hdfs dfs 命令
常用命令: -moveFromLocal 直接给从本地剪切了 -getmerge 把HDFS的目录下的文件先合并在下载-balancer 手动平衡dataNode的数据-appebdToFile 文件追加数据-cat 查看文件内容-chagrp 修改所属的组-chown 修改文件权限-du 列出文件夹下的所有文件的大小其他的如果想要查看可以列出帮助文档:hdfs dfs 回车
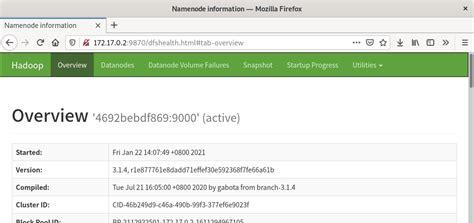
管理员命令 hdfs dfsadmin
-report: 查看集群的基本配置信息 hdfs dfsadmin -report-refreshNodes 刷新节点,主要用于新增或者删除界节点的时候使用-printTopology 打印网络的拓扑结构配额: 名称配额 hdfs dfsadmin -setQuota 3 /fileName 该文件夹下最多放3个文件 空间配额 hdfs dfsadmin -setSpaceQuota 2M /name 最多放置2M的大小
1[-report[-live][-dead][-decommissioning]] 2[-safemode<enter|leave|get|wait>] 3[-saveNamespace] 4[-rollEdits] 5[-restoreFailedStoragetrue|false|check] 6[-refreshNodes] 7[-setQuota<quota><dirname>…<dirname>] 8[-clrQuota<dirname>…<dirname>] 9[-setSpaceQuota<quota>[-storageType<storagetype>]<dirname>…<dirname>]10[-clrSpaceQuota[-storageType<storagetype>]<dirname>…<dirname>]11[-finalizeUpgrade]12[-rollingUpgrade[<query|prepare|finalize>]]13[-refreshServiceAcl]14[-refreshUserToGroupsMappings]15[-refreshSuperUserGroupsConfiguration]16[-refreshCallQueue]17[-refresh<host:ipc_port><key>[arg1..argn]18[-reconfig<datanode|…><host:ipc_port><start|status>]19[-printTopology]20[-refreshNamenodesdatanode_host:ipc_port]21[-deleteBlockPooldatanode_host:ipc_portblockpoolId[force]]22[-setBalancerBandwidth<bandwidthinbytespersecond>]23[-fetchImage<localdirectory>]24[-allowSnapshot<snapshotDir>]25[-disallowSnapshot<snapshotDir>]26[-shutdownDatanode<datanode_host:ipc_port>[upgrade]]27[-getDatanodeInfo<datanode_host:ipc_port>]28[-metasavefilename]29[-triggerBlockReport[-incremental]<datanode_host:ipc_port>]30[-help[cmd]]
文件传输:
1Configurationconfig=newConfiguration(); 2System.setProperty(“HADOOP_USER_NAME”,”root”); 3config.set(“fs.defaultFS”,”hdfs://192.168.47.131:9000″); 4try{ 5FileSystemclient=FileSystem.get(config); 6 7FSDataOutputStreamfsDataOutputStream=client.create(newPath(“/temp/0402”)); 8 9InputStreaminput=newFileInputStream(“E:\\hadoop\\2.0.zip”);10byte[]bytes=newbyte[1024];11intlen;12while((len=input.read(bytes))>0){13fsDataOutputStream.write(bytes,0,len);14}15fsDataOutputStream.flush();16//IOUtils.copyBytes();1718System.out.println();19}catch(IOExceptione){20e.printStackTrace();21}
原理大致是: 一。上面的FileSystem.get(conf)返回的实际上是一个FileSystem的子类DistributedFileSystem,并创建代理对象NameNodeProxies与远程NameNode建立RPC通信。阅读源码就可以看的出来,但是在阅读源码的时候,会有一个知识点,叫做ServiceLoader。ServiceLoader名字虽然简单,但是功能很强大,他可以动态的或得某一个接口的实现类,进而通过反射实例化这些类,就能得到某一个实现的类的对象。二、DistributedFileSystem.create方法通过远程调用NameNode去创建一个没有bocks关联的新文件,创建前会进行各种检验,比如权限等,如果失败就跑出异常。三、 创建完成后返回一个输出流DFSOutputStream。DFSOutputStream会协调NameNode和DataNode,客户端开始写数据到DFSOutputStream,DFSOutputStream会把数据切成小块叫组成DFSpacket,放到一个队列 data queue四、线程DataStreamer 处理队列data queue,他先询问NameNode新的block存在哪个DataNode上,然后输出到DataNode,并实现水平复制五。 DFSOutputStream还有一个队列叫做 ack queue,他会等待datanode收到包之后的相应,当完成冗余度的复制的时候这个队列中的信息才会移除六。传输完成,关闭输出流冗余度复制的话,原则是第一个副本先复制到同一个机架上 ,第二个副本复制到不同的机架上的机器,第三个和第二个在同一个机架上,再有的话就随机了,正常情况下3个足够了。