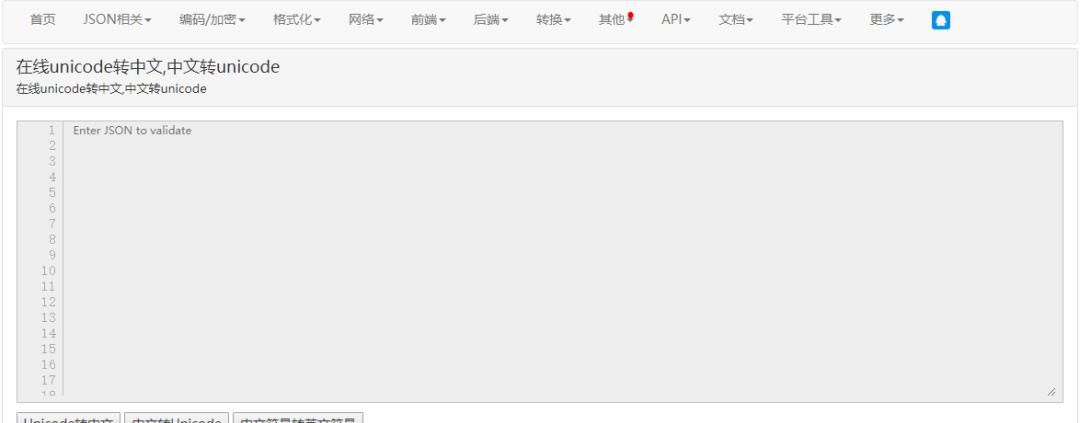
有时我们在网页上看到是中文,但查看网页源码时显示的是unicode字符,此时需要在线unicode字符转中文。
网址:https://unicode_chinese/
??????
06
XPath Helper
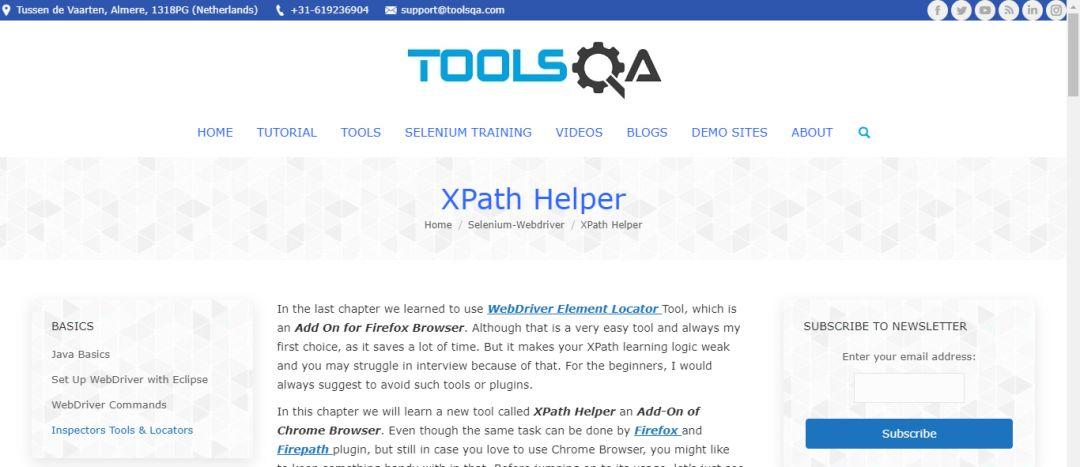
此工具是chrome的扩展程序,用于辅助分析和调试xpath。
链接:https://xpath-helper/
??????
07
JavaScript Toggle On and Off
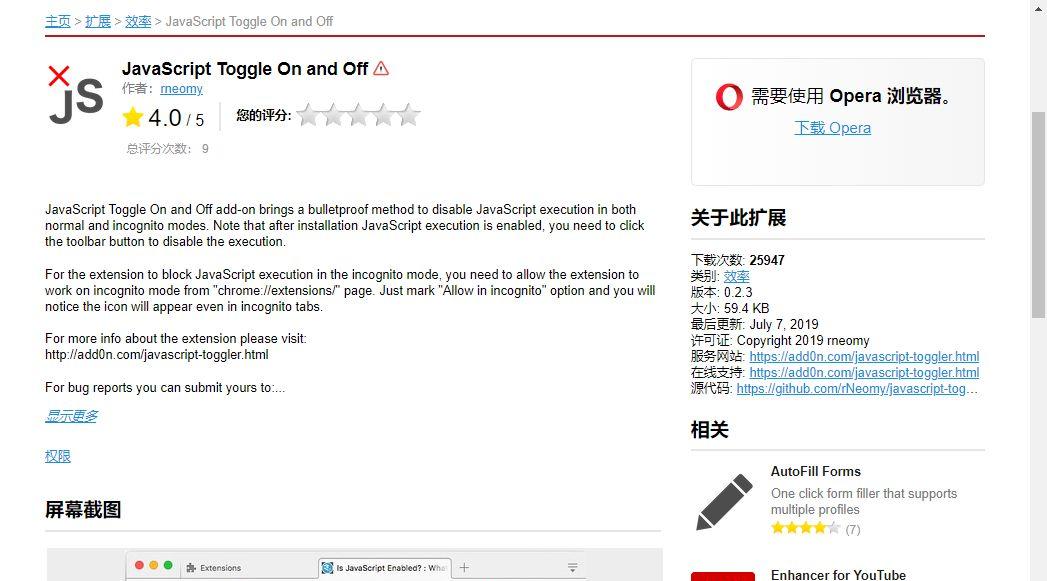
此工具为chrome扩展程序,用于检测目标网站哪些元素是通过JS加载的。
网址:https://toggle-on-and-off
??????
08
EditThisCookie
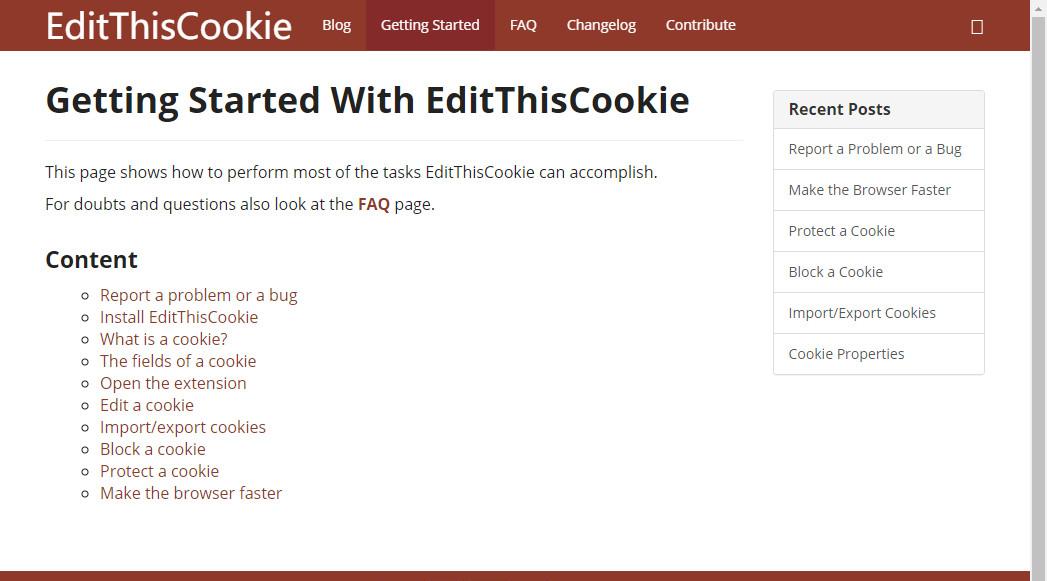
此工具为chrome扩展程序,可对目标网站的cookies进行任意的操作,具体详细的用法可查看上面提供的官方文档。
网址:Getting Started with EditThisCookie
??????
09
Postman

官方推荐使用本地应用程序代替chrome的扩展程序,因此只需在官网下载安装包即可。
Postman是一款web调试和测试的工具,请求参数完全由自己控制,可模拟几乎所有类型的http请求。
网址:Postman
??????
10
代理ip检测
做爬虫时,很多时候需要用到代理ip,此网站可以查看代理是否可用,代理ip的匿名程度,地点等信息。
网址:proxyhttp.net/check
??????
– 项目上手 –
作为一门技术,知晓了方法,想要掌握的秘诀就是训练,那么通过项目来练手就非常重要了。
既然书读百遍奇异自现,那爬虫百遍,相信你也能找到爬虫的通用套路和技巧。
01
网址:https://WechatSogou
02
豆瓣读书爬虫
可以爬下豆瓣读书标签下的所有图书,按评分排名依次存储,存储到Excel中。
网址:https://DouBanSpider
03
知乎爬虫
此项目的功能是爬取知乎用户信息以及人际拓扑关系,爬虫框架使用scrapy,数据存储使用mongo
网址:https://zhihu_spider
04
哔哩哔哩爬虫
爬取B站用户数据并生成B站用户数据报告。
网址:https://bilibili-user
05
新浪微博爬虫
网址:https://SinaSpider
06
小说爬虫
使用scrapy,Redis, MongoDB,graphite实现的一个分布式网络爬虫。
网址:https://distribute_crawler
07
中国知网爬虫
中国知网爬虫,设置检索条件后,执行src/CnkiSpider.py抓取数据,抓取数据存储在/data目录下,每个数据文件的第一行为字段名称。
网址:https://CnkiSpider
08
链家爬虫
爬取北京地区链家历年二手房成交记录。涵盖链家爬虫一文的全部代码,包括链家模拟登录代码。
网址:https://LianJiaSpider
09
京东爬虫
基于scrapy的京东网站爬虫,保存格式为csv。
网址:https://scrapy_jingdong
10
11
包括日志、说说、个人信息等,一天可抓取 400 万条数据。
12
hao123爬虫
以hao123为入口页面,滚动爬取外链,收集网址,并记录网址上的内链和外链数目,记录title等信息,windows7 32位上测试,目前每24个小时,可收集数据为10万左右。
网址:https://sdfzy/spider
13
机票爬虫
Findtrip是一个基于Scrapy的机票爬虫,目前整合了国内两大机票网站(去哪儿 携程)。
网址:https://findtrip
14
豆瓣爬虫集
豆瓣电影、书籍、小组、相册、东西等爬虫集。
网址:https://doubanspiders
15
mp3爬虫
百度mp3全站爬虫,使用redis支持断点续传。
网址:https://baidu-music-spider
16
淘宝天猫爬虫
可以根据搜索关键词,物品id来抓去页面的信息,数据存储在mongodb。
网址:https://tbcrawler
17
股票爬虫
一个股票数据(沪深)爬虫和选股策略测试框架根据选定的日期范围抓取所有沪深两市股票的行情数据。
支持使用表达式定义选股策略。支持多线程处理。保存数据到JSON文件、CSV文件。
网址:https://stockholm
18
百度云爬虫
爬取百度云盘资源。
网址:https://BaiduyunSpider
19
社交数据爬虫
支持微博,知乎,豆瓣。
网址:https://Qutan/Spider
20
ip池爬虫
Python爬虫代理IP池(proxy pool)。
网址:https://proxy_pool
21
网易云爬虫
爬取网易云音乐所有歌曲的评论。
网址:https://music-163
22
图片爬虫
爬取煎蛋妹纸图片。
网址:https://jandan_spider
23
cnblogs爬虫
爬取cnblogs列表页。
网址:https://CnblogsSpider
24
慕课网爬虫
爬取慕课网视频。
网址:https://spider_smooc
25
知道创宇爬虫
知道创宇爬虫题目
网址:https://knowsecSpider2
26
图片爬虫
爱丝APP图片爬虫。
网址:https://aiss-spider
27
新浪爬虫
动态IP解决新浪的反爬虫机制,快速抓取内容。
网址:https://SinaSpider
28
csdn爬虫
爬取CSDN上的博客文章。
网址:https://csdn-spider
29
proxy爬虫
爬取proxy上的代理IP,并验证代理可用性。
网址:https://ProxySpider
30
乌云爬虫
乌云公开漏洞、知识库爬虫和搜索。
网址:https://wooyun_public
往 期 推 荐
壹
python爬虫,学习路径拆解及资源推荐
贰
这些不用编程的爬虫工具,你一定要知道
叁
python自测100题,还愁找不到工作?