导读:拍下快递单就能自动填充单号,拍下名片信息就能自动归类,拍下题目就能自动搜索到答案,你可知道,这些神奇的功能是如何实现的?今天,小编就带领大家一起探秘OCR,并带来一份使用飞桨(PaddlePaddle)快速实现OCR功能的详细教程。
 1.OCR技术概述
1.OCR技术概述
OCR(Optical Character Recognition),译为光学字符识别,是指通过扫描等光学输入方式将各种票据、报刊、书籍、文稿及其它印刷品的文字转化为图像信息,再利用文字识别技术将图像信息转化为可以使用的计算机输入技术。
在不久前的首届“中国人工智能·多媒体信息识别技术竞赛”中,百度一举斩获印刷文本OCR、人脸识别和地标识别三项任务中的A级证书,其中印刷文本OCR的成绩更是摘得冠军,且因成绩显著优于其他参赛团队,成为该任务94支参赛队伍中唯一获得A级证书的单位。
在OCR技术出现之前,要把大量的卡证牌照、票据表单、纸质文档上的文字信息录入电脑,只能依赖人工,效率低下,而且极易出错。
随着OCR技术的成熟,“人工数字化”的现状被打破,OCR自动化识别代替了人工录入,大大节约了人力成本,有效提升了业务效率。
OCR技术的应用场景非常广泛:
(1)拍照/截图识别
使用OCR技术,实现拍照文字识别、相册图片文字识别和截图文字识别,可应用于搜索、书摘、笔记、翻译等移动应用中,方便用户进行文本的提取或录入,有效提升产品易用性和用户使用体验。

识别结果:

(2)内容审核与监管
使用OCR技术,实现对图像中文字内容的提取,结合文本审核技术识别违规内容,提示相应风险,协助进行违规处理,可应用于电商广告审核、舆情监管等场景,帮助用户有效规避业务风险。

(图片来自网络)
识别结果:

(3)视频内容分析
使用OCR技术,实现对视频中的字幕、标题、弹幕等文字内容的检测和识别,并根据文字位置判断文字类型,可应用于视频分类和标签提取、视频内容审核、营销分析等场景,有效降低人力成本,控制业务风险。

(图片来自网络)
识别结果:

(4)纸质文档电子化
使用OCR技术,实现对各类医疗单据、金融财税票据、法律卷宗等纸质文档的识别,并返回文字在图片中的位置信息以便于进行比对、结构化等处理,可满足医疗、金融、政务、法务、教育等行业文档快速录入、存档和检索的需求,有效降低企业人力成本,提高信息录入效率。

2.OCR技术原理
从整体上来说,OCR技术可以分为图像处理和文字识别两大阶段:
图像处理阶段:包含图像输入、图像预处理、版面分析、字符切割等子步骤。
文字识别阶段:包含特征提取、字符识别、版面恢复、后处理等子步骤。
流程图如下:
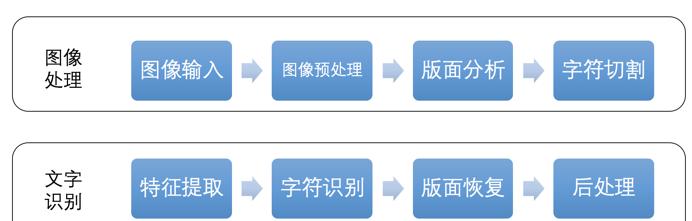
【文本检测】
图像输入:读取不同格式的图像文件。
图像预处理:包含灰度化、二值化、图像降噪、倾斜矫正等预处理步骤。
版面分析:针对左右两栏等特殊排版,进行版面分析并划分段落。
字符切割:对图像中的文本进行字符级的切割,尤其注意字符粘连等问题。
【文本识别】
特征提取:对字符图像提取关键特征并降维,用于后续的字符识别算法。
字符识别:依据特征向量,基于模版匹配分类法或深度神经网络分类法,识别出字符。
后处理:引入语言模型或人工检查,修正“分”和“兮”等形近字。
从整体上来看,OCR 的步骤繁多,涉及到的算法也很复杂。针对每一个步骤的每一个算法,都有单独的研究论文。如果从零开始做 OCR,将是一个十分浩大的工程。飞桨先从一个入门的实验开始,教您如何借助飞桨快速实现OCR功能。
3.飞桨OCR快速上手
3.1任务介绍
本次实验的任务是最简单的任务:识别图片中单行英文字符,从这个简单的任务开始,主要是熟悉OCR的关键技术点,实际上OCR的技术有很多,一般都是文本检测 文本识别,比如经典的CRNN CTC、Seq2seq Attention,考虑到文本检测涉及到的内容比较复杂,我们主要以CTC(Connectionist Temporal Classification) 模型为例,前提假设文本已经检测到,限定在一个比较小的行内,然后如何来进行文本识别部分的内容。
编码部分,首先采用卷积将图片转为特征图, 然后再将特征图转为序列,通过双向GRU学习到序列特征。
3.2 数据示例
数据的下载和简单预处理都在data_reader.py中实现。
数据示例:
我们使用的训练和测试数据如下图所示,每张图片包含单行不定长的英文字符串,这些图片都是经过检测算法进行预框选处理的。
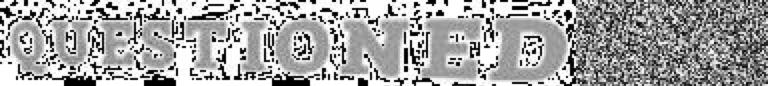
在训练集中,每张图片对应的label是汉字在词典中的索引。图1 对应的label如下所示:
80,84,68,82,83,72,78,77,68,67
在上边这个label中,80 表示字符Q的索引,67 表示英文字符D的索引。
3.3 数据准备
(1)训练集
我们需要把所有参与训练的图片放入同一个文件夹,暂且记为train_images。然后用一个list文件存放每张图片的信息,包括图片大小、图片名称和对应的label,这里暂记该list文件为train_list,其格式如下所示:
185 48 00508_0215.jpg 7740,5332,2369,3201,416248 48 00197_1893.jpg 6569338 48 00007_0219.jpg 4590,4788,3015,1994,3402,999,4553150 48 00107_4517.jpg 5936,3382,1437,3382…157 48 00387_0622.jpg 2397,1707,5919,1278
文件train_list,上述文件中的每一行表示一张图片,每行被空格分为四列,前两列分别表示图片的宽和高,第三列表示图片的名称,第四列表示该图片对应的sequence label。最终我们应有以下类似文件结构:
|-train_data |- train_list |- train_imags |- 00508_0215.jpg |- 00197_1893.jpg |- 00007_0219.jpg|…
在训练时,我们通过选项–train_images 和 –train_list 分别设置准备好的train_images 和train_list。
在data_reader.py中,会按照用户设置的DATA_SHAPE调整训练数据的高度。用户可以根据自己准备的训练数据,设置合适的DATA_SHAPE。如果使用默认的示例数据,则使用默认的DATA_SHAPE即可。
注:如果–train_images 和 –train_list都未设置或设置为None, data_reader.py会自动下载使用示例数据,并将其缓存到$HOME/.cache/paddle/dataset/ctc_data/data/ 路径下。
(2)测试集和评估集
测试集、评估集的准备方式与训练集相同。在训练阶段,测试集的路径通过train.py的选项–test_images和 –test_list 来设置。在评估时,评估集的路径通过eval.py的选项–input_images_dir 和–input_images_list 来设置。
在data_reader.py中,会按照用户设置的DATA_SHAPE调整测试图像的高度,所以测试图像可以有不同高度。但是,DATA_SHAPE需要和训练模型时保持严格一致。
(3)待预测数据集
预测支持三种形式的输入:
第一种:设置–input_images_dir和–input_images_list, 与训练集类似, 只不过list文件中的最后一列可以放任意占位字符或字符串,如下所示:
185 48 00508_0215.jpg s48 48 00197_1893.jpg s338 48 00007_0219.jpg s…
第二种:仅设置–input_images_list, 其中list文件中只需放图片的完整路径,如下所示:
data/test_images/00000.jpgdata/test_images/00001.jpgdata/test_images/00003.jpg
第三种:从stdin读入一张图片的path,然后进行一次inference.
在data_reader.py中,会按照用户设置的DATA_SHAPE调整预测图像的高度,所以预测图像可以有不同高度。但是,DATA_SHAPE需要和训练模型时保持严格一致。
3.4 模型训练
使用默认数据在GPU单卡上训练:
env CUDA_VISIBLE_DEVICES=0python train.py
使用默认数据在CPU上训练:
env python train.py–use_gpu False –parallel=False
使用默认数据在GPU多卡上训练:
env CUDA_VISIBLE_DEVICES=0,1,2,3 python train.py –parallel=True
默认模型使用的是CTC model,执行python train.py –help可查看更多使用方式和参数详细说明。
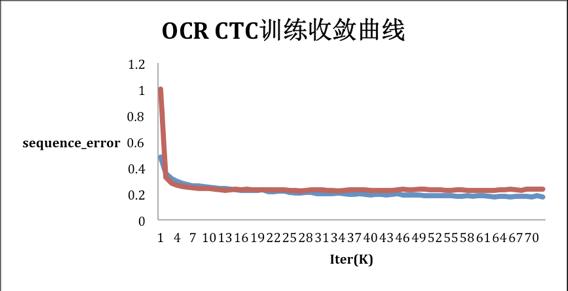
下图为使用默认参数在默认数据集上训练CTC model的收敛曲线,其中横坐标轴为训练迭代次数,纵轴为样本级错误率。其中,蓝线为训练集上的样本错误率,红线为测试集上的样本错误率。测试集上最低错误率为22.0%。
3.5 模型测试
通过以下命令调用评估脚本用指定数据集对模型进行评估:
env CUDA_VISIBLE_DEVICES=0 python eval.py \ –model_path=”./models/model_0″ \ –input_images_dir=”./eval_data/images/” \ –input_images_list=”./eval_data/eval_list”
执行python train.py –help可查看参数详细说明。
3.6 模型预测
从标准输入读取一张图片的路径,并对齐进行预测:
env CUDA_VISIBLE_DEVICES=0 python infer.py \ –model_path=”models/model_00044_15000″
执行上述命令进行预测的效果如下:
———– Configuration Arguments ———–use_gpu: Trueinput_images_dir: Noneinput_images_list: Nonemodel_path: /home/work/models/fluid/ocr_recognition/models/model_00052_15000————————————————Init model from: ./models/model_00052_15000.Please input the path of image: ./test_images/00001_0060.jpgresult: [3298 2371 4233 6514 2378 3298 2363]Please input the path of image: ./test_images/00001_0429.jpgresult: [2067 2067 8187 8477 5027 7191 2431 1462]
从文件中批量读取图片路径,并对其进行预测:
env CUDA_VISIBLE_DEVICES=0 python infer.py \ –model_path=”models/model_00044_15000″ \ –input_images_list=”data/test.list”
3.7 开源预训练模型
飞桨提供的经典的CTC 模型作为 OCR预训练模型,开发者们可以直接下载使用。

https://paddle-ocr-models.bj.bcebos.com/ocr_ctc.zip
注:在本章到示例中,均可通过修改CUDA_VISIBLE_DEVICES改变当前任务使用的显卡号。
特别说明:
以上就是经典OCR算法在飞桨的实现过程,我们也可以看到,这个评测下的数据集,一方面数量不是特别多,另一方面识别难度其实是比较大的(包含不规则的文字,背景噪声,严重的干扰等)。实际使用中,在一些比较受限的典型场景下,如果有丰富的训练数据集,而且数据集比较简单规整的情况下,实际效果会明显改善的,有兴趣的开发者可以自行尝试。
好啦,今天的OCR实战教程就到这里啦~!快快自己动手尝试下吧!
如果您想详细了解更多飞桨PaddlePaddle的相关内容,请参阅以下文档。
https://github.com/PaddlePaddle/models/tree/v1.5.1/PaddleCV/ocr_recognition