我们唯一的恐惧,就是恐惧本身
— 富兰克林·罗斯福
什么是cache
Cache存储器也被称为高速缓冲存储器,位于CPU和主存储器之间。之所以在CPU和主存之间要加cache是因为现代的CPU频率大大提高,内存的发展已经跟不上CPU访存的速度。在2001 – 2005年间,处理器时钟频率以每年55%的速度增长,而主存的增长速度只是7%。在现在的系统中,处理器需要上百个时钟周期才能从主存中取到数据。如果没有cache,处理器在等待数据的大部分时间内将会停滞不动。
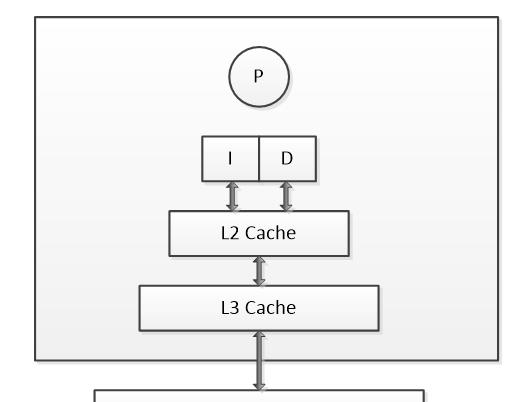
图1 现代处理器存储层次示意图
Cache的基本原理
Cache的容量跟主存比起来要小得多,尤其是离CPU最近的L1,通常是几十KB大小。一般L3也就是几十MB大小,跟现在以GB为单位的内存比起来差了好几个数量级。那为什么加入cache还能提高性能呢?
设想一下,如果提前把CPU接下来最有可能用到的数据存放在cache中,那么CPU就可以在很短的时间内得到数据了,一般如果L1命中的话,CPU在2-3个时钟周期内就会得到想要的数据。那么CPU是如何预测到接下来将要用到的数据的呢?其实这种预测是基于程序代码和数据在时间和空间上的局部性原理(locality)。
时间局部性(temporal locality):如果一个数据现在被访问了,那么以后很有可能也会被访问。
空间局部性(spatial locally):如果一个数据现在被访问了,那么它周围的数据在以后可能也会被访问。
这里要提到一些概念。当CPU在cache中找到需要的数据,我们称之为命中(hit)。反之没有找到数据,我们称之为缺失(miss),这时候就要去外层存储中寻找所需数据。如果是多级cache设计,那么对于L1来讲L2就是它的外层存储。
缓存缺失的类型有很多,常见的有以下三种,可以用3C表示
强制缺失(Compulsory miss),第一次将数据块读入cache所产生的缺失,也成为冷缺失(cold miss)。
冲突缺失(Conflict miss),由于cache相联度有限导致的缺失。
容量缺失(Capacity miss),由于cache大小有限导致的缺失。
高速缓存的管理需要考虑多个方面。首先是数据放置策略;其次是数据替换策略;最后是数据写策略,后面会逐一介绍。
为什么cache要分级
我们经常会看到cache分为L1,L2,L3甚至L4等多级。为什么不能把L1的容量做大,不要其它的cache了?原因在于性能/功耗/面积(PPA)权衡考虑。L1 cache一般工作在CPU的时钟频率,要求的就是够快,可以在2-4时钟周期内取到数据。L2 cache相对来说是为提供更大的容量而优化的。虽然L1和L2往往都是SRAM,但构成存储单元的晶体管并不一样。L1是为了更快的速度访问而优化过的,它用了更多/更复杂/更大的晶体管,从而更加昂贵和更加耗电;L2相对来说是为提供更大的容量优化的,用了更少/更简单的晶体管,从而相对便宜和省电。在有一些CPU设计中,会用DRAM实现大容量的L3 cache(一个DRAM的存储单元要比SRAM小)。现在也有一些设计会带L4 cache,有时放在片外或者和CPU封装在一起。

图2 DRAM(左)和SRAM(右)基本单元结构图
再回到L1 cache,如果容量做大,那么存储单元的选通将会复杂。从而很难满足高时钟频率的要求。另外,当cache容量很小时增加容量,命中率增加的比较明显;当容量达到一定程度,提高cache容量对于提高cache命中率的贡献就很有限了。简单说就是大容量L1很难做,即使做出来用处不明显。与其这样,还不如把节约下来的晶体管用来做其它的用途。

图3 Cache命中率与容量关系
因此出于PPA的权衡,我们先看到的cache系统一般是这样的:32-64KB的指令cache和数据cache(一般L1的指令和数据cache是分开的),2-4个时钟周期访问时间;256KB-2MB的L2 cache(一般从L2开始指令和数据就不分开了),10-20个时钟周期的访问时间;8-80MB的L3 cache,20-50个时钟周期的访问时间。注意,这里所说的时钟周期都是指的CPU的时钟周期。一般L2和L3的工作时钟频率要比CPU的低,这个时钟周期是折算后的数值。
Cache的数据放置策略

图1 cache组成结构示意图

图2 直接映射的内存与cache对应关系
组相联的方式是为了解决直接映射结构Cache的不足而提出的,存储器中的一个数据不单单只能放在一个cache line中,而是可以放在多个cache line中,对于一个组相联结构的cache来说,如果一个数据可以放在n个位置,则称这个cache是n路组相联的cache(n way set-associative Cache)。下图为一个两路组相联Cache的原理图。

图3 两路组相联cache
两路组相联缓存的硬件成本相对于直接映射缓存更高。因为其每次比较tag的时候需要比较多个cache line对应的tag(某些硬件可能还会做并行比较,增加比较速度,这就增加了硬件设计复杂度)。为什么我们还需要两路组相联缓存呢?因为其可以有助于降低cache颠簸可能性。
Cache的写策略
写直达(write through),缓存中任何一个字节的修改都会被立即传播到外层的存储层次。写回(write back),只有当缓存块被替换的时候,被修改的数据块会写回并覆盖外层存储层次中的过时数据。
采用写直达还是写回策略,首先要考虑的系统带宽。对于处理器芯片最外层的高速缓存,由于片外带宽有限,往往采用写回策略;而对于内层高速缓存,由于片上带宽较大,因此往往采用写直达策略。
一个影响是要考虑两种策略在硬件故障下的容错。例如,当遇到阿尔法粒子或者宇宙射线时存储在高速缓存中的数据会反转其存储的值。在写直达策略中,当检测到故障时,可以安全的丢弃出故障的数据块并从外层存储中重新读取该数据块。但在写回策略中,仅仅有故障检测并不够。为了增加纠错功能,需要添加冗余的数据位ECC。但由于ECC计算开销大,因此ECC会增加高速缓存的访问时延。
另一个影响是要考虑两种策略中外层高速存储的功耗。在写直达策略中,外层高速缓存会被频繁写入,导致外层高速缓存较高的功耗。解决办法之一是在内层缓存和外层缓存中间增加一个写缓冲,用于临时保存对内层缓存的最近若干更新。当写缓冲满的时候,将存储最久的或最近最少使用的数据块写入外层缓存。当内层缓存缺失时,首先检查写缓冲区。
写直达策略可能会使用写分配或者写不分配策略。然而,一个写回策略通常会使用写分配策略,否则如果使用写不分配策略,写缺失会被直接传播到外层存储层次,从而变的与写直达相似。
对于多核处理器设计来说,往往最后一级cache(last level cache,LLC)是所有处理器共享,而其它级cache是某处理器独享,因此还有一个写操作如何传播的问题。有两种实现方式:写更新(write update)和写无效(write invalidate)。区别是对某个处理器的缓存中的某个值执行写操作时,对于保有该数据副本的其他所有缓存的值是全部更新还是全部置为无效。
多级cache的包含策略
在多级高速缓存的设计中,另一个相关的问题是内层高速缓存的内容是否包含在外层高速缓存中。如果外层高速缓存包含了内层高速缓存的内容,则称外层高速缓存为包含的(inclusive),相反如果外层高速缓存只包含不在内层高速缓存中的数据块,则称外层高速缓存是排他的(exclusive)。包含性和排他性需要特殊的协议才能实现,否则无法保证包含性或者排他性,这种情况称之为不包含又不排他(non-inclusive non-exclusive,NINE)。
包含策略的优点是,前处理器缓存缺失的时候想看看所需的块是不是在其他处理器的私有cache中,不需要再去一个个查其他处理器的cache了,只需要看看共享的外层cache中有没有即可,对于实现cache一致性非常方便,也有效降低了缓存缺失时的总线负载和miss penalty;缺点是整体cache的容量变小。
包含策略的特性会产生两个影响。一是在采用包含策略的高速缓存中,缓存缺失的时延较短,而采用排他和NINE策略则较长。二是对对所有内层高速缓存检查访问的数据块是否存在意味着增加对高速缓存控制器和内层高速缓存标签阵列的占用。
排他策略正好相反,其优点是,可以最大限度的存储不同的数据块,相当于增大整体了cache的容量;其缺点是需要频繁填充新的数据块,会消耗更多的内外层间缓存带宽,并且对标签和数据阵列产生更高的占用率。
Cache的替换策略
先进先出(FIFO)算法最不经常使用(LFU)算法近期最少使用(LRU)算法随机替换算法
评价cache数据替换策略的标准是,被替换出的数据块应该是将来最晚被访问的数据块。这也好理解,就是要尽量降低随后访问的缓存缺失。目前,大部分高速缓存采用LRU或者近似的替换策略。但是LRU的性能也不是完美的,特别是当程序的工作集远大于缓存大小时,LRU的性能会出现断崖式下跌。