HI,大家好,我是星光。今天和大家分享的是四个常用的套路化函数公式,都是用于模糊查询的。什么是模糊查询?我们说的模糊查询是指根据指定数据,在另一个数据表里查找与之相似的信息。总结起来,有4种常见的情况。第1种情况,正向模糊查询,或者说根据简称找全称。比如查找值是华为,数据源是华为技术有限公司,数据源包含查找值,如何判断两者匹配?第2种情况,反向模糊查询,根据全称查简称,和第1种情况刚好反过来。比如查找值是华为技术有限公司,数据源却是华为,也就是查找值包含数据源,又如何判断两者匹配?第3种情况,乱序型全匹配模糊查询。比较极端,但也不少见。比如查找值是华为公司,数据源却是华为技术有限公司,又如何判断两者匹配呢?第4种情况,最大近似度完全匹配。比如查找值是我看见星光,数据源有不看星光看月光,看不看见星光等,如何认为后者和我看见星光更加匹配?牵牵手,跟我来~
1
简称查全称
先来看第一个例子,根据简称查找全称。
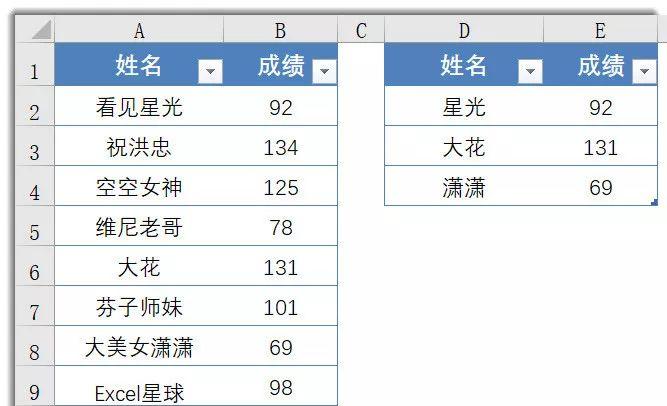
如上图所示,A:B列是某班人员和某科的高考成绩(照例严肃声明,人名和成绩都是虚拟的,如有雷同……那就雷同吧)。D列是部分人员的简称,现在需要根据A:B列的信息,查询D列人员的考试成绩。E2公式如下:=VLOOKUP(“*”&D2&”*”,A:B,2,0)公式解析▼VLOOKUP函数支持使用通配符查询,本例中查找值为”*”&D2&”*”,星号是通配符,可以代替零到多个字符。比如查找”*星光*”,可以匹配包含星光的任意字符。很明显,A2单元格的”看见星光”符合条件,于是取得其成绩92分。由于此处是查询成绩,且人名不存在重复的问题,所以也可以使用支持通配符的统计求和函数SUMIF:=SUMIF(A:A,”*”&D2&”*”,B:B)
2
全称查简称
既然有根据简称查全称的情况,自然也就有根据全称找简称的问题,这就是我要说的第二个例子。
需要严肃说明的是,以下数据中大美女潇潇是男扮女装的男生..▼
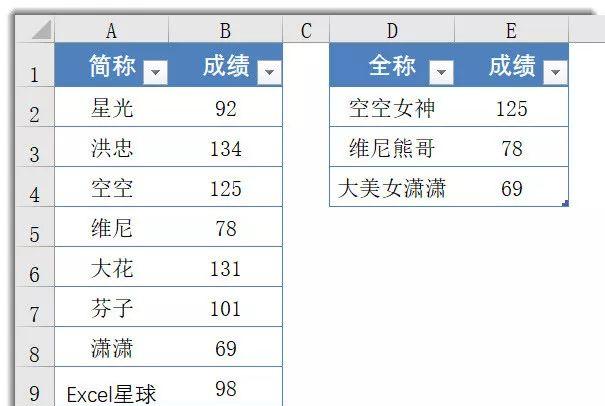
如上图所示,A:B列依然是某班人员姓名和某科的高考成绩。D列是部分人员的全称,现在,需要根据A:B列的信息,查询D列人员的考试成绩。
E2公式如下:
=LOOKUP(,-FIND(A$2:A$10,D2),B$2:B$10)
公式解析▼
LOOKUP的第一参数,查找值为0,做了省略处理(这是坏毛病,不要学)-FIND(A$2:A$10,D2)部分,使用FIND函数依次查询A2:A10的值是否在D2单元格中存在。如果存在,返回位置序号,如不存在,返回错误值#VALUE!,FIND函数的结果只有两种,正数和错误值,之后做减法运算,得到一个由负数和错误值构成的内存数组:{#VALUE!;#VALUE!;-1;#VALUE!;#VALUE!;#VALUE!;#VALUE!;#VALUE!;#VALUE!}
LOOKUP忽略错误值,它的查找值为0,比查找范围内的任意数值均大,因而直接返回最后的数值所对应的查找范围(B2:B10)的数据(这个知识点可以参考LOOKUP篇函数教程)。
以D2单元格的空空女神为例,返回B4单元格的数据125。……
说到这里,细心的同学也许已经发现,我举的两个例子,不管是简称查全称,还是全称找简称,都有一个最重要的规律,也就是每个简称都是全称完整的一部分,或者头部,或者尾部,或者中间。比如,大花是【大花美女】的头部,星光是【看见星光】的尾部。这么说,似乎有点奇怪,反正就是这么个意思。
但假设有这样一种情况,比如看见星光的简称是看星光,又如何通过简称找到全称看见星光呢?
之前的公式肯定是不成的。
打个响指,这就是我们要说的第三种情况。
3
乱序全字符串匹配
根据A:B列数据,在E列编写公式计算成绩..▼
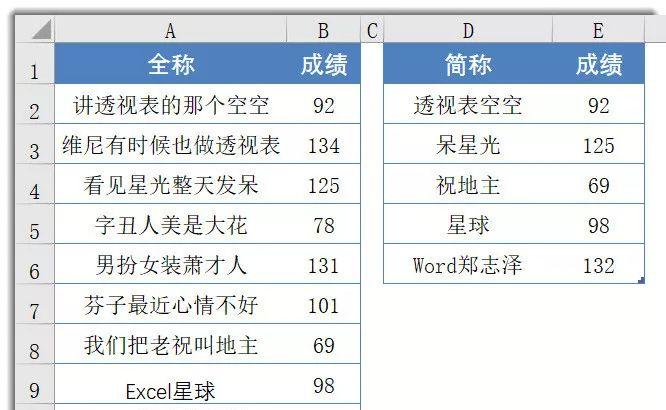
如上图所示,A:B列依然是某班人员和某科的高考成绩。D列是部分人员的简称,现在,需要根据A:B列的信息,在E列编写公式,查询D列人员的考试成绩。
比如,“透视表空空”和“讲透视表的那个空空”是匹配的——透 视 表 空 空,每一个字符都出现于字符串讲透视表的那个空空中。
E2公式如下:
代码看不全可以左右拖动..▼=INDEX(B:B,MATCH(,MMULT(-ISERR(FIND(MID(D2,COLUMN(A:Z),1),A$1:A$10)),ROW(1:26)),))
公式解析▼
-ISERR(FIND(MID(D2,COLUMN(A:Z),1),A$1:A$10))
MID函数从D2单元格的第1(A)个位置至第26(AZ)个位置分别截取1个字符;FIND函数判断MID函数的返回结果在A1:A10单元格中是否存在,如果存在,返回位置序号,否则,返回错误值,最后通过ISERR函数搭配减法运算,将FIND函数的结果转化为-1和0,构成一个26列10行的矩阵数组。
MMULT(-ISERR(FIND(MID(D2,COLUMN(A:Z),1),A$1:A$10)),ROW(1:26))
MMULT函数对矩阵数据进行计算,当D2单元格字符串的每一个字符都在A$1:A$10区域某个单元格中存在时,该行计算结果为0。
最后通过MATCH函数,取得MMULT函数返回结果首次为0的位置,再通过INDEX函数取值即可。
这个套路化公式的思路是判断所查询的字符串中每一个字符是否都在查找范围内存在,换句话说,就是玩一个文字归属计数游戏。那么,思考题来了,既然有这种情况的简称找全称,自然也有这种情况的全称找简称,如果碰到下面这种情况,如何书写公式呢?
根据D:E列数据,在B列编写公式计算成绩..▼
侬自己想……
4
最大近似度匹配
第4个函数套路是处理最大近似度匹配……如下图所示,需要根据A:B列的数据源,获取D列相关人名的语文考试成绩。
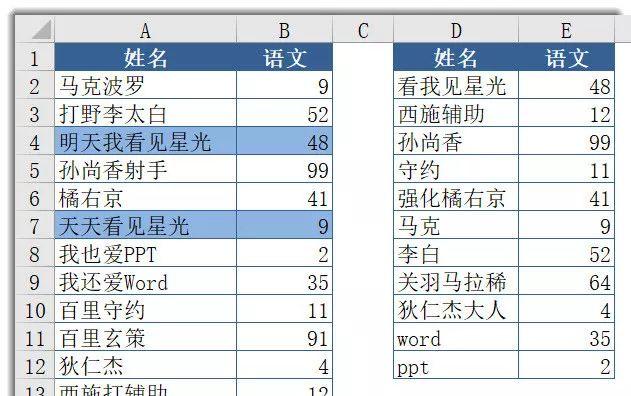
比如D2单元格的看我见星光,对应的有A列的明天我看见星光和天天看见星光,其中明天我看见星光相似度最高,有5个字符重叠了。那么如何获取相似度最高的匹配结果呢?E2公式数组公式如下:代码看不全可以左右拖动..▼=IFERROR(VLOOKUP(D2,$A:$B,2,0),INDEX(B:B,RIGHT(MAX(MMULT(1-ISERR(SEARCH(MID(D2,TRANSPOSE(ROW(INDIRECT(“1:”&LEN(D2)))),1),$A$2:$A$14)),ROW(INDIRECT(“1:”&LEN(D2)))^0)/1%% ROW($2:$14)),3)))
公式解析▼
公式首先采用精确匹配的方式进行匹配VLOOKUP(D2,$A:$B,2,0),匹配不到结果之后,再采用最大近似度匹配。
SEARCH(MID(D2,TRANSPOSE(ROW(INDIRECT(“1:”&LEN(D2))使用SEARCH函数判断D2字符串中的每一个值是否在数据源中存在(注意:SEARCH函数不区分字母大小写),生成一个矩阵数组。然后使用MMULT函数统计矩阵中每一个字符串中字符出现的个数,再使用加权法,除以10000,同时用 ROW($2:$14)标记行号,末了使用MAX函数从中获取最大值。
最后使用INDEX函数根据行号按图索骥获取最终结果。公式稍加修改,也可以实现指定标准的近似度匹配,比如80%的近似度匹配
……
别皱眉头,笑一笑。复杂的数组公式理解与否其实并不重要,重要的是……知道有这么回事,遇见问题直接复制公式粘贴使用——你开心就好,认真脸。打个响指,最后再说两句,这年代拖堂的好老师真是不多了,给自己笔芯。
不管是采用模糊匹配,还是最大近似度匹配,都优先推荐先使用完全匹配查询,在查无结果的基础上,再选择其他匹配方式,以避免数据源存在完全匹配的结果,却优先匹配了模糊结果的问题。
此外,函数公式从来都不是万能的,VBA代码亦如是,正则也还是如此,关于简称和全称的查询和统计,最理想的情况自然还是制作一张匹配表,规范数据源,从源头上解决问题。
比如碰到下面这样的情况,若是没有个匹配表,那是真没辙。
看见星光 简称 帅哥
你说,如果没有个匹配表,谁知道看见星光和帅哥匹配呢?摊手,耸肩,看见星光自己天天照镜子都不知道啊?
拱手作别,下期再见。
文件下载,百度网盘..▼
https://pan.baidu.com/s/139O-DG_Xtm_WWA6UgzecJQ提取码: 7vkz