《如何用数据分析解决实际问题》这本书提及的营销数据分析方法与巫女在《【营销专栏】你真的认真分析过营销数据吗?》中提及的有部分相似。巫女那篇碍于法律保护,无法将文中的案例进行展示。
但柏木吉基在本书中通过引用日产的数据对方法论进行了生动阐述,最后还把整个逻辑故事线串联起来,将其屡试不爽的方法论倾囊相授。无论你是否有统计学基础,看了都会得到一些启发。
第一步:锁定目标 GAP ANALYSIS
这个目标一定不是宽泛的一句话,而是在既定目标范围下,量化具体要达到什么程度。例如:要将人民路分店的MODELY车型在20-30岁男性客群中的销量提升20%。
第二步:假设可能的原因
为确保所列举的原因要足够MECE(Mutually Exclusive Collectively Exhaustive 相互独立,完全穷尽),一方面,可借助各类分析框架,如流程图、损益表及营销4P理论等各类WHY模型(对市场营销分析框架感兴趣的读者可以进入巫女的《解密商业分析思路》免费获得完整的分析框架);另一方面,尽可能多的获取数据/信息,尤其是外部数据/信息,以免思路被有限的资源所束缚,导致整个分析过程沦为刻意验证自己经验/想法正确性的过程。
假设的范围决定接下来的检验范围,决定了后面的分析质量。如果假设范围过窄,即便得到答案也并非最佳答案。
第三步:找到“问题关键”,通过分解数据
技巧1:WHAT型假设
随着将问题的逐步拆解,最后会呈现出“树状”(下图)。这个分析过程看似一目了然,实则很考验人们的思考水平。
技巧2:趋势
这个不用多说了,如果不结合趋势,就没法对未来做出预判,数据分析的意义也就不大了。不过话虽如此,人们在实操中仍经常忽略分析趋势。
举个例子,很多人在做政策分析的时候,就很喜欢局限在当下。
技巧3:“快照”
这是指截取某个期间的情况,用诸如平均值一类的指标,轻松把握大致情况。但注意,我们最常用的“快照”平均数法存在诸多陷阱:
#1. 牺牲了原始数据
巫女在《【营销专栏】你真的认真分析过营销数据吗?》也提到过,只有当所有数据都呈现完美的正态分布,平均数才能代表整体。所以还要结合分析中位数、离散情况去了解数据的全貌。
#2. 牺牲了数据构成
只看平均数而不了解数据构成,很容易导致分析结果南辕北辙。
例如,一家面馆老板想通过让客户打分的方式,了解两款浇头——油炸豆腐和天妇罗面渣哪个更受欢迎。油炸豆腐平均获得67分,天妇罗面渣平均获得60.8分,所以结论是,油炸豆腐更受欢迎。
但当老板的店员对乌冬面和荞麦面进行调研的时候,发现天妇罗面渣搭配了其中任意一种面后,所获得的分数都比油炸豆腐高,所以理应得出结论是:天妇罗面渣更受欢迎。
这种矛盾现象就是有名的“辛普森悖论”。如果我们使用了老板或者店员的任意一种方法,所获得的结果截然相反。所以,不能只看平均数。
问题出在哪了呢?出在了打分人数(即:样本数)分配不均衡上。
其实人们普遍认为这家店的乌冬面比荞麦面好吃很多,无论使用哪种浇头。在老板的调研中,乌冬面的食客占比更大,于是相对拉高了油炸豆腐的平均分。
因此,如果不对样本数据的综合构成进行分析,很可能丢掉关键问题。
#3. 牺牲了数据波动与极值
可能有人会说了,标准差可以反映数据波动情况,是不是可以解决上述问题?
通常讲不太可以,因为其与平均数法存在一个共同缺陷:要求数据呈完美的正态分布,极值较少。显然,实际业务数据很难满足。
那如何观察、判断波动?
方法2:通过比较“偏差值”与平均数,来了解某项数据的真实水平。偏差值=(得分-平均分)*10 / 标准差 50。如果偏差值大于平均数,则说明该得分相对不错。
方法3:直方图。直方图能够让人一目了然的把握数据波动情况,但有时仅从视觉判断也容易产生误差。
方法4:“变异系数”不仅能够弥补上述误差,还能弥补标准差的另一个缺陷——不同规模间比较会失效。因为变异系数=标准差/平均值。但注意,变异系数只用作比较,单独使用无效。
第四步:锁定“原因”,通过交叉视点
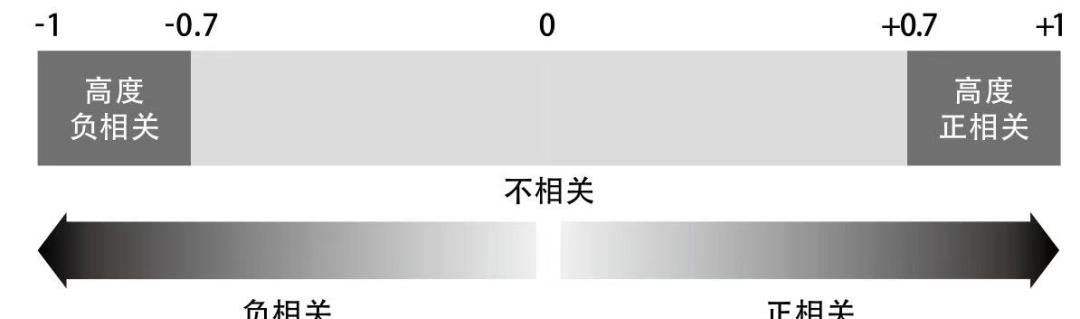
#1. 相关性
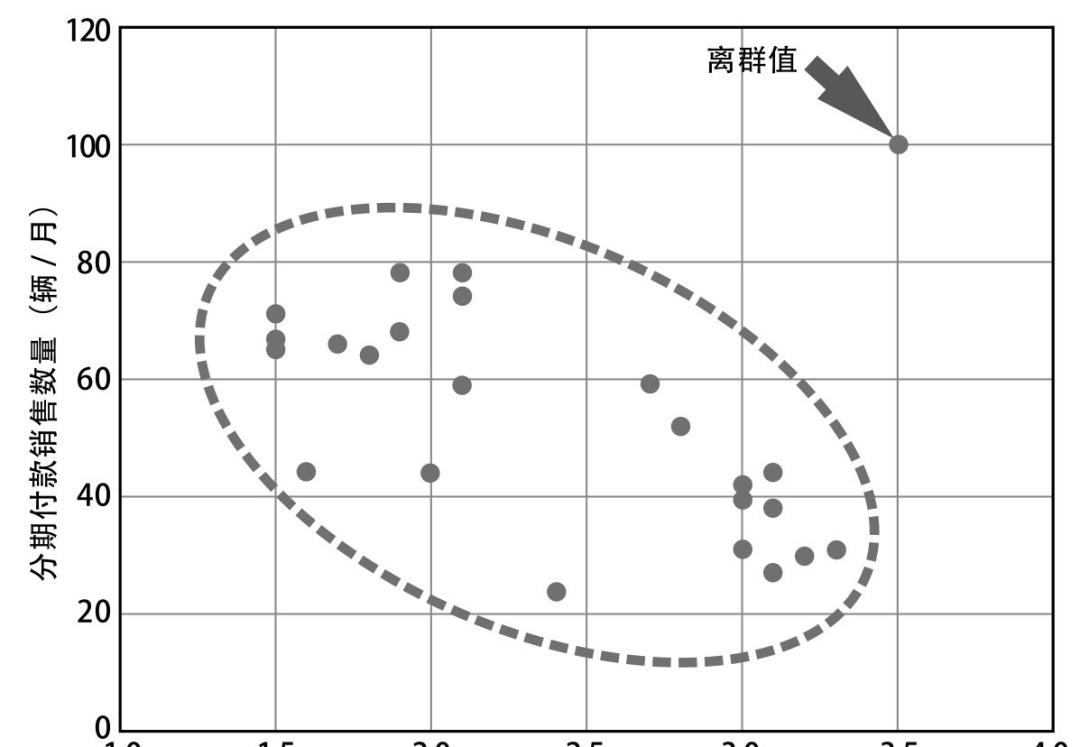
通过相关系数,判断来个数据间的关联程度(下图),有时“正负0.7”也可以宽限至“正负0.5”。
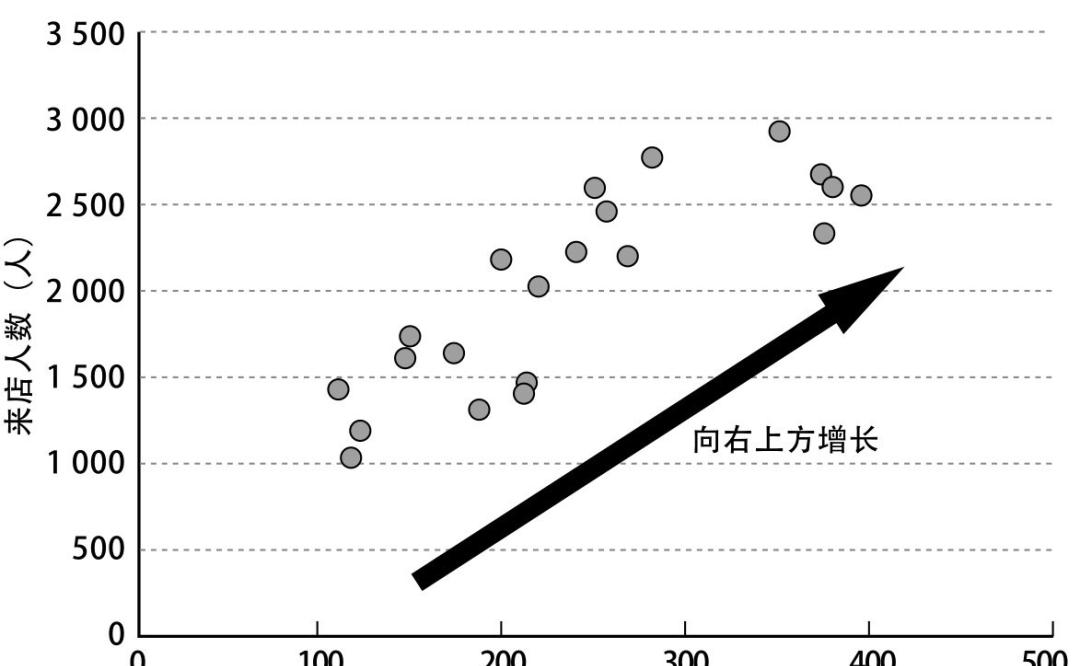
如果两组数据间呈显著的正相关,在坐标轴上可视化后会呈现下图的排布,否则,会呈现零散不规则分布。
注意,锁定原因的过程也需要假设,然后通过相关性去验证你的假设。
相关性分析也有一些陷阱:
1. 相关≠直接的因果关系,二者之间可能存在一串因果链,也可能存在其他的中介(新的要素)。
2. 数据范围可能影响相关性结果。例如,当给员工的培训次数小于10次的时候,其提供的服务质量与受训次数并无相关性,但当培训次数达到10次以上的时候,二者产生了显著的相关性。
3. 别轻易剔除离群值。这个往往出现在数据清洗阶段。很多人刻意为了让数据呈现明显的规律,直接在数据上看到离群的就剔除。这样很容易忽视一些重要信息,例如发现害群之马或凤毛麟角。
第五步:制定对策,依据方程
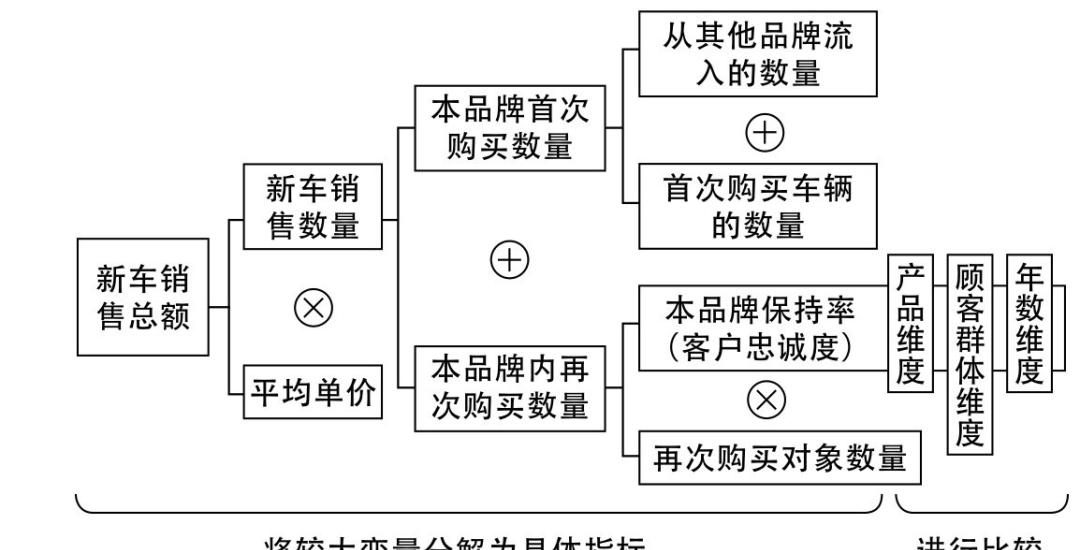
上面提过了,如两个因素高度相关,则数据散点图会呈现出回归直线状,可通过一元回归方程(当然也可能是二元)表达(下图)。
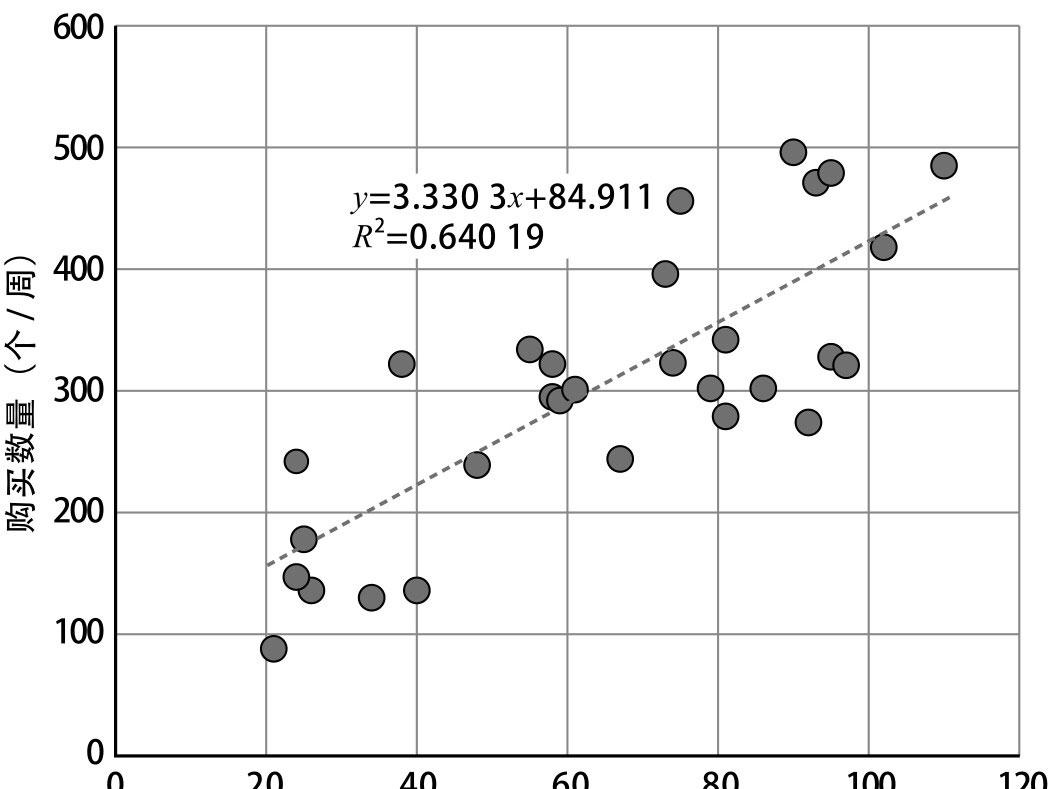
上图为例,购买视频的数量(个/周)=3.33*公布视频的频率(次/周) 84.9。R^2是该方程的可信度,是相关系数的平方。在这里相关系数是0.8,高度相关,所以R^2约为0.64。即:在购买数量(y)中,有64%可以通过公布视频的频率(x)得到解释。
在实际工作中,也可以通过对y的要求,倒推对x的要求。即:要想曝光量(公布视频的频率)达到多少,每周至少要购买几个视频。
一元回归分析时注意:数据间关系越复杂,越不符合严密的线性关系。是否采用离群值,如何选定数据范围,对结果影响非常大。
综上,我们通常通过相关分析判断关联的紧密程度,通过回归分析判断影响程度的大小。
举几个常见的例子:
#1.对比成本和收益
A店:每周到店人数=3.73*推广费 273.6
B店:每周到店人数=2.86*推广费 569.3
说明A店的推广费每增加1个单位,到店人数可增加3.73人,B店同理,所以在A店增加推广费的收益更大。
且理论上,如推广费均为0,A的自然到访更多。当然,仅限理论,需要测试结果做支撑。
#2. 合理分配资源
基于上述方程,如A店想实现每周到店800人的目标,则需约141个单位的推广费。
#3.制定合理的KPI
最后,在采取措施时,我们还可以使用模型,通过综合评估不同措施的实施难易度及其对目标影响的大小,来制定措施的实施顺序。
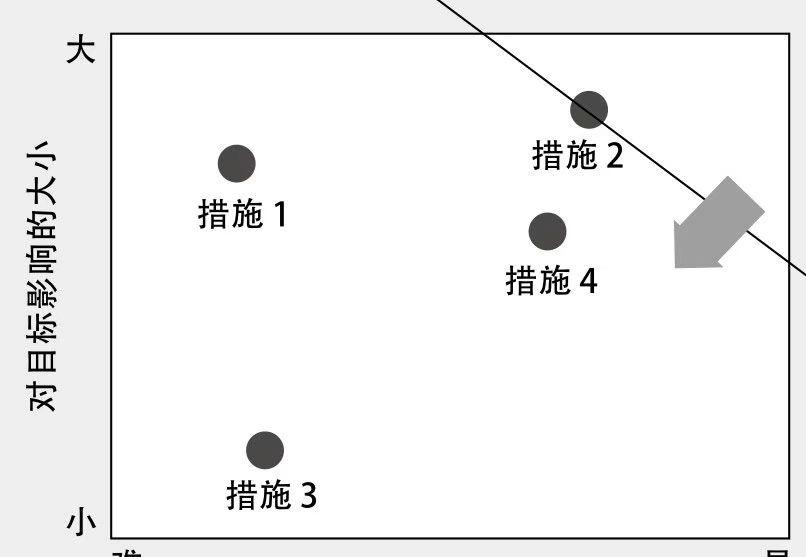
以上就是全书的核心内容了,巫女略微调整了逻辑,使之更方便理解。
但必须提醒下,该方法实施起来有两大难点:
读懂理论和实操的差距较大。现实中对分析者的统计基本功(EXCEL、SPSS等软件均可,书中有具体操作步骤)、商业思维、逻辑思考、对企业业务及行业的洞察方面均有一定要求门槛。
在实施过程中很可能会碰壁。因为很多组织/领导者,尤其在比较传统的行业如汽车、房地产、能源类企业,都很难从心理上接受这种分析方法,甚至持反对态度,抵触情绪。
所以,要拉他们进来参与讨论,甚至花时间去详细介绍方法,使之信服。再者,就是要了解企业内部的政治背景及各利益主体的诉求,否则分析结果再有效都可能被否决,因为你很容易动到别人的奶酪。这也是企业往往通过第三方咨询机构,而非通过内部,解决问题的原因之一。
此外,本书未专门提及背后的分析逻辑框架。鉴于这是统计分析背后的精髓,感兴趣的读者可以查看巫女另一篇文章《【商业专栏】像这样思考,解决办法水到渠成》。
??《如何用数据分析解决实际问题》
推荐指数:????????????????????
个人理由:行之有效的方法论,打破绝大多数人对数据分析的陈旧偏见。
推荐读法:统计学小白:扫读→学习统计学基础→复读→练习→复读;有统计学基础的:扫读;统计学应用大神:蜻蜓点水。