数据结构与算法之索引
索引是一种数据结构,它允许数据库系统高效地找到关系中的那些在索引属性上取给定值的元组,而不用扫描关系中所有的元组。
索引文件是用于记录这种联系的文件组织结构,记录了key指向主要数据库文件中的完整记录。索引文件并不需要重新排列记录在磁盘中的顺序。可以通过索引文件高效访问记录中的关键码值。
主码(primary key)是数据库中每条记录的唯一标识。例如身份证号码。
辅码(secondary key)是数据库中可以出现重复的码。辅码索引把一个辅码值与这个辅码值每一条记录的主码值关联起来。
稠密索引对每一个记录建立一个索引项。
稀疏索引不会为每个搜索关键字创建索引。
线性索引
线性索引的优点:
对变长的数据库记录的访问
可以对数据进行高效检索–>排好序的,二分查找
顺序处理,比较好操作,方便批处理
相对于其他索引,节省空间
线性索引的问题:
线性索引太大,存储在磁盘中,可能需要多次访问磁盘。可以使用二级线性索引,即索引的索引
更新线性索引时慢,比如删除或者插入数据时
静态索引
索引结构在文件创建、初始装入记录时生成
一旦生成就固定下来,在系统运行(例如插入和删除记录)过程中索引结构并不改变
只有当文件在组织时才允许改变索引结构。结构一般为多分树
倒排索引
基于属性的倒排
对正文文件的倒排,方法:词索引,全文索引
词索引使用最广泛,一个已经排过序的关键词的列表。其中每个关键词指向一个倒排表,指向该关键字出现的文档集合或者在文档中出现的位置。
倒排文件的优劣:
高效检索,适用于文本数据库系统。
支持的检索类型有限,只能用索引文件中的关键字,需要空间大
动态索引
动态索引结构:系统插入删除记录时,索引本身也会发生改变,用空间换时间。因此查询效率高。
哈希索引
哈希索引hash index基于哈希表实现,只有精确匹配索引所有列的查询才有效。对于每一行数据,存储引擎都会对所有的索引列计算一个哈希码,哈希码是一个较小的值,并且不同的键值的行计算出来的哈希码也不一样。哈希索引将所有的哈希码存储在索引中,同时哈希表中保存指向每个数据行的指针。
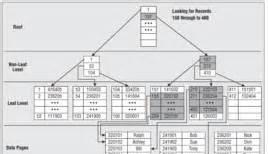
B树balanced tree
B树是平衡搜索多叉树,设树的度为d(d>1),高度为h,那么B树要满足一下条件:
每个叶子结点的高度一样,等于h
每个非叶子结点由n-1个key和n个指针point组成,其中d<=n<=2d,key和point相互隔离,结点两端一定是key
叶子结点指针都为null
非叶子结点的key都是[key,data]二元组,其中key表示索引的键,data为键值所在行的数据。
B树可以使用二分查找法,查找复杂度为h*log(n),一般树的高度不高,查询效率很高。
B树的插入
注意保持性质,必须等高和阶的限制
找到最底层,插入
若溢出,则结点分裂,中间关键码连同新指针插入父结点
若父结点也溢出,则继续分裂
分裂过程可能传达到根结点,则树升高一层
B 树
B 树是B树的一种变种,设d为树的度数,h为树的高度,B 树和B树的不同主要在于:
B 树中的非叶子结点不存储数据,只存储键值
有k个子结点的结点必有k个关键码
B 树比B树更适合外存的索引结构,存储引擎的设计专家巧妙的利用了外存(磁盘)的存储结构,即磁盘的一个扇区是整数倍的page(页),页是存储中的一个单位,通常默认为4k,因此索引结构的节点被设计为一个页的大小,然后利用外存的”预读取”原则,每次读取的时候,把整个节点的数据读取到内存中,然后在内存中查找,内存读取速度是外存读取的几百倍,每个节点中的key个数越多,那么树的高度越小,需要IO的次数越少,因此一般来说,B 树比B树更快,因为B 树的非叶子节点不存储data,就可以存储更多的key。
VSAM
Virtual storage access method 虚拟存储访问方法是IBM的磁盘文件存储访问方法, 首先使用在0S/VS2操作系统中,然后使用在多虚拟存储架构,然后在z/OS
MySQL中InnoDB的索引分类按索引字段个数划分
索引可以包含一个字段,也可以同时包含多个字段。单个字段的索引可以称为单值索引。否则称为复合索引,也称为组合索引或者多值索引。
是否是在主键上建立的索引进行划分
MySQL中是根据主键来组织数据的,所以每张表都必须有主键索引,主键索引只能有一个,不能为null同时必须保证唯一性。建表时如果没有指定主键索引,则会自动生成一个隐藏的字段作为主键索引。
如果不是主键索引,则就可以称之为非主键索引,又可以称之为辅助索引或者二级索引。主键索引的叶子节点存储了完整的数据行,而非主键索引的叶子节点存储的则是主键索引值,通过非主键索引查询数据时,会先查找到主键索引,然后再到主键索引上去查找对应的数据。
根据数据与索引的存储关联性划分
根据数据与索引的存储关联性,可以分为聚簇索引和非聚簇索引(也叫聚集索引和非聚集索引)。聚簇索引也叫簇类索引,是一种对磁盘上实际数据重新组织以按指定的一个或多个列的值排序。整个简洁的说法,这俩的区别就是索引的存储顺序和数据的存储顺序是否是关系的,有关就是聚簇索引,无关就是非聚簇索引。
其他分类唯一索引
顾名思义,不允许具有索引值相同的行,从而禁止重复的索引或键值。系统在创建该索引时检查是否有重复的键值,并在每次使用 INSERT 或 UPDATE 语句添加数据时进行检查, 如果有重复的值,则会操作失败,抛出异常。
需要注意的是,主键索引一定是唯一索引,而唯一索引不一定是主键索引。唯一索引可以理解为仅仅是将索引设置一个唯一性的属性。
全文索引
主要用来利用关键词查询文本,不是MySQL的主要面向场景,使用较少,性能特别差。