一个开源的中文车牌识别系统,
我给它取的名字为EasyPR,也就是Easy to do Plate Recognition的意思。我开发这套系统的主要原因是因为我希望能够锻炼我在这方面的能力,包括C 技术、计算机图形学、机器学习等。我把这个项目开源的主要目的是:1.它基于开源的代码诞生,理应回归开源;2.我希望有人能够一起协助强化这套系统,包括代码、训练数据等,能够让这套系统的准确性更高,鲁棒性更强等等。
相比于其他的车牌识别系统,EasyPR有如下特点:
它基于openCV这个开源库,这意味着所有它的代码都可以轻易的获取。
它能够识别中文,例如车牌为苏EUK722的图片,它可以准确地输出std:string类型的”苏EUK722″的结果。
它的识别率较高。目前情况下,字符识别已经可以达到90%以上的精度。
那么,EasyPR是如何产生的呢?我简单介绍一下它的诞生过程:
首先,在5月份左右时我考虑要做一个车牌识别系统。这个车牌系统中所有的代码都应该是开源的,不能基于任何黑盒技术。这主要起源于我想锻炼自己的C 和计算机视觉的水平。
我在网上开始搜索了资料。由于计算机视觉中很多的算法我都是使用openCV,而且openCV发展非常良好,因此我查找的项目必须得是基于OpenCV技术的。于是我在CSDN的博客上找了一篇文章。
令人高兴的是,系统确实能够工作,但是让人沮丧的,似乎也就“仅仅”能够工作而已。在车牌检测这个环节中正确性已经惨不忍睹。
这个事情给了我一拨不小的冷水,本来我以为很快的开发进度看来是乐观过头了。于是我决定沉下心来,仔细研究他的系统实现的每一个过程,结合OpenCV的官网教程与API资料,我发现他的实现系统中有很多并不适合我目前在做的场景。
我手里的数据大部分是高速上的图像抓拍数据,其中每个车牌都偏小,而且模糊度较差。直接使用他们的方法,正确率低到了可怕的地步。于是我开始尝试利用openCv中的一些函数与功能,替代,增加,调优等等方法,不断的优化。这个过程很漫长,但是也有很多的积累。我逐渐发现,并且了解他系统中每一个步骤的目的,原理以及如果修改可以进行优化的方法。
在最终实现的代码中,我的代码已经跟他的原始代码有很多的不一样了,但是成功率大幅度上升,而且车牌的正确检测率不断被优化。在系列文章的后面,我会逐一分享这些优化的过程与心得。
最终我实现的系统与他的系统有以下几点不同:
他的系统代码基本上完全参照了《Mastering OpenCV with Practical Computer Vision Projects》这本书的代码,而这本书的代码是专门为西班牙车牌所开发的,因此不适合中文的环境。
他的系统的代码大部分是原始代码的搬迁,并没有做到优化与改进的地步。而我的系统中对原来的识别过程,做了很多优化步骤。
车牌识别中核心的机器学习算法的模型,他直接使用了原书提供的,而我这两个过程的模型是自己生成,而且模型也做了测试,作为开源系统的一部分也提供了出来。
尽管我和他的系统有这么多的不同,但是我们在根本的系统结构上是一致的。应该说,我们都是参照了“Mastering OpenCV”这本数的处理结构。在这点上,我并没有所“创新”,事实上,结果也证明了“Mastering OpenCV”上的车牌识别的处理逻辑,是一个实际有效的最佳处理流程。
“Mastering OpenCV”,包括我们的系统,都是把车牌识别划分为了两个过程:即车牌检测(Plate Detection)和字符识别(Chars Recognition)两个过程。可能有些书籍或论文上不是这样叫的,但是我觉得,这样的叫法更容易理解,也不容易搞混。
车牌检测(Plate Detection):对一个包含车牌的图像进行分析,最终截取出只包含车牌的一个图块。这个步骤的主要目的是降低了在车牌识别过程中的计算量。如果直接对原始的图像进行车牌识别,会非常的慢,因此需要检测的过程。在本系统中,我们使用SVM(支持向量机)这个机器学习算法去判别截取的图块是否是真的“车牌”。
字符识别(Chars Recognition):有的书上也叫Plate Recognition,我为了与整个系统的名称做区分,所以改为此名字。这个步骤的主要目的就是从上一个车牌检测步骤中获取到的车牌图像,进行光学字符识别(OCR)这个过程。其中用到的机器学习算法是著名的人工神经网络(ANN)中的多层感知机(MLP)模型。最近一段时间非常火的“深度学习”其实就是多隐层的人工神经网络,与其有非常紧密的联系。通过了解光学字符识别(OCR)这个过程,也可以知晓深度学习所基于的人工神经网路技术的一些内容。
下图是一个完整的EasyPR的处理流程:
本开源项目的目标客户群有三类:
需要开发一个车牌识别系统的(开发者)。
需要车牌系统去识别车牌的(用户)。
需要做毕业设计的(学生)。
第一类客户是本项目的主要使用者,因此项目特地被精心划分为了6个模块,以供开发者按需选择。
第二类客户可能会有部分,EasyPR有一个同级项目EasyPR_Dll,可以DLL方式嵌入到其他的程序中,另外还有个一个同级项目EasyPR_Win,基于WTL开发的界面程序,可以简化与帮助车牌识别的结果比对过程。
对于第三类客户,最好在EasyPR的基础上加上自己的创新与调整,这样形成的设计才有价值,有见地,并且能够有底气通过设计会审。
推荐你使用EasyPR有以下几点理由:
正如淘宝诞生于一个购买来的LAMP系统,EasyPR也有它诞生的原型,起源于CSDN的taotao1233的一个博客,博主以读书笔记的形式记述了通过阅读“Mastering OpenCV”这本书完成的一个车牌系统的雏形。
众所皆知,现在是大数据的时代。那么,什么是大数据?可能有些人认为这个只是一个概念或着炒作。但是大数据确是实实在在有着基础理论与科学研究背景的一门技术,其中包含着分布式计算、内存计算、机器学习、计算机视觉、语音识别、自然语言处理等众多计算机界崭新的技术,而且是这些技术综合的产物。事实上,大数据的“大”包含着4个特征,即4V理念,包括Volume(体量)、Varity(多样性)、Velocity(速度)、Value(价值)。
见下图的说明:
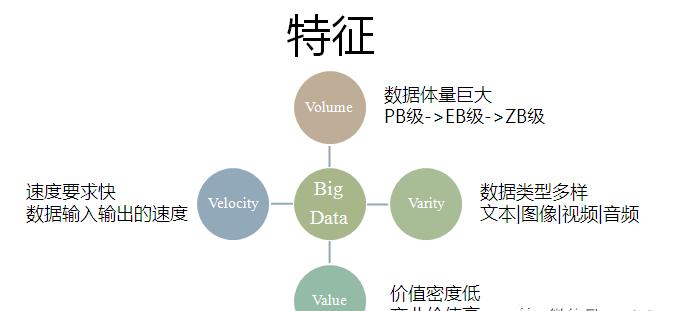
图1 大数据技术的4V特征
综上,大数据技术不仅包含数据量的大,也包含处理数据的复杂,和处理数据的速度,以及数据中蕴含的价值。而车牌识别这个系统,虽然传统,古老,却是包含了所有这四个特侦的一个大数据技术的缩影。
在车牌识别中,你需要处理的数据是图像中海量的像素单元;你处理的数据不再是传统的结构化数据,而是图像这种复杂的数据;如果不能在很短的时间内识别出车牌,那么系统就缺少意义;虽然一副图像中有很多的信息,但可能仅仅只有那一小块的信息(车牌)以及车身的颜色是你关心,而且这些信息都蕴含着巨大的价值。也就是说,车牌识别系统事实上就是现在火热的大数据技术在某个领域的一个聚焦,通过了解车牌识别系统,可以很好的帮助你理解大数据技术的内涵,也能清楚的认识到大数据的价值。
很神奇吧,也许你觉得车牌识别系统很低端,这不是随便大街上都有的么,而你又认为大数据技术很高端,似乎高大上的感觉。其实两者本质上是一样的。另外对于觉得大数据技术是虚幻的炒作念头的同学,你们也可以了解一下车牌识别系统,就能知道大数据落在实地,事实上已经不知不觉进入我们的生活很长时间了,像一些其他的如抢票系统,语音助手等,都是大数据技术的真真切切的体现。所谓再虚幻的概念落到实处,就成了下里巴人,应该就是这个意思。所以对于炒概念要有所警觉,但是不能因此排除一切,要了解具体的技术内涵,才能更好的利用技术为我们服务。
除了帮忙我们更好的理解大数据技术,使我们跟的上时代,开发一个车牌系统还有其他原因。
那就是、现在的车牌系统,仍然还有许多待解决的挑战。这个可能很多同学有疑问,你别骗我,百度上我随便一搜都是99%,只要多少多少元,就可以99%。但是事实上,车牌识别系统业界一直都没有一个成熟的百分百适用的方案。一些90%以上的车牌识别系统都是跟高清摄像机做了集成,由摄像头传入的高分辨率图片进入识别系统,可以达到较高的识别率。但是如果图像分辨率一旦下来,或者图里的车牌脏了的话,那么很遗憾,识别率远远不如我们的肉眼。也就是说,距离真正的智能的车牌识别系统,目前已有的系统还有许多挑战。什么时候能够达到人眼的精度以及识别速率,估计那时候才算是完整成熟的。
那么,有同学问,就没有办法进一步优化了么。答案是有的,这个就需要谈到目前火热的深度学习与计算机视觉技术,使用多隐层的深度神经网络也许能够解决这个问题。但是目前EasyPR并没有采用这种技术,或许以后会采用。但是这个方向是有的。也就是说,通过研究车牌识别系统,也许会让你一领略当今人工智能与计算机视觉技术最尖端的研究方向,即深度学习技术。怎么样,听了是不是很心动?最后扯一下,前端时间非常火热Google大脑技术和百度深度学习研究院,都是跟深度学习相关的。
下图是一个深度学习(右)与传统技术(左)的对比,可以看出深度学习对于数据的分类能力的优势。
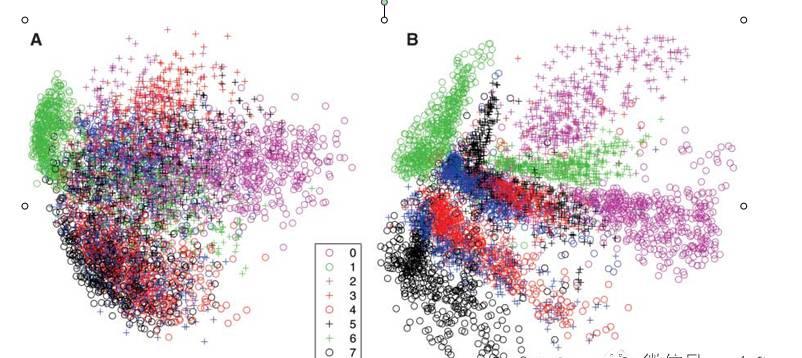
图2 深度学习(右)与PCA技术(左)的对比
总结一下:开发一个车牌识别系统可以让你了解最新的时势—大数据的内涵,同时,也有机遇让你了解最新的人工智能技术—深度学习。因此,不要轻易的小看这门技术中蕴含的价值。
好,谈价值就说这么多。现在,我简单的介绍一下EasyPR的具体过程。
在上一篇文档中,我们了解到EasyPR包括两个部分,但实际上为了更好进行模块化开发,EasyPR被划分成了六个模块,其中每个模块的准确率与速度都影响着整个系统。
具体说来,EasyPR中PlateDetect与CharsRecognize各包括三个模块。
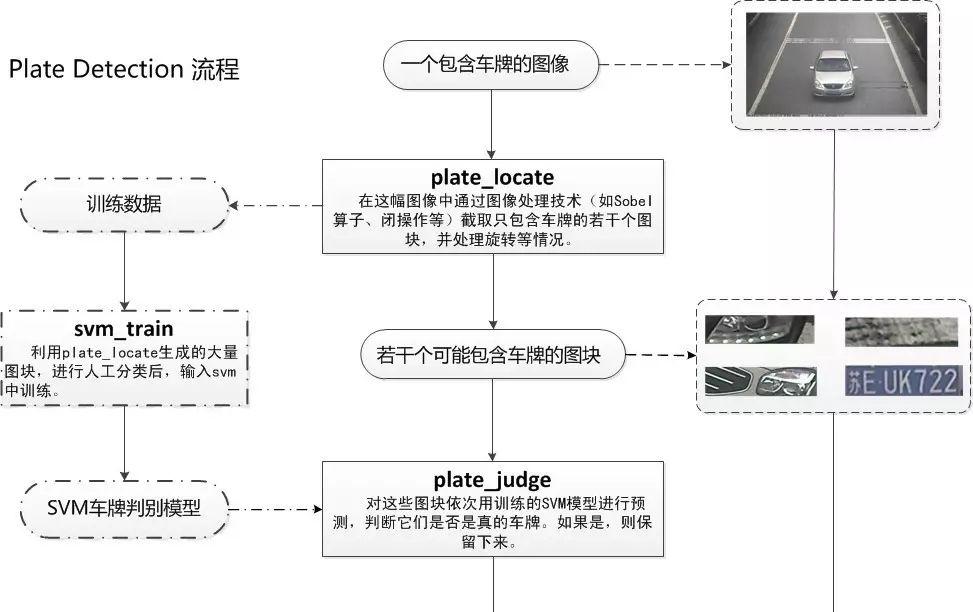
PlateDetect包括的是车牌定位,SVM训练,车牌判断三个过程,见下图。
图3 PlateDetect过程详解
通过PlateDetect过程我们获得了许多可能是车牌的图块,将这些图块进行手工分类,聚集一定数量后,放入SVM模型中训练,得到SVM的一个判断模型,在实际的车牌过程中,我们再把所有可能是车牌的图块输入SVM判断模型,通过SVM模型自动的选择出实际上真正是车牌的图块。
PlateDetect过程结束后,我们获得一个图片中我们真正关心的部分–车牌。那么下一步该如何处理呢。下一步就是根据这个车牌图片,生成一个车牌号字符串的过程,也就是CharsRecognisze的过程。
CharsRecognise包括的是字符分割,ANN训练,字符识别三个过程,具体见下图。
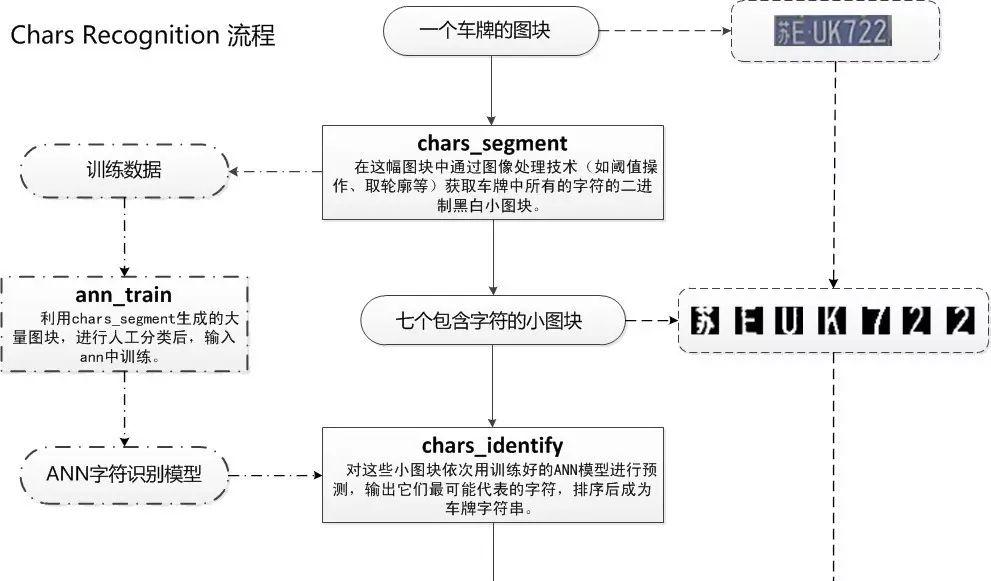
图4 CharsRecognise过程详解
人工智能AI与大数据技术实战