(上)(中)(下)全文目录
引言
广告=>互联网广告:“您好,了解一下”
互联网广告=>计算广告:指哪儿打哪儿!
计算广告四君子:谁在弄潮?
计算广告关键技术:这孙子怎么什么都知道?
广告系统架构:要啥自行车,这里有宝马。
手把手系列之教你搭建一个最小广告系统:mieSys
◆◆◆
5. 计算广告关键技术:这孙子怎么什么都知道?
一句话解释关键技术:没声音,再好的戏也出不来。
广告作为一项商业活动,是需要资本来滋养的。作为整个产业链的金主,只有广告主花钱做广告,使资金流动起来,整个广告行业才能正常运转。所谓关键技术,就是那些能让广告主觉得“这钱花的值”,让媒体网站觉得“这钱挣的快”的技术。具体都有哪些呢?下面我们一一来表。
5.1 合约广告关键技术:受众定向
计算广告发展到合约广告阶段,媒体网站依靠受众定向技术给用户打标签,在实现了媒体网站广告位的时分复用的同时,还提高了广告主的投入产出比,极大的激发了广告主在互联网上做广告的积极性。因此,受众定向是合约广告中的关键技术。
我们知道,只要描述物体的维度足够高,那么世间万物都是独一无二的。在广告系统中,标签就是描述用户的维度。媒体网站为了精准的刻画用户,标签的种类和数量自然也不会少。为了更加直观地了解受众定向技术,我们从用户、上下文和广告三个方面讨论打标签的思路和一般方法。
用户标签:主要用性别、年龄、收入、地理位置、教育程度和用户行为等标签来刻画用户,从而回答“你是谁”的问题。
广告标签:主要用广告主、广告创意、广告计划和广告关键词等标签来刻画广告的相关内容,将广告内容与用户和上下文进行匹配后,从而回答“你该看啥”的问题。
5.1.1 用户标签关键技术
一句话解释静态标签和动态标签的关系:价格围绕价值上下波动。
静态标签(人口属性)
在《计算广告小窥[上]》中,我们曾简要地提到过一种受众定向的方法:
假设我们已经知道一部分用户的真实性别,那么就可以用机器学习中有监督的二分类模型来预测用户性别。首先,我们需要对原始数据进行清洗,合理地处理缺失值和奇异值,并划分训练集、交叉验证集和测试集;其次,要在业务的指导下做特征工程,利用统计或模型的方法构造特征,并进行特征选择和特征组合;然后,我们要选择合适的模型(如SVM等),设置合适的评价标准并进行模型的训练;最后,通过模型调参和模型融合,获得性别预测模型。
动态标签(行为定向)
一句话解释行为定向:唐伯虎喜欢如花多一些,还是凤姐多一些?
“如果一定要比较一下,那唐伯虎是喜欢如花多一些,还是凤姐多一些?”这个看似荒谬的问题,正是行为定向要解决的。如果唐伯虎是异性恋,那他应该是喜欢凤姐多一些的,否则是如花。这也就告诉我们,在行为定向中,判断的标准至关重要。下面我们借助一个例子来分析该用户的动态标签究竟是什么。
标准
单反爱好者
跑鞋爱好者
饮料爱好者
护肤品爱好者
…
25
4
2
1
…
标准
单反爱好者
跑鞋爱好者
饮料爱好者
护肤品爱好者
…
浏览
15
2
0
0
…
标准
单反爱好者
跑鞋爱好者
饮料爱好者
护肤品爱好者
…
搜索
7
16
5
3
…
Step1. 泊松分布
一句话解释泊松分布:猜猜我在哪儿~~~
我们先来介绍下泊松分布。啊啊啊啊!一上来就是数学,我不听我不听我不听,泊松分布是什么鬼?咳咳,那,那就先不丢公式了,咱们看图解决问题好了,下面是泊松分布绘出的曲线图,实际工程中要解决的问题就是找到图中的最高点,如下图:
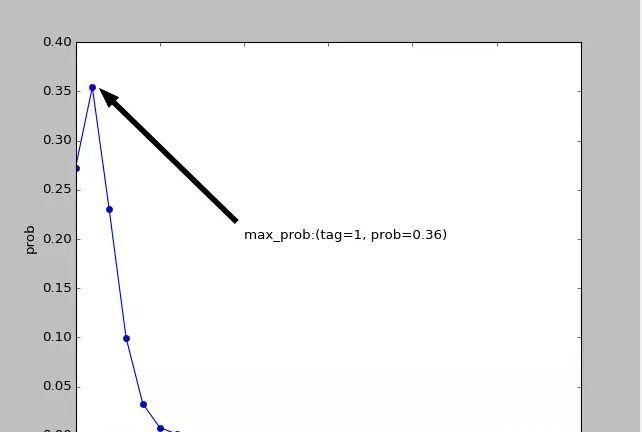
这个肉眼找最高点的过程不要太简单了!!!我们可以看到:图中最高点的纵坐标大约为0.36,而对应的横坐标是1。OK,你就算会用泊松分布了哦!那个,感兴趣的同学们,可以一起来看看对应上图的泊松分布的公式。
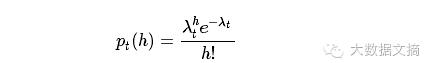 公式相对于图,是有那么点点复杂啦。不过,我们只需知道λt影响泊松分布的形状,一个λt对应一个泊松分布就可以了。这个场景下要做的事情就是找到对应泊松分布图像的最高点。
公式相对于图,是有那么点点复杂啦。不过,我们只需知道λt影响泊松分布的形状,一个λt对应一个泊松分布就可以了。这个场景下要做的事情就是找到对应泊松分布图像的最高点。
Step2. 一个结论
一句话解释这个结论:一个萝卜一个坑。
我们先说一个结论:在一个标准下,所有用户占有的标签,在所有标签上的概率分布是满足泊松分布的。对于这个结论,有兴趣的同学可以参见Stanford 《Introduction to Computational Advertising》讲义Page-81,我们在这里就直接拿来用了。而所谓“标准”,
就对应泊松分布公式中的λt,在我们这里的场景下与用户行为有关。
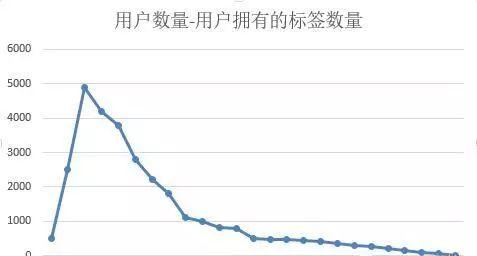
这张图的横轴代表用户拥有的标签数目,纵轴代表兴趣标签数目为x的用户数目,比方说有1个标签的用户有500人,有3个标签的人有5000人。从这张图中我们可以很清楚的看到,用户在所有标签上的分布是满足泊松分布的。但是这里有一个问题,大量用户所呈现出的这种泊松分布,和单独用户的兴趣标签之间有关联吗?我们说,关联不大,因为一个是随机过程,一个是随机事件,想要得到每个用户的兴趣标签,其实是一个复杂的任务。下面我们从统计和投票的角度入手,来看一种用户打标签的方法。
Step3. 最佳标准
一句话解释最佳标准:盲人摸象

Step4. 最终求解
通过广义线性模型,我们找到了最佳标准λt。现在,我们根据该λt画出相应泊松分布,如下图:
回顾Step2中的结论:在一个标准下,用户在所有标签上的概率分布是满足泊松分布的。现在最佳标准下的泊松分布我们已经画了出来,该用户在所有标签中的概率分布也应该符合这个分布的。还是老步骤,我们找最高点所对应的标签,即标签5,所以该用户的动态标签是标签5,问题完美解决。
在学习了泊松分布和机器学习之后,媒体网站终于完成了用户标签的工作,看着那圆圆的饼图,流下了激动了泪水,哽咽着说“嗯..终于..终于可以卖钱了..”没错,流量可以变现了,互联网广告一脚踏进合约广告时代。但是仅仅知道“你是谁”,粒度还是太粗,卖不了好价钱。“要是知道你正在干嘛就好了”媒体网站嘴里嘟囔着,突然脑海中灵光一闪,大叫一声:(图片来自网络)

5.1.2 上下文标签关键技术
一句话解释上下文标签的做法:吃的是URL,挤的是标签。
“我当然知道他在干嘛!我有日志啊!我有他正在访问页面的URL!啊哈哈哈哈哈!”有了用户标签的经验,媒体网站处理起上下文标签来就显得轻车熟路了,总共分两步:第一,根据用户当前页面的URL,抓取用户当前浏览的页面内容;第二,提取页面内容的关键词,作为当前页面的标签。
通过URL获得页面内容是一个典型的爬虫应用,与搜索引擎的爬虫不同的是,广告系统的爬虫只抓取用户请求的页面,而非全网页面。鉴于上述原因,广告系统使用“半在线抓取系统”,该系统有三个特点。第一,仅对用户发起请求的页面进行抓取,节省了时间和成本;第二,将{URL:标签}存储下来,当其他用户发起相同页面请求时,直接返回标签结果,避免重复抓取。第三,考虑到某些频道页面内容可能会更新(例如”旧浪体育”),还可设置合适时间,周期地更新已存页面的标签。
在抓取到页面之后,如何提取标签也有几种常见方法。最简单的是利用规则,在URL层面上人为做映射,例如sports.oldna.com对应的页面标签就是”旧浪体育”。若用户是通过搜索发起的页面访问,还可以根据搜索词作为页面标签。当然,在广告系统使用范围较广的方法还是机器学习中的主题模型,得到页面内容在几个主题上的分布,从而判断页面标签。例如,sports.oldna.com页面内容在”体育”、”财经”和”游戏”三个主题上的概率分布分别为:
体育
财经
游戏
0.85
0.10
0.05
我们可以很容易的看出sports.oldna.com的标签是”体育”。这里值得注意的是,如果想要加工出”体育”、”财经”和”游戏”这种可解释的标签,通常需要采用有监督的主题模型。
5.1.3 广告标签关键技术
普通的广告标签就是广告本身的属性,如所属广告主、广告大小、广告类别和目标人群等,当广告和用户两两匹配时,该广告就会展示给用户。但是,这里我们想说的广告标签是在程序化交易中的“个性化标签”。在《计算广告小窥[上]》中我们提到:“程序化交易是广告主为实现个性化营销举行的海天盛筵。”品尝过个性化营销的甜头之后,广告主就想:“既然这些人是回头客,那各方面表现和这些回头客很像的人,有没有可能也是我的回头客呢?世界那么大,我得去找找这种人。”
look-alike
一句话解释look-alike:比葫芦画瓢。
这个技术的名字还挺洋气呢,英文的,“看起来像”?说白了就是比葫芦画瓢,找到那些看起来像回头客的新用户,行话叫“新客推荐”。这里一定要注意了,千万不能翻译成“看起来像”,那样显得逼格不够,就叫英文的,look-alike~
关于look-alike的具体实现,市面上没有统一的做法,毕竟我们正在经历。这样一来我的心也放下了,因为即便我下面都是胡扯也不一定是错的。
look-alike的核心是按着回头客的样子去找新用户。那简单呀,看看回头客的标签是什么样子,对着去找相同的不就行了?没错,这算一种方法,并且是一种基于规则的方法。但是直觉告诉我们这样做粒度太粗,没有充分考虑到广告主因素,同时经验也告诉我们,基于规则的不如基于模型的效果好,所以我们还可以得出一个基于模型的做法:将某用户是否是潜在用户建模成一个机器学习中的二分类问题,利用回头客数据训练模型,并在新用户上做预测,是就是1不是就是0,也挺好理解的。
“自从广告上了互联网,广告的面貌就焕然一新。造成行业巨变的原因,是因为互联网广告的效果可以被衡量。”
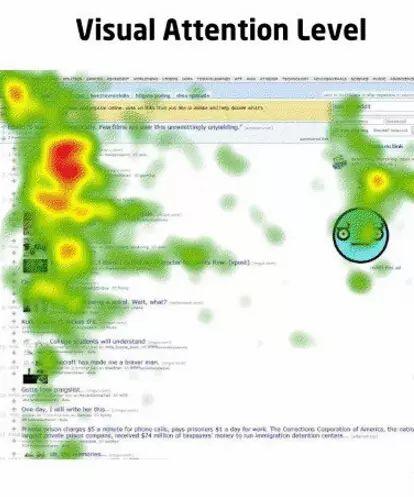
最显眼的地方
一句话解释最显眼的地方:你也是柳岩的球迷?
为了较为直观地描述用户的注意力分布,我找了一张LinkdIn的用户注意力热力分布图。(图片来自网络)
展示广告
展示广告(Display Advertising)是一种以“图片 文字”的方式进行广告宣传的互联网广告形式。从广告触发方式来看,展示广告是媒体网站根据用户历史行为所做的推荐,对用户而言广告是被动接收的,如下图。
搜索广告
搜索广告(Sponsored Search)是一种以“标题 超链接”的方式进行广告宣传的互联网广告形式。从广告触发方式来看,搜索广告是媒体网站针对用户当前检索所做的广告匹配,广告是用户主动发起的,如下图。
<1>线性模型 海量特征
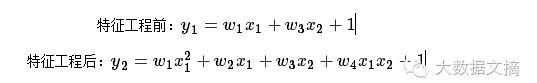
说到FFM,它是FM的一个变种。FM(Factorization Machine):因式分解机是最近比较火的一个模型,这个模型可以挖掘出特征间的非线性关系,并且可以在O(n)的时间内完成计算,非常吸引人。
最后就是深度学习了,在视频、图像和语音领域有较为突出的成果。最新的听说MSRA出了一个152层的网络,OMG…国内在广告领域应用深度学习最早的应该是百度凤巢,低于10层,经过多轮迭代之后效果初显。我自己也在探索阶段,期待能有好的结果,这里就不多说了。

5.3 程序化交易关键技术:出价策略
敢啊!
要是不敢我还怎么写博客嘛,哈哈哈哈哈~~~花钱不要紧,只要能挣就行了呀!那我们就来聊聊如何才能挣的比花的多吧。
5.3.1 出价原则
预算限制:广告主一次就给这么多,超了算你的。
时间限制:到时间花不完就收回去了。
花钱为主:都说了是投资,能花了就别留着。
见好就上:出价与流量品质成正相关。
这些出价原则理解起来没什么难的,但我想要着重说一下第四条见好就上,这才是最关键的部分。如何定义流量品质,又如何出价呢,好戏马上开始。
5.3.2 如何定义流量品质?
5.3.3 如何出价?
终于进入到了最核心的出价环节。按照“见好就上”的原则,出价与流量品质成正相关。那到底是采用线性策略好,还是非线性策略好呢?我们来仔细分析一下。
线性出价策略
非线性出价策略
非线性策略是我想说的重点,主要是想借着这个机会介绍一下限制条件下的优化问题以及其解法,这对于我们做科研或者工程项目都是很有帮助的,下面我们通过KDD’14《Optimal Real-Time Bidding for Display Advertising》一文来了解一下非线性出价策略的来龙去脉。以下内容是我对这篇paper的个人理解,可能并不到位,既然写出来就不怕大家笑话啦,有错就改嘛嘿嘿。
<1>. 文章大意
<2>. 建立模型
在一切开始之前,让我们先考虑清楚要解决的问题是什么,简单来说就一句话:选择合适的出价策略,在预算的限制下实现广告效果最大化,用数学语言描述就是下面这样:
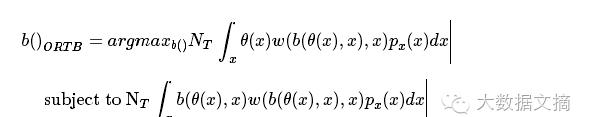

我靠!这一堆是什么玩意儿!你TM在逗我?淡定。。看不懂就对了啊哈哈哈哈!下面我来做一下简化,告诉你这个模型在我眼中长什么样。
b()ORTB=argmaxb()一大坨!
subject to 又一大坨!<B
这下是不是好多了?反正我第一次看到这个模型就长这样,把积分部分当作一大坨,就很容易看懂了。这个模型一共有两个公式,我们一一来看。
b()ORTB=argmaxb()一大坨!
第一个公式是一个等式,等号左边是我们想得到的出价策略函数b()ORTB,等号右边是argmaxb()跟上一大坨,这里argmaxb()的意思是:当后面一大坨取最大值时,返回在最大值情况下的那个b()。将等号左右两边连起来,这个等式所表达的意思就是:当后面一大坨取最大值时,返回在最大值情况下的那个b()作为我们要求的出价策略b()ORTB。这个思路是不是有点眼熟?没错,在前面合约广告关键技术——受众定向中,讲到用户动态特征时我们对泊松分布的处理方式有些类似。综上所述,对于这个等式而言,我们要做的工作就一个:求最大值。
subject to 又一大坨!<B
第二个公式是一个不等式,subject to是“受限于”的意思。在这里,又一大坨!<B想要表达的就是一个限制条件,在等式求最大时插上一脚。还记得我们在高中时学过的线性规划吗,一样的道理。
现在我们的任务已经明确了:在限制条件下求等式最大值。那么这个数学任务和我们的实际问题:选择合适的出价策略,在预算的限制下实现广告效果最大化是怎么匹配上的呢?这就需要去看那两大坨了。那一大坨全都是各种符号,我们看不懂,所以需要一张符号对照表,如下图。为了方便,我再把模型公式再贴一次。

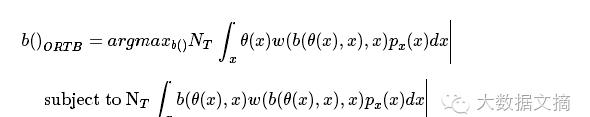
有了符号定义和模型,我们开始聊(啃)一聊(啃)这两大坨吧。先看第一坨,我们从右往左看。
px(x):广告展示机会的概率密度分布,我的理解是在全网所有的竞价中,满足我DSP要求的、或者是我能收到的bid request所占的比例。因此,px(x)??dx的物理意义是“我能收到的展示机会”。
θ(x):θ是赢得此次竞价所能带来的收益(KPI),本文用CTR来衡量,CTR越高,收益就越高。
b(θ(x),x):对于此次展示机会,在能带来收益为θ(x)的情况下,我所出的价格bid。
ω(b(θ(x),x),x):对于此次展示机会,在能带来收益为θ(x)的情况下,我的出价bid能获胜的概率是多少。因此,
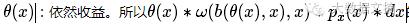 的物理含义是“我出价为bid,赢得这次展示机会后,所能获得的收益”。
的物理含义是“我出价为bid,赢得这次展示机会后,所能获得的收益”。
NT:一次广告推广活动中所有的bid request。
有了上面的解释,我们可以很容易的得出第一坨的物理意义:对于一次广告推广活动中的所有竞价,我使用b()的出价策略所能获得的收益。和等式连起来,即:对于一次广告推广活动中的所有竞价,我使用b()的出价策略所能获得最大收益时所对应的b(),就是我们想要的出价策略。
有了第一坨的经验,第二坨啃起来就容易多了。前面都不变,只有到最后把
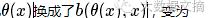
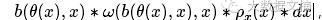
其物理意义为:对于这次广告展示机会,我出价为bid且赢得这次展示机会所花费的预算。所以对于整个广告推广活动而言,所有的出价要小于预算。就这样,我们顺利的将预算限制写进了数学模型里。
好了,分析完两大坨积分的含义之后,我们合起来解释一下该模型(ORTB)所表达的物理意义:在整个广告推广活动中,在出价总和小于预算的限制条件下,当广告收益取得最大值时所对应的那个出价策略,就是我们梦寐以求的出价策略b()ORTB。再来对照一下我们的任务:选择合适的出价策略,在预算的限制下实现广告效果最大化。这下匹配了吧!完美!(图片来自网络)

<3>. 模型求解
截止到目前,我们已经得到了模型表达式,由一个等式和一个不等式组成。接下来我们就要开始求解了:求最大值。最大值有什么好求的?让导数等于0之后带入极值点不就完了?你说的对,如果只有一个等式我们是这么求的,但问题是我们现在除了一个等式,还有一个不等式,这种情况下怎么来求最大值呢?用拉格朗日乘子法。
通过拉格朗日乘子法,我们可以将不等式乘一个参数λ后和等式写进一个公式里(化简过程已省略),得到如下结果。
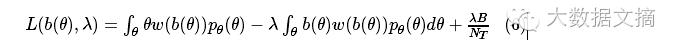
有了这个公式,我们就可以对它进行求导等于0了,可得如下结果:
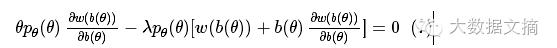
通过化简,可得出价函数b()与胜率函数w()的关系:
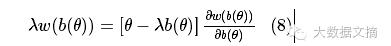 也就是说,我们想要的出价函数b()与胜率函数w()有关,那我们就来看看他们之间到底有什么关系。通过对数据的统计,可以画出出价函数b()与胜率函数w()的关系图像:
也就是说,我们想要的出价函数b()与胜率函数w()有关,那我们就来看看他们之间到底有什么关系。通过对数据的统计,可以画出出价函数b()与胜率函数w()的关系图像:
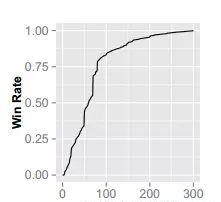
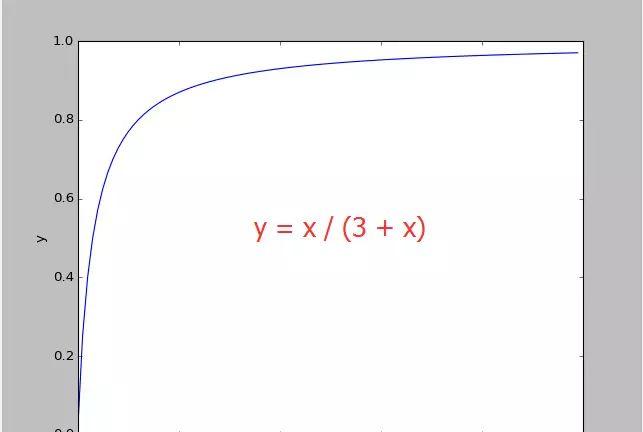
从图像中我们可以看出,出价函数b()与胜率函数w()的关系是非线性的,并且这个曲线的走势和y=xc x很像,我们来对比一下,这里c=3。
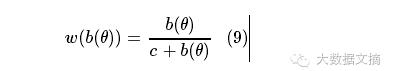
将出价函数b()与胜率函数w()的9式关系带入到倒数为0的7式中,化简可得:
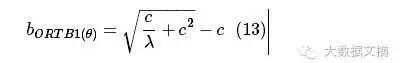 就这样,我们得到了我们的出价策略bORTB()的表达式(公式13)。我们来看看这个公式里有什么。这个公式是由θ,c和λ组成的,其中c和λ都是常量,只有θ一个变量。c是出价函数b()与胜率函数w()之间的系数,λ是拉格朗日乘子,而θ是每次广告展示的收益,按CTR高低来评判。我们来验证一下:CTR越高,由该策略算出的出价也就越高,符合我们的预期,大功告成。
就这样,我们得到了我们的出价策略bORTB()的表达式(公式13)。我们来看看这个公式里有什么。这个公式是由θ,c和λ组成的,其中c和λ都是常量,只有θ一个变量。c是出价函数b()与胜率函数w()之间的系数,λ是拉格朗日乘子,而θ是每次广告展示的收益,按CTR高低来评判。我们来验证一下:CTR越高,由该策略算出的出价也就越高,符合我们的预期,大功告成。
我们来梳理一下思路。在建模环节,我们已经得到了我们所需的模型:一个等式 一个不等式。我们的任务是要求等式的最大值,通常方法直接对等式求导等于0即可,由于我们这里是一个限制条件下的优化问题,所以需要用到拉格朗日乘子法,将限制条件写进等式中,构造出一个新的公式(公式6)。对于新的公式,我们就可以用求导等于0了(公式7)。在化简过程中,我们发现了出价函数b()与胜率函数w()存在着数学关系(公式8),为了消元,我们按照实际数据的分布构造出出价函数b()与胜率函数w()的表达式(公式9),将公式9带入公式7,继续化简就得到了我们的出价策略:bORTB(),剩下的工作就是根据数据去拟合λ和c即可,这里就不多说了。这里需要强调的是,这种限制条件下的优化方法在统计与机器学习中是很常见的,例如SVM的推导过程,感兴趣的同学可以试一试,其实并不难。
<4>. 结果分析
既然有了公式,那我们就来看看ORTB的出价有什么特点吧。
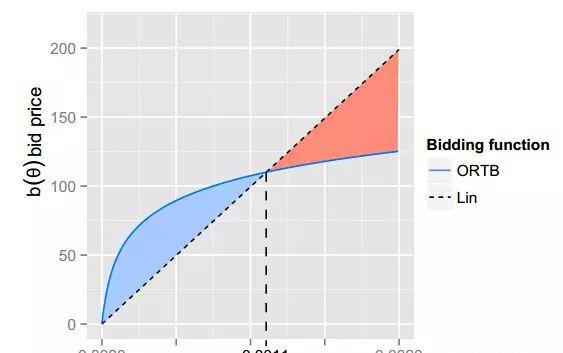
我们可以很直观的看出,我们所得到的出价策略是一个非线性的。横坐标θ代表了广告展示计划的品质,ORTB会对低价值的展示机会出高价,这样的结果能为我们带来什么,谁会去要那些低价值的展示机会呢?我们来看下面这张图。
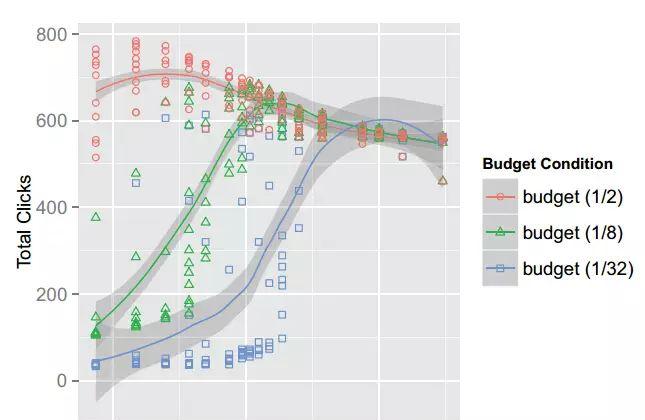
我们知道,“二八原则”是客观存在的,在广告主中也不例外,如果能吸引这80%的小广告主参与程序化交易,玩家一多,需求自然更多。为了满足金主的需求,势必会推动相关计算技术的发展,这对于计算广告的未来而言,是一件好事。
讲完了非线性出价策略,程序化交易中的关键技术也接近尾声了。出价策略之所以重要,是因为就是DSP赖以生存的看家本领,没有这些真本事,DSP是走不了多远的。
到此,计算广告关键技术就讲完了,啥也不说了,给自己鼓个掌吧(图片来自网络)。

受篇幅所限,原定于本篇要完成的第五章和第六章只好放在《计算广告小窥[下]广告系统架构:要啥自行车,这里有宝马。》中来写了。在下篇中,我们将介绍一个通用的广告系统架构,在领略在线和离线过程的同时,还将见到时下工业界最火热的技术,譬如Nginx,Hadoop,Spark等在计算广告领域的位置与应用。
好了,我们《计算广告小窥[下]》再见!
◆◆◆
后 话
对相关内容感兴趣的同学,还请参阅刘鹏和王超老师所著《计算广告》,有更精准的定义、描述与更详细的讲解。
到这里,《计算广告小窥[中]》就结束了。接下来的部分还会介绍一套通用的广告架构,并亲手实现一个最小广告系统。计算广告小窥[下]》将在明天在大数据文摘陆续推出,敬请期待。
或者通过群号码285273721进群