导语
如果你会做饭,那么就自带的50%的学习buffer————开玩笑的,其实大数据流程处理跟做饭一个道理,搞懂弄了流程,再来看看我们怎样学习它,这样学习大数据就事半功倍啦。
如果你已经对大数据的各个框架有所了解,想要福利资料,可以直接跳到3.2 或 3.3 章节获取领取福利。
目录
美食与大数据
大数据处理流程
1.1 数据收集
1.2 数据存储
1.3 数据分析
1.4 数据应用
1.5 其他框架
学习路线
3.1 框架学习
3.2 资料领取
3.3 福利
1 美食与大数据
想象一下,大数据的处理流程好比你做一道美食,需要经历以下几个步骤:
1、食材采购————菜市场去批量采购不同类型的食材:猪肉、蔬菜、干货等2、食材收藏————采购后将这些菜按照类型放到不同区域:冰箱冷藏区、冰箱冷冻区、干货区3、食材预处理————不同食材需要进行处理:蔬菜清洗、猪肉切丝切片、调料剁碎4、食材加工————爆炒猪肝、清蒸鲈鱼、红烧五花肉…
美食是对食材的处理,那么大数据这些框架就是对数据的处理:
采购食材——数据收集、
分批收藏——数据存储、
食材预处理——数据预处理、
加工食材——数据应用。
2 大数据处理流程
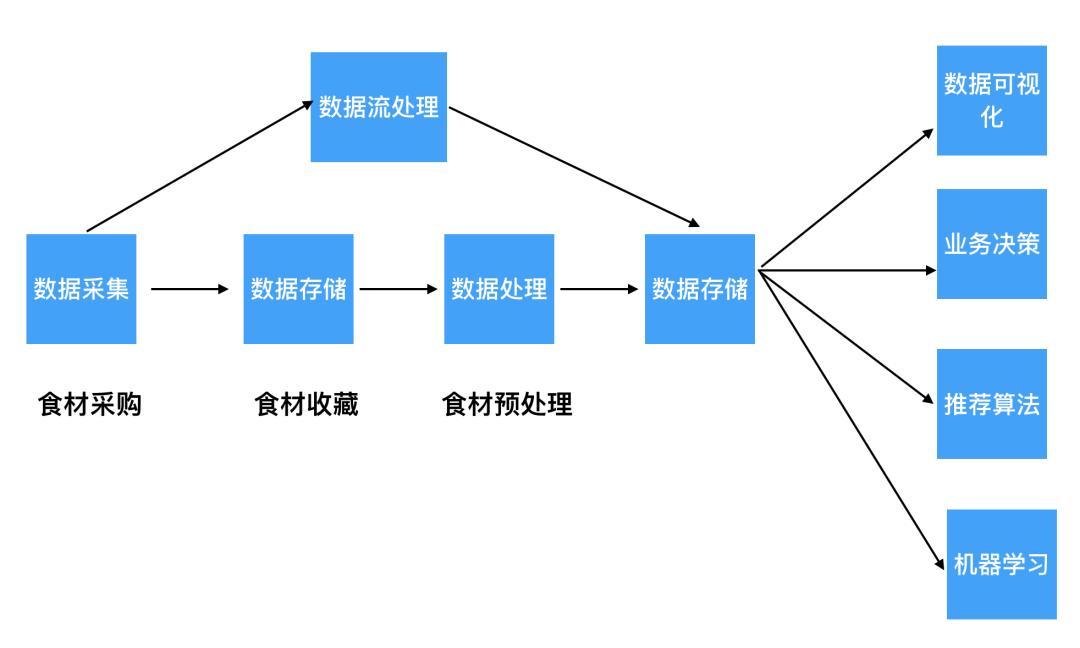 2.1、数据收集(食材采购)
2.1、数据收集(食材采购)
就像菜市场上有不同的食材,我们会到不同的区域进行采购:
 昨天在楼下菜市场买菜,准备做一道土豆红烧牛腩
昨天在楼下菜市场买菜,准备做一道土豆红烧牛腩
那么数据的收集也一样,一般采集服务器上的日志,你可以用最笨的办法就是将服务器上的全部的日志全部导出,但一般大型项目中都是分布式部署的,并且不能因为你导出行为而干扰了服务器的正常运行,所以基于这样的需求,
诞生了一些日志收集工具:「Flume 、Logstash、Kibana」,通过简单配置对复杂数据进行收集处理。
2.2、数据存储(食材收藏)
就像我们会存储不同的食材一样,会将根据食材属性、大小把它放在冰箱冷藏、冷冻区 或者 干货区:

数据存储同样的道理,我们知道数据分为结构化数据、半结构化数据、非结构化数据:
2.2.1、结构化数据它长这样:
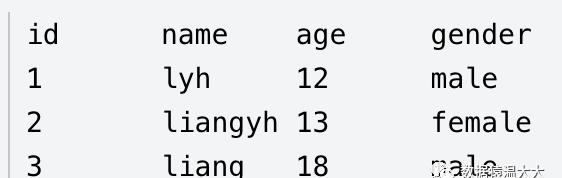
解释:结构化数据就关系型数据库表示和存储的,像我们存储到mysql、Oracle表里面的数据就是结构化数据,
2.2.2、半结构化数据它长这样:

解释:半结构化数据就是结构化数据的一种形式,像我们平时用到的XML、JSON属于常见半结构化数据,
2.2.3、非结构化数据就是各种文档、图片、视频/音频,不过它以二进制存储的,它长这样:
解释:非结构化数据就是各种文档、图片、视频/音频。
结构化数据通常通过关系型数据库存储,例:「MySQL、Oracle」,他们的优点在于快速存储,并且达到快速访问的目的。
为了处理半结构化(日志数据)、非结构化(音频、图片、视频数据)数据而诞生了:「GFS、HDFS」文件处理系统,它的优点在于处理:能处理海量的结构化、半结构、非结构化的数据,在由于它不能随机对数据进行访问,照成访问速度慢的问题,为了「继承关系型数据库随机访问快优点 以及保留海量处理非结构化数据,最终诞生了Hbase 、MongoDB」。
2.3、数据处理(食材预处理)
食材收藏后,我们分批对食材进行预处理:土豆切块、肉切片/切丝、姜蒜切片:
 我将土豆切块、牛腩切块、再切葱姜蒜
我将土豆切块、牛腩切块、再切葱姜蒜
大数据也会对数据进行预处理,预先对数据进行etl(清洗、转换、加载),针对应用场景不同,分为「批处理与流处理」:
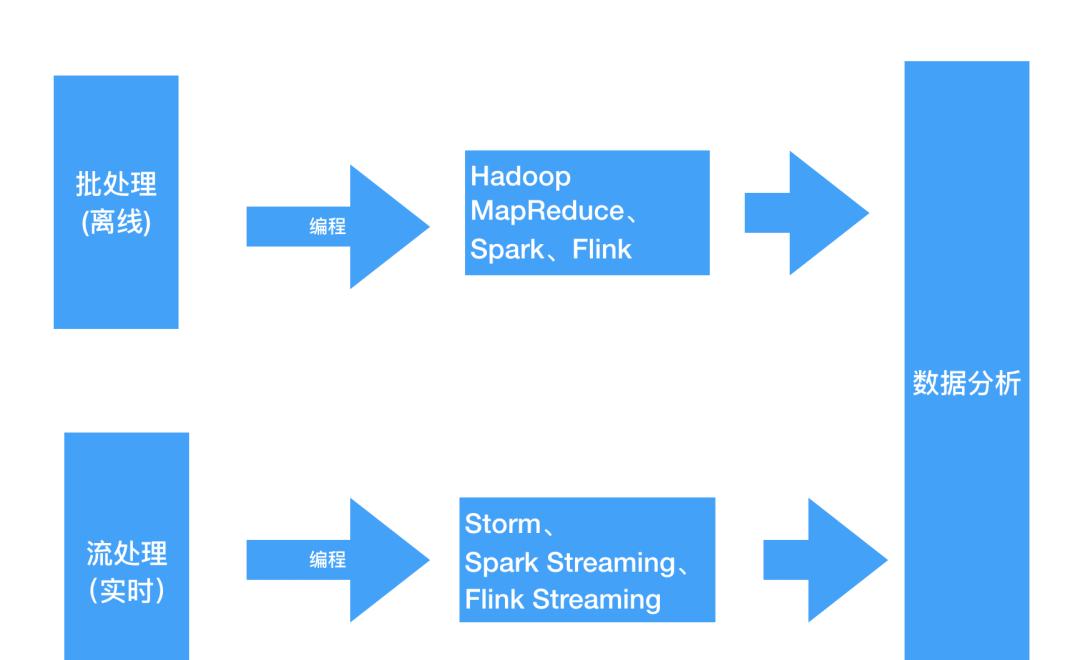
2.3.1、批处理:对离线数据进行处理,例:我们输出用户1年前的购买商品数据的报表,此时「对数据的时效性要求不高」所以对应的就是批处理,处理框架有 「Hadoop MapReduce、Spark、Flink」 等
2.3.2、流处理:对实时数据进行处理,例:查询当前时刻商品库存数据,此时「对数据的时效性非常高」所以对应的就是流处理,即在接收数据的同时就对其进行处理,处理框架有 「Storm、Spark Streaming、Flink Streaming」 等。
如果懂一些编程的同学可以通过以上的框架对数据进行预处理,
那么假如不懂编程的同学就必须学习以上的框架吗?————答案是否定的,为了能让熟悉sql的人员同样能分析数据,查询框架应运而生———— 「Hive 、Spark SQL 、Flink SQL、 Pig、Phoenix」 等框架。
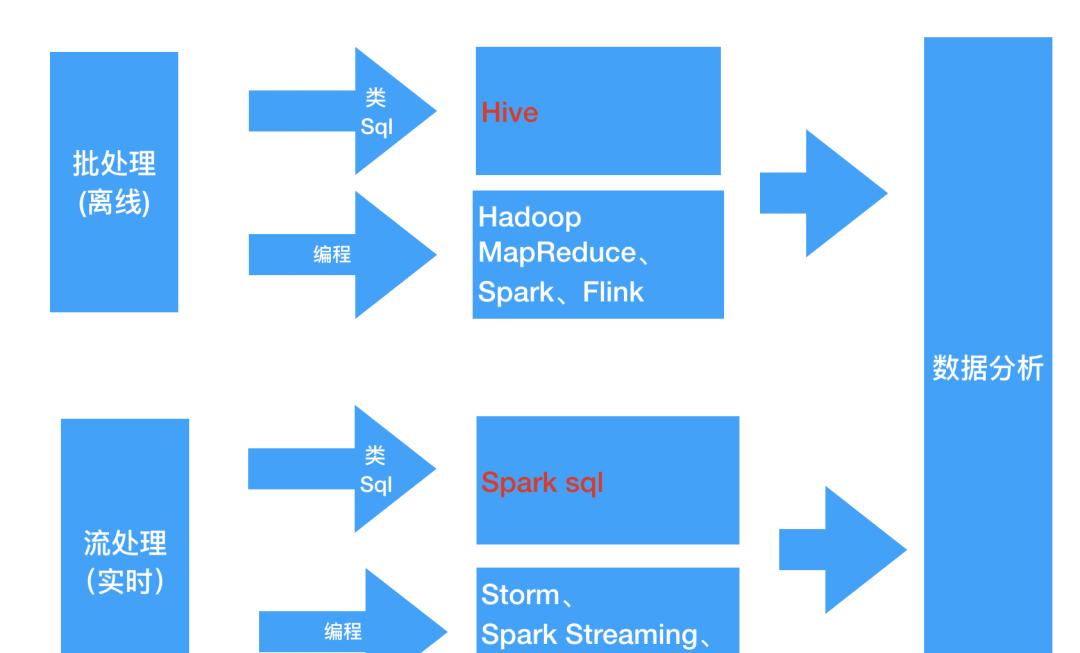
这些查询框架支持使用标准的sql语法 或 类sql语法对数据进行查询,经过sql解析后转换成对应的作业,
Hive 本质上就是将 SQL 转换为 MapReduce 作业,
Spark SQL 将 SQL 转换为一系列的 RDDs 和转换关系(transformations)
2.4、数据应用(食材加工)
经过处理的食材,我们开加工,红烧、清蒸、油炸,然后放上我们的喜好的盐味,最终出锅,上菜:
 经过红烧、焖煮、勾芡后, 出锅咯,mem 味道还是可以滴
经过红烧、焖煮、勾芡后, 出锅咯,mem 味道还是可以滴
对于大数据的最后加工,我们可以将预处理的数据最终变成我们想要的产品,将数据用于优化你的推荐算法,
例:短视频个性化推荐、电商商品推荐、头条新闻推荐
这里面就会用到一些算法来实现,电商领域常用的2种算法如下:
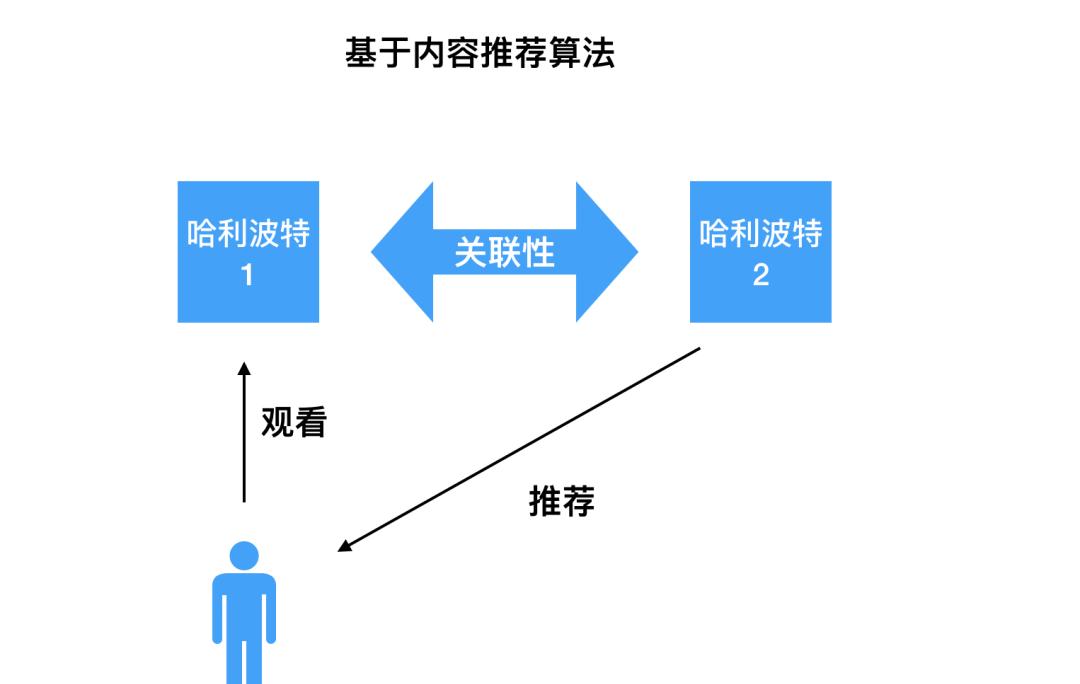
2.4.1、「内容的推荐算法」:
举例:比如你看了哈利波特1,基于内容的推荐算法发现哈利波特2,与你以前观看的在内容上面(共有很多关键词)有很大关联性,就把后者推荐给你。
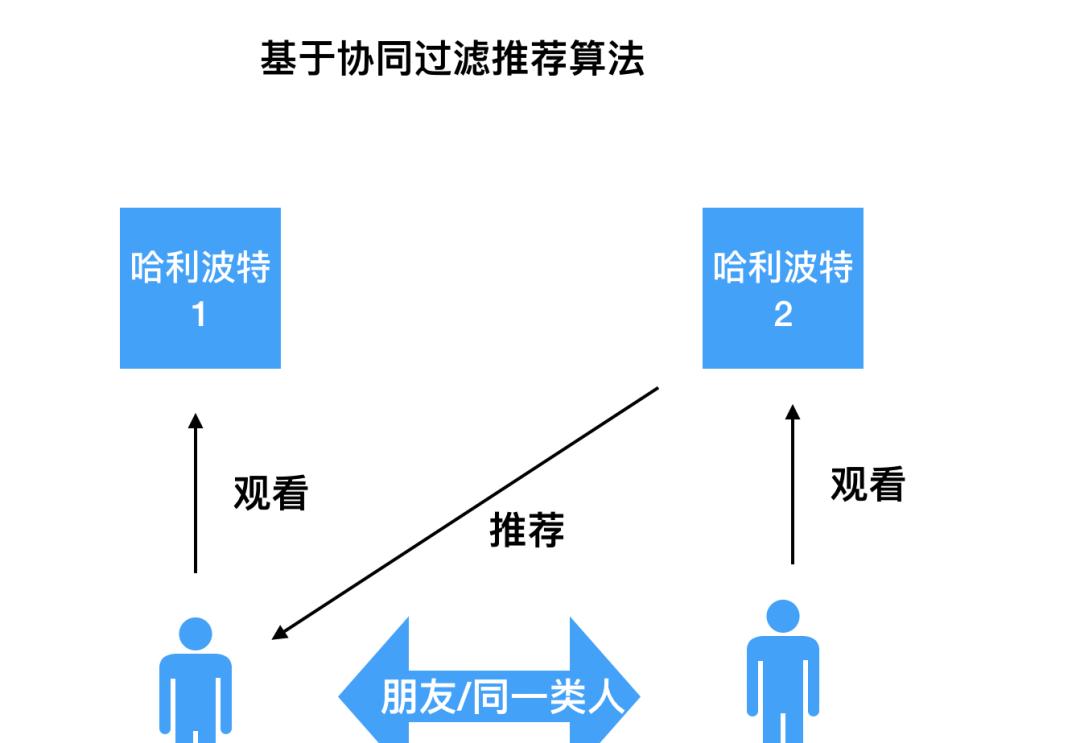
2.4.2、「协同过滤推荐算法」
原理:用户喜欢那些具有相似兴趣的用户喜欢过的商品,
举例:你的朋友喜欢电影哈利波特2,那么就会推荐给你,这是最简单的基于用户的协同过滤算法
 2.5. 其他框架
2.5. 其他框架
前面的是对大数据处理流程所用到的技术框架,实际上大数据集群化(安装 & 监控)、数据迁移、高并发场景的消峰会用到以下框架:
2.5.1 大数据平台集群化:
1 安装
为了更方便的进行集群的部署、监控和管理,衍生了 「Ambari、Cloudera Manager」 等集群管理工具
2 资源分配
保证集群高可用,需要用到 「ZooKeeper」 ,ZooKeeper 是最常用的分布式协调服务,它能够解决大多数集群问题,包括首领选举、失败恢复、元数据存储及其一致性保证。同时针对集群资源管理的需求,又衍生了 「Hadoop YARN」 ;
3 任务调度
多个复杂的并且彼此之间存在依赖关系的作业:基于这种需求,产生了 「Azkaban 和 Oozie」 等工作流调度框架
2.5.2 数据迁移:
有时需要将数据从关系型数据库迁入到 HDFS 中,或者从 HDFS 迁出到关系型数据库中,需要使用到 「Sqoop」 框架
2.5.3 并发性问题:
当并发非常高的情况下,数据无法直接写入到HDFS中时,需要用到 「Kafka」 框架,将数据以队列的方式存储,然后慢慢消费它。
3 学习线路
当我们摸清了每个框架解决什么问题,它位于大数据处理的那个部分,这时候我们再来去学习这个框架,就会事半功倍。
3.1. 框架分类
日志收集框架:Flume、Logstash、Filebeat
分布式文件存储系统:Hadoop HDFS
数据库系统:Mongodb、HBase
分布式计算框架:
批处理框架:Hadoop MapReduce
流处理框架:Storm
混合处理框架:Spark、Flink
查询分析框架:Hive 、Spark SQL 、Flink SQL、 Pig、Phoenix
集群资源管理器:Hadoop YARN
分布式协调服务:Zookeeper
数据迁移工具:Sqoop
任务调度框架:Azkaban、Oozie
集群部署和监控:Ambari、Cloudera Manager
他们的层级结构如下:
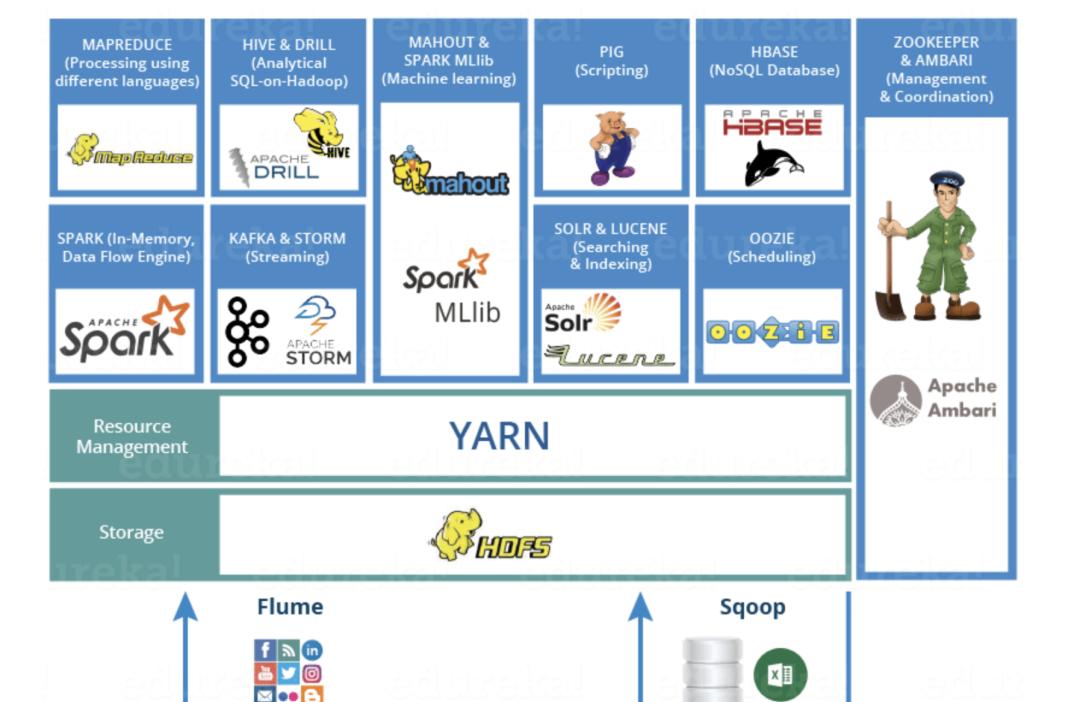
最底层通过 flume sqoop 结构化 与 非结构化数据进行收集,然后存储到hdfs上,在通过zookeeper(yarn)进行集群化资源管理,决定不同的任务分配资源的大小,上层应用可以通过 hadoop、Storm、spark、Flink等框架对数据进行计算与访问,也可以通过类sql语言:hive、pig、spark sql等语言对数据进行计算与访问,不同任务之间在通过Oozie进行调度。
3.2 学习资源
大数据最权威和最全面的学习资料就是官方文档:
《hadoop权威指南(第四版).pdf》《Kafka权威指南.pdf》《Zookeeper分布式一致性原理与实践.pdf》《Spark内核架构设计与实现原理.pdf》《HBase权威指南.pdf》《Hive编程指南.pdf》《Flume构建高可用、可扩展的海量日志采集系统.pdf》《数据挖掘导论_完整版.pdf》
对应关键词:
-Hadoop-Kafka-Zookeeper-Spark-HBase-Hive-Flume-挖掘
「后台回复关键字获取:Hadoop、Kafka、Zookeeper、Spark、HBase、Hive、Flume、挖掘 进行获取」
3.3 福利
如果你由于工作太忙想快速入门,那么下面是我之前对部分技术的讲解链接,希望可以帮助你快速理解或掌握它:
hive函数:
一篇搞定hive函数,建议收藏
pandas函数:
一篇搞定Pandas函数,建议收藏!
hadoop-MapReduce原理:
再也不用怕面试官问你 MapRedue了
hadoop-HDFS原理:
HDFS!一家分布式图书馆…
絮叨