有一个很有趣的事情。打开你的淘宝客户端或者PC端的淘宝,点开订单列表,打开几个订单,查看他们的订单号,你会发现什么?
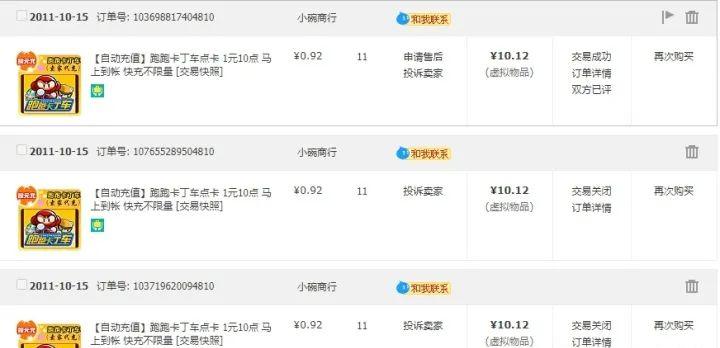
比如这是我最近的3个订单,和10年前的3个订单。其订单号分别是:
124951106536441481012388229886564148101236446127134414810103698817404810107655289504810103719620094810
也许你会惊奇的发现,订单号的后几位好像是一样的。比如我的账号,从10年前到今天,订单号的后四位一直是 4810,那么为什么?这个其实和使用分布式数据库的一个最佳实践相关。
经典的买卖家例子
好多年前就流传着淘宝买卖家的案例……
淘宝中有一个非常重要的表,订单表,他里面存着订单的一些关键信息,例如订单号(order_id)、卖家id(seller_id)、买家id(buyer_id)、商品id等等。有两类查询是这个表上的高频查询:
select*fromorderswherebuyer_id=?select*fromorderswhereseller_id=?
这两个SQL的业务含义一目了然,分别是买家查询自己的订单列表和卖家查询自己的订单列表。
如果我们在单机数据库中做这两条SQL,都知道怎么做。嗯,在 buyer_id和 seller_id上分别建个建索引就可以了:
create index idx_buyer_id on orders (buyer_id);
create index idx_seller_id on orders (seller_id);
在数据库中,空间换时间是一个非常基本的思路,例如加索引。
如果你是用一些分库分表中间件,例如MyCAT之类的产品,对这个表做了分库分表,就需要面临一个跟单机数据库完全不一样的一个问题,该如何选择分库分表键?
一般此类中间件都会告诉你,你哪个列查的最多,就选哪个列做拆分键,例如MyCAT的最佳实践:
总体上来说,分片的选择是取决于最频繁的查询SQL的条件,因为不带任何Where语句的查询SQL,会便利所有的分片,性能相对最差,因此这种SQL越多,对系统的影响越大,所以我们要尽量避免这种SQL的产生。但问题来了,这两类SQL都很高频,选了buyer_id做分库分表键,那按seller_id查就会全库全表扫描;如果按seller_id做分库分表键,那按buyer_id查就会全库全表扫描。
难道鱼和熊掌不可兼得?
一般解决这类的问题的方案是,使用两套订单表,其中一套使用buyer_id做分库分表建,另一套使用seller_id做分库分表键,中间使用binlog来做同步,类似下面的样子:
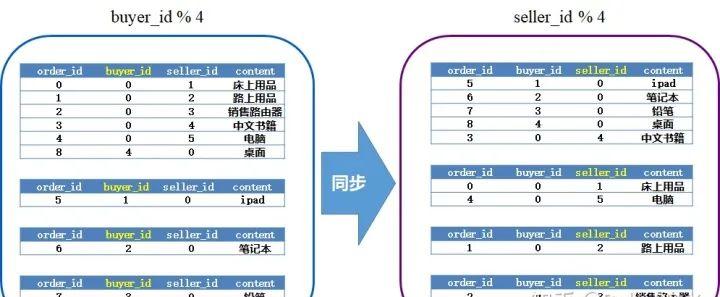
这个方案是OK的,能够落地的,只不过做的过程会有些小痛苦要解决,例如:
这个同步怎么搞啊…,用开源的binlog订阅组件比如canal吗?那这个canal怎么运维啊…好烦
这个同步是有延迟的,延迟代表了数据死不一致的,应用需要有一些容错机制来避免不一致带来的影响,好烦 1
需要在业务里自己控制应该访问哪个表,好烦 2
分库分表下面有很多的mysql,要同时同步这么多的mysql…,好烦 3
做DDL要有些技巧,比如加列先加目标端,减列先减源端…,很多的潜规则,好烦 4
这才是一张表呢!我有一堆类似的场景怎么办!!好烦 10086
我们先不管这些缺点,假设我们已经这样做到了,我们成功的解决了买卖家订单问题。
买卖家问题进阶
我们现在又有了一个新的要考虑的SQL:
select * from orders where order_id = ?
这个SQL作用太简单了,根据订单id查订单详情嘛!
为了做这个SQL,单机里给order_id建索引即可,分库分表应该怎么做?
抢答一个!把订单表再复制一份,使用order_id做分库分表键。
听起来可以,应该能解决问题。但是,这个表多复制一份,就是多一份的代价,比如空间,比如同步链路的维护。所以,有没有更好的方法?
这样,我们还是只需要存两份数据(买家维度和卖家维度),就能同时解决三个维度的查询(买家维度、卖家维度、订单维度)。
所以现在应该明白了,为什么同一个人的淘宝订单后4位是相同的了吧。
小花絮:
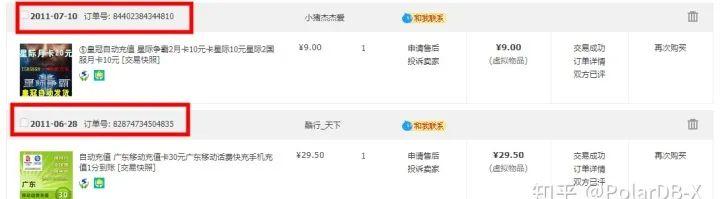
我发现我11年7月10的订单号还是4810结尾,但11年6月28号及之前的订单并没有遵循这个规律。呃…这说明,淘宝应该是在11年的 6.28-7.10 之间做了这个优化。
PolarDB-X中如何实现
OK,回到我们的云原生分布式数据库PolarDB-X。
如果我们在PolarDB-X中要解决上述买卖家问题,应该怎么做?
答案是,我们只需执行以下几条SQL即可:
createpartitiontableorders(order_idprimarykey)createclusteredindexidx_buyer_idonorders(buyer_id);createclusteredindexidx_seller_idonorders(serller_id);
然后?没有然后了啊,这就可以了。
至于按订单id查?订单id本来就是orders的主键,默认就是orders表的分区键,所以没问题的。
这么简单就OK了?为什么?
PolarDB-X中的全局索引
这两条语句发生了什么?实际上,他们在orders表上,创建了两条全局索引。全局索引和单机索引的原理差不多,也是空间换时间的思想,只不过它的数据以索引的key分布在整个集群中。
有一个小问题,建索引的语句里面,有个clustered关键字,这是什么意思?
我们先看,如果不加clustered,会发生什么,例如:
create index idx_buyer_id on orders (buyer_id);
主表:
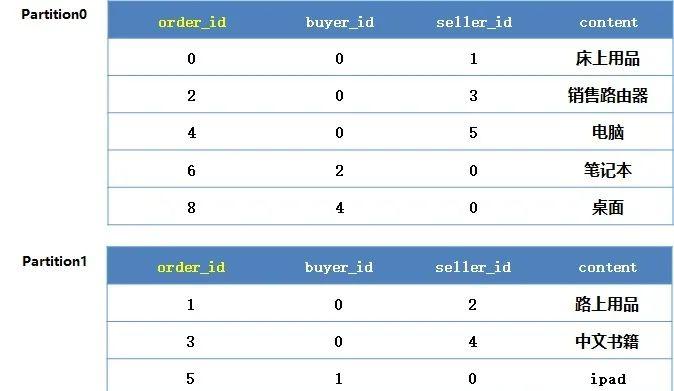
PolarDB-X会定义这样的一个索引结构:
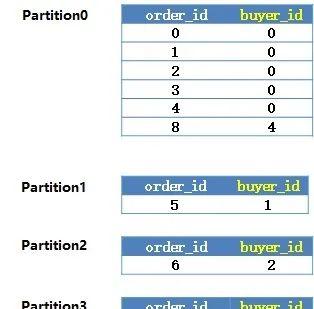
这个索引中,会包含索引的key以及主键两个列,也即order_id与buyer_id。
PolarDB-X在执行select * from orders where buyer_id = ? 的时候,会先根据buyer_id在索引idx_buyer_id上扫描出order_id,再使用order_id到主表上进行回表操作。
听起来好像没有什么问题。
但是,有一点需要考虑。请打开你的订单列表,看一下,你有多少订单:

呃…,我有126页订单,数了下,每页15个,也就是大约1800个订单。
淘宝的订单表的分区数大约是数千这个量级,你会发现,这1800个订单的回表,要覆盖相当比例的分区,似乎跟全表扫描的代价没有什么太大的差异了。
怎么办?
我们为什么要回表?其是是因为,我们的查询是 SELECT *,需要这个表所有的列,而我们的索引里只包含了索引key和主键,因此需要到主表中找到剩下的列。
所以为了不回表,我们想到的一个办法,是在索引表中冗余主表的所有列,用更多的空间换取时间。
所以,一个合格的分布式数据库,不仅需要有全局索引,还需要有聚簇的(clustered)全局索引。
Clustered index就是PolarDB-X中的概念,它相对于普通的全局索引的区别就是,它包含了表的所有列,可以避免回表的代价。
PolarDB-X中如何实现进阶
上面的实现里,我们orders表有三个索引(主键order_id,buyer_id,seller_id),能否使用一些技巧干掉其中一个呢,其实也是可以的。直接贴demo,相信你肯定能明白:
createtableorders(order_idprimarykey)partitonbyhash(buyer_id);createclusteredindexidx_seller_idonorders(seller_id);select*fromorderswherebuyer_id=?//主表select*fromorderswhereseller_id=?//idx_seller_idselect*fromorderswhereorder_id=?andbuyer_id=substr(?,0,10)//使用order_id算出buyer_id小结
OK,总结几条这个例子告诉我们的PolarDB-X的最佳实践:
使用全局索引来解决类似买卖家问题的多维度查询的问题当索引与主表是一对多的关系的时候,考虑使用clustered index来消灭回表的代价巧妙设计一些列(例如订单id),有时可以节省一些空间
from https://zhuanlan.zhihu.com/p/361903384