阅读本文大概需要 8分钟

索引
视图
导入
导出
2、步骤
在正式开始本实验内容之前,需要先下载相关代码。
该代码可以新建一个数据库,名为 mysql_shiyan ,并在 mysql_shiyan 数据库中建 4 个表(department,employee,project,table_1),然后向其中插入数据。
其中创建数据库和数据表语句可以在这里下载。
gitclonehttps://github.com/rongweihe/MoreThanCode/tree/master/mysql_shiyan/SQL;下载完成后,输入命令开启 MySQL 服务并使用 root 用户登录:#打开 MySQL 服务sudo service mysql start#使用 root 用户登录mysql-uroot下载的 SQL6 目录下,有两个文件 MySQL-06.sql 和 in.txt,其中第一个文件用于创建数据库并向其中插入数据,第二个文件用于测试数据导入功能。如果之前的数据库还存在,首先把 mysql_shiyan 数据库删掉,执行命令:source/home/MySQL_05_01.sql;输入命令运行第一个文件,搭建数据库并插入数据:mysql>source/home/mysql_sql/SQL6/MySQL-06.sql;
3、索引
索引是一种可以提高数据库检索速度的一种数据结构。它的作用相当于一本书的目录,可以根据目录中的页码快速找到需要的内容。
当表中有大量记录的时候,若需要对表进行查询,没有索引的情况下,走的是全表搜索;将所有记录一一取出,和查询条件进行对比,然后返回满足条件的记录。
这样的方式会执行大量磁盘 I/O 操作,并花费大量数据库系统的时间。
而如果在表中已经建立索引,在索引中找到符合查询条件的索引值,通过索引值就可以快速找到表中的数据,可以大大地加快查询的速度
对一张表中的某个列建立索引,有以下两种语句格式:
ALTERTABLE表名字ADDINDEX索引名(列名);CREATEINDEX索引名ON表名字(列名);
我们用这两种语句分别建立索引:
ALTERTABLEemployeeADDINDEXidx_id(id);#在employee表的id列上建立名为idx_id的索引CREATEINDEXidx_nameONemployee(name);#在employee表的name列上建立名为idx_name的索引
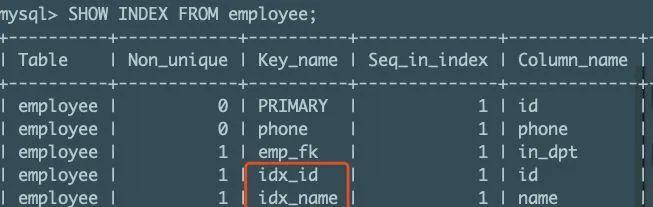
索引的效果是加快查询速度,当表中数据不够多的时候是感受不出它的效果的。这里我们使用命令 SHOW INDEX FROM 表名字; 查看刚才新建的索引:
在使用 SELECT 语句查询的时候,语句中 WHERE 里面的条件,会自动判断有没有可用的索引。
比如有一个用户表,它拥有用户名(username)和个人签名(note)两个字段。其中用户名具有唯一性,并且格式有一定的限制,我们给用户名加上一个唯一索引;个性签名格式多变,而且允许不同用户使用重复的签名,不加任何索引。
这时候,如果要查找某一用户,使用语句
select*fromuserwhereusername=?和select*fromuserwherenote=?
性能是有很大差距的,对建立了索引的用户名进行条件查询会比没有索引的个性签名条件查询快几倍,在数据量大的时候,这个差距会更大。
但是也要注意:一些字段不适合创建索引,比如性别,这个字段存在大量的重复记录,索引带来的效率在这里就不太合适,甚至会拖累数据库,导致数据冗余和额外的 CPU 开销。
具体原因涉及到聚集索引和非聚集索引,我们后面在深入展开。
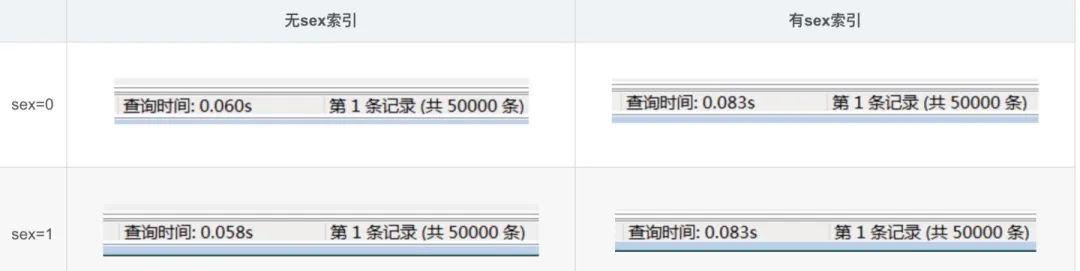
比如下面的例子:可以看到相同的 sql,加索引之后比不加索引慢许多。
 4、视图
4、视图
视图是从一个或多个表中导出来的表,是一种虚拟存在的表。它就像一个窗口,通过这个窗口可以看到系统专门提供的数据,这样,用户可以视图是从一个或多个表中导出来的表,是一种虚拟存在的表。
它就像一个窗口,通过这个窗口可以看到系统专门提供的数据,这样,用户可以不用看到整个数据库中的数据,而只关心对自己有用的数据。
注意理解视图是虚拟的表:
数据库中只存放了视图的定义,而没有存放视图中的数据,这些数据存放在原来的表中;
使用视图查询数据时,数据库系统会从原来的表中取出对应的数据;
视图中的数据依赖于原来表中的数据,一旦表中数据发生改变,显示在视图中的数据也会发生改变;
在使用视图的时候,可以把它当作一张表。
创建视图的语句格式为:
CREATEVIEW视图名(列a,列b,列c)ASSELECT列1,列2,列3FROM表名字;
可见创建视图的语句,后半句是一个 SELECT 查询语句,所以视图也可以建立在多张表上,只需在 SELECT 语句中使用子查询或连接查询。
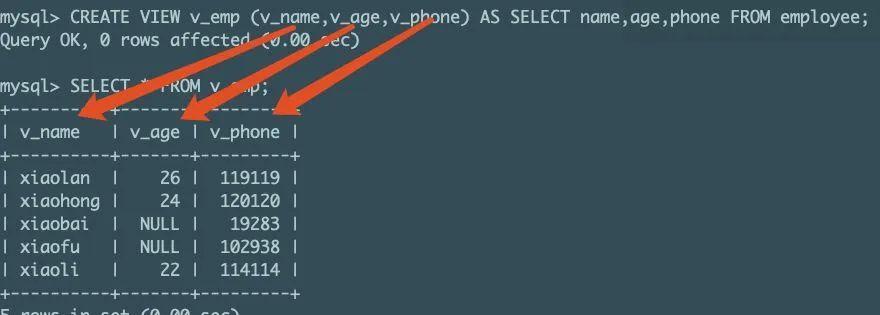
现在我们创建一个简单的视图,名为 v_emp,包含 v_name,v_age,v_phone 三个列:
CREATEVIEWv_emp(v_name,v_age,v_phone)ASSELECTname,age,phoneFROMemployee;
5、导入
我们来学习一下,如何导入一个纯数据文件,该文件中将包含与数据表字段相对应的多条数据,这样可以快速导入大量数据,除此之外,还有可以用 SQL 语句的导入方式,语法为:source *.sql 这是实验中经常用到的。
两者之间的不同是:数据文件导入方式只包含数据,导入规则由数据库系统完成;SQL 文件导入相当于执行该文件中包含的 SQL 语句,可以实现多种操作,包括删除,更新,新增,甚至对数据库的重建。
数据文件导入,可以把一个文件里的数据保存进一张表。
导入语句格式为:
LOADDATAINFILE’文件路径和文件名’INTOTABLE表名字;
现在 SQL6 目录下有一个名为 in.txt 的文件,我们尝试把这个文件中的数据导入数据库 mysql_shiyan 的 employee 表中。
由于导入导出大量数据都属于敏感操作,根据 mysql 的安全策略,导入导出的文件都必须在指定的路径下进行,在 mysql 终端中查看路径变量:(我这里设置了任意目录可以导入)
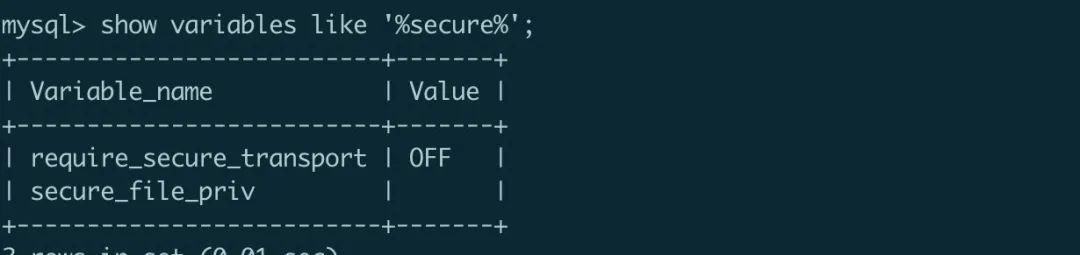
注意到 secure_file_priv 变量指定安全路径 ,要导入数据文件,需要将该文件移动到安全路径下。
secure-file-priv 参数是用来限制mysql导入导出到哪个目录的。
查阅官方文档找到secure-file-priv的值有以下几种情况:

使用命令 vim SQL6/in.txt 查看 in.txt 文件中的内容:
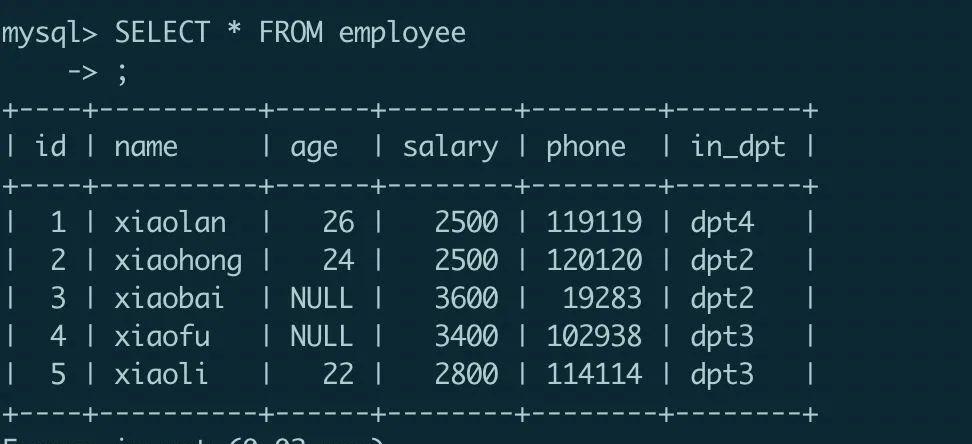
可以看到其中仅仅包含了数据本身,没有任何的 SQL 语句再使用以下命令以 root 用户登录数据库,再连接 mysql_shiyan 数据库:查看一下没有导入数据之前,employee 表中的数。
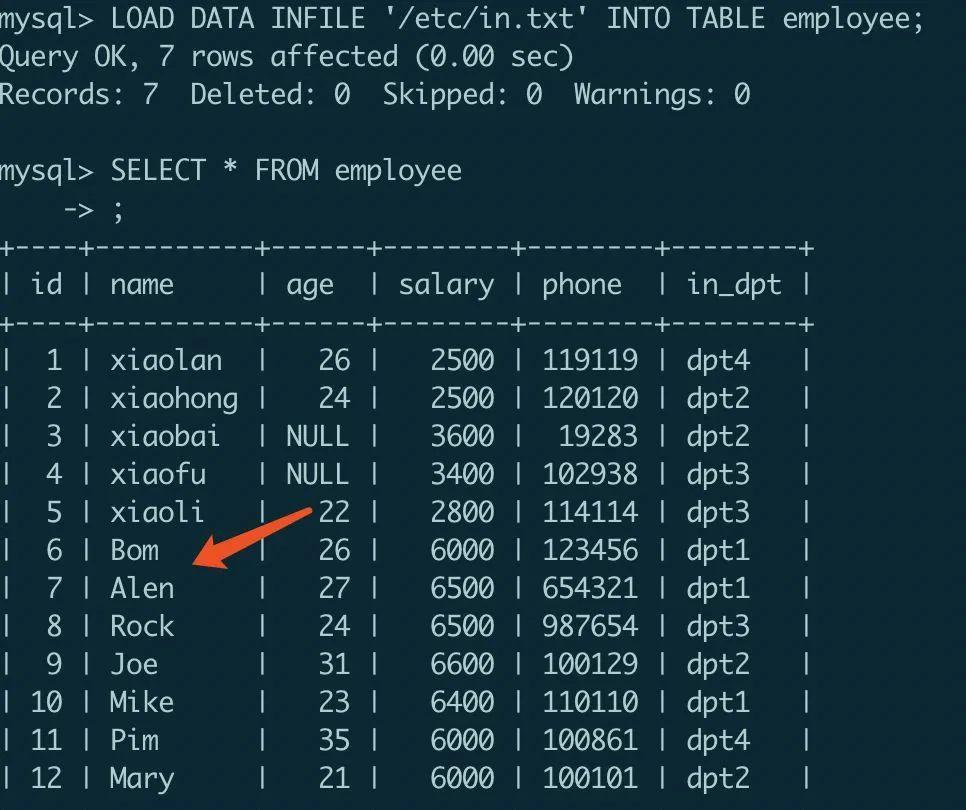
现在执行导入语句,文件中的数据成功导入 employee 表:
 6、导出
6、导出
导出与导入是相反的过程,是把数据库某个表中的数据保存到一个文件之中。导出语句基本格式为:
SELECT列1,列2INTOOUTFILE’文件路径和文件名’FROM表名字;
注意:语句中 “文件路径” 之下不能已经有同名文件。
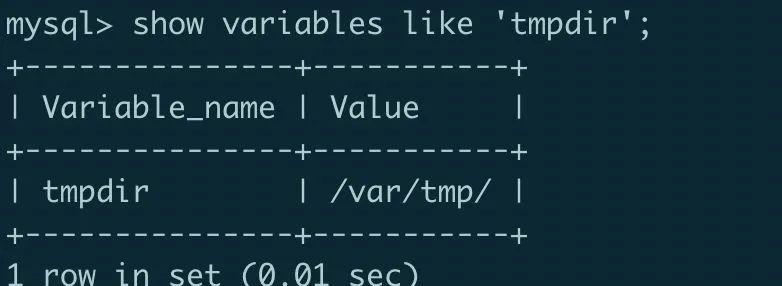
如果导出报错,可能是 MySQL 没有权限对相应目录进行操作, 查看系统变量 tmpdir, 如下所示,tmpdir 变量指定路径为 /tmp。
现在我们把整个 employee 表的数据导出到 /var/tmp/mysql-files/ 目录下,导出文件命名为 out.txt 具体语句为:
SELECT*INTOOUTFILE’/var/tmp/mysql-files/out.txt’FROMemployee;

用 vim 可以查看导出文件/var/tmp/mysql-files/out.txt 的内容:也可以使用 sudo cat /var/tmp/mysql-files/out.txt 命令查看。
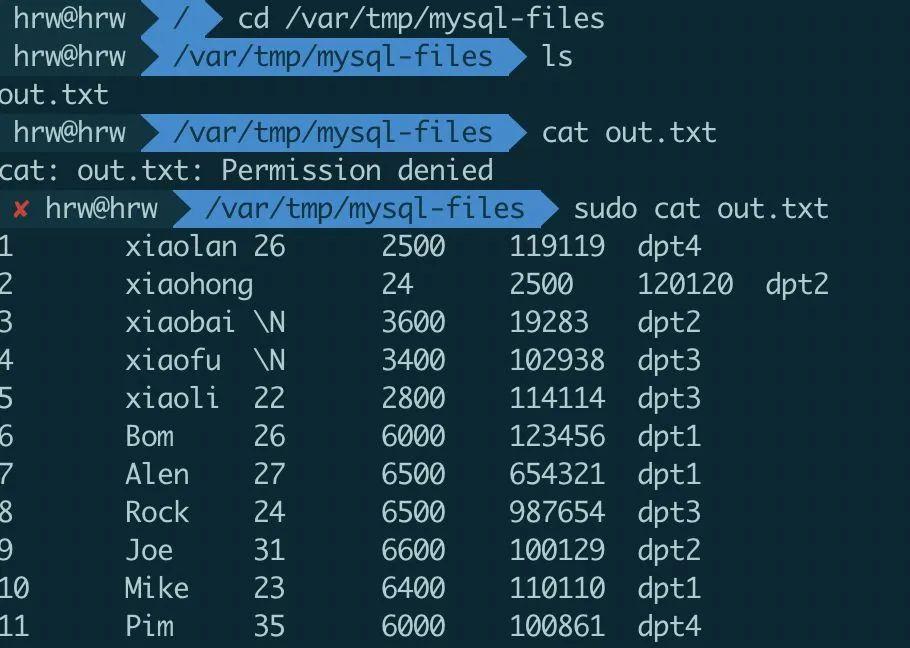
数据导出成功。
7、总结
在本节实验中我们学习了索引、视图、导入和导出的知识。
今天的学习就到这里啦。
祝大家周末愉快~
PS:如果大家在阅读的过程中,有什么建议和看法,非常欢迎在下方留言,每个留言我都会认真看的
 。
。
参考:
https://www.shiyanlou.com/courses/9
推荐阅读:
从零开始学 MySQL — 数据库和数据表操作
从零开始学 MySQL — SELECT 语句详解
从零开始学 MySQL — 常见的五种约束条件
从零开始学 MySQL — 创建数据库并插入数据
从零开始学习 MySQL 系列–基础三剑客