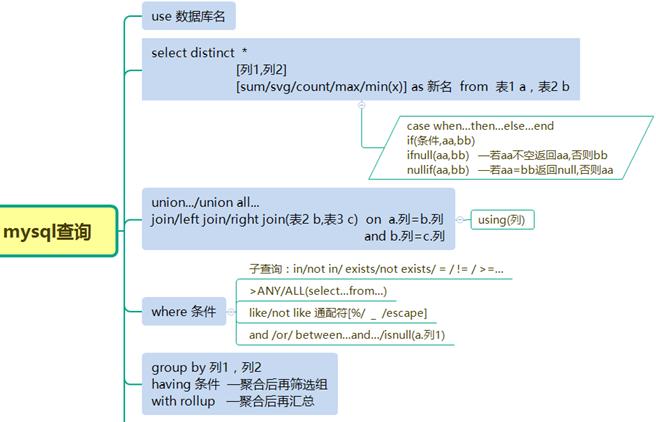
SQL思维导图:查询语句

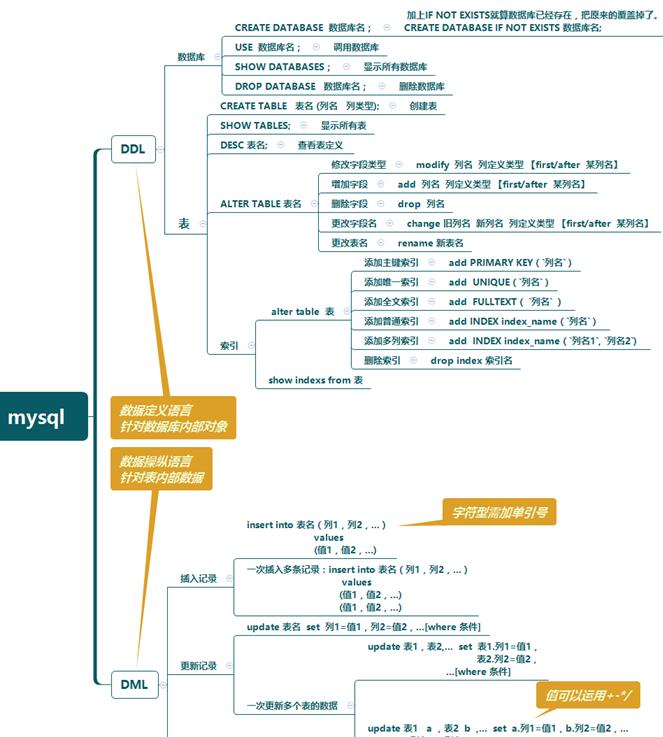
SQL思维导图:DDL&DML
SQL查询:基础知识点
1、左连接、右连接、内连接、外连接
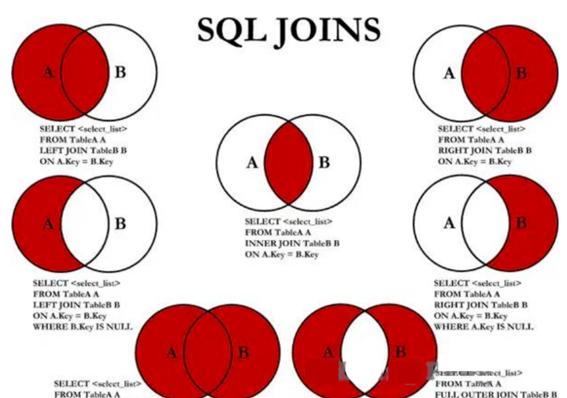
内连接(INNER JOIN),用于返回两个表中满足连接条件的数据行。
左外连接(LEFT OUTER JOIN),返回左表中所有的数据行;对于右表中数据,如果没有匹配的值,返回空值。
右外连接(RIGHT OUTER JOIN),返回右表中所有的数据行;对于左表中数据,若没有匹配的值,返回空值。
全外连接(FULL OUTER JOIN),等价于左外连接加上右外连接,返回左表和右表中所有的数据行。MySQL 不支持全外连接。
交叉连接(CROSS JOIN),也称为笛卡尔积(Cartesian product),两个表的笛卡尔积相当于一个表的所有行和另一个表的所有行两两组合,结果的数量为两个表的行数相乘。
自连接(Self Join),是指连接操作符的两边都是同一个表,即把一个表和它自己进行连接。自连接主要用于处理那些对自己进行了外键引用的表。
2、SQL支持三种注释:
##注释1
–注释2
/*注释3 */
3、LIKE支持两个通配符匹配选项:% 和 _
%表示任何字符出现任意次数
_表示任何字符出现一次
4、去重方式:
DISTINCT:在映射之后对数据进行去重;
UNION(并集运算):将两个子查询拼接起来并去重;
UNION ALL(并集运算):将两个子查询拼接起来但不去重;
EXCEPT(差集运算):将第二个字查询中的结果从第一个子查询中去掉;MySQL 不支持 EXCEPT,Oracle 使用MINUS 替代 EXCEPT。
INTERSECT(交集运算):保留两个子查询中都有的结果并去重;MySQL 不支持 INTERSECT。
5、SQL查询语句执行顺序:

6、数据库范式
第二范式(2NF):首先是 1NF,另外包含两部分内容,一是表必须有主键;二是没有包含在主键中的列必须完全依赖于主键,而不能只依赖于主键的一部分。

7、数据库常见对象有哪些?
表(Table)、视图(View)、序列(Sequence)、索引(Index)、存储过程(Stored Procedure)、触发器(Trigger)、用户(User)以及同义词(Synonym)等等。其中,表是关系数据库中存储数据的主要形式。
8、drop、delete与truncate的区别


SQL查询优化
避免在WHERE子句中使用in、not in (会导致全表扫描), 可以使用exist和notexist代替。
避免在WHERE子句中使用in、not in (会导致全表扫描),对于连续的数值,能用between 就不要用 in 了。
将对于同一个表格的多个字段的操作写到同一个sql中, 而不是分开成两个sql语句实现。
尽量使用exists代替select count(1)来判断是否存在记录,count函数只有在统计表中所有行数时使用,而且count(1)比count(*)更有效率。
最好不要使用“ * ”。
尽量使用“>=”,不要使用“>”。
用IN替换OR。
把 substr函数 换成 like xxx%。
提高GROUP BY语句的效率, 可以通过将不需要的记录在GROUP BY 之前过滤掉.下面两个查询返回相同结果,但第二个明显就快了许多。
应尽量避免在 where 子句中对字段进行表达式操作,这将导致引擎放弃使用索引而进行全表扫描。
不要有超过5个以上的表连接(JOIN),考虑使用临时表或表变量存放中间结果。少用子查询,视图嵌套不要过深,一般视图嵌套不要超过2个为宜。
使用别名,别名是大型数据库的应用技巧,就是表名、列名在查询中以一个字母为别名,查询速度要比建连接表快1.5倍。
应尽量避免在 where 子句中使用 or 来连接条件,否则将导致引擎放弃使用索引而进行全表扫描。
应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描。
应尽量避免在where子句中对字段进行函数操作,这将导致引擎放弃使用索引而进行全表扫描。
如果已知只有一个查询结果,推荐使用limit 1。
优化limit分页:通常用limits来实现日常分页,但当偏移量特别大时,查询效率便会降低。因为Mysql不会跳过偏移量,而是直接获取数据。
谨慎使用distinct关键词:Distinct关键词通常用于过滤重复记录以返回唯一记录。当其被用于查询一个或几个字段时,Distinct关键词将为查询带来优化效果。然而,在字段过多的情况下,Distinct关键词将大大降低查询效率。
使用explain分析SQL步骤。
SQL约束、键与索引
SQL约束用于规定表中的数据规则。
如果存在违反约束的数据行为,行为会被约束终止。
约束可以在创建表时规定(通过 CREATE TABLE 语句),或者在表创建之后规定(通过 ALTER TABLE 语句)。
SQL约束类型:
非空约束NOT NULL:指某列不能存储 NULL 值。比如员工姓名不能为空。
主键约束PRIMARY KEY :NOT NULL 和 UNIQUE 的结合。确保某列(或两个列多个列的结合)有唯一标识,有助于更容易更快速地找到表中的一个特定的记录。例如员工编号,部门编号等。
外键约束FOREIGN KEY:保证一个表中的数据匹配另一个表中的值的参照完整性,用于表示两个表之间的引用关系。例如,员工属于部门,因此员工表中的部门编号字段可以定义为外键,它引用了部门信息表中的主键。
检查约束CHECK:保证列中的值符合指定的条件。例如,薪水必须大于 0 ,性别只能是男和女等。
默认值DEFAULT:规定没有给列赋值时的默认值。
SQL键类型:
PrimaryKey(主键)——是表中的一个或多个字段的集合。它们不接受空值和重复值。并且表中只存在一个主键。
ForeignKey(外键)——在一个表中定义主键并在另一个表中定义字段的键被标识为外键。
UniqueKey(唯一键)——除了主键之外,表中还有更多键,它们只标识记录,但唯一的区别是它们只接受一个空值但不接受重复值。
CandidateKey(候选密钥)——在任何情况下,如果需要,任何候选密钥都可以作为主键。
CompoundKey(复合键)——此键是候选键和主键的组合。
SuperKey(超级密钥)——一个或多个密钥的集合被定义为超级密钥,它用于唯一地标识表中的记录。主键,唯一键和备用键是超级键的子集。
AlternateKey(备用密钥)——在任何情况下,如果需要,任何备用密钥都可以作为主键或候选键。
数据库索引:
主键索引:主键是一种唯一性索引,但它必须指定为PRIMARY KEY,每个表只能有一个主键。
唯一索引:索引列的所有值都只能出现一次,即必须唯一,值可以为空。
普通索引 :基本的索引类型,值可以为空,没有唯一性的限制。
全文索引:全文索引的索引类型为FULLTEXT。全文索引可以在varchar、char、text类型的列上创建。可以通过ALTER TABLE或CREATE INDEX命令创建。对于大规模的数据集,通过ALTER TABLE(或者CREATE INDEX)命令创建全文索引要比把记录插入带有全文索引的空表更快。
索引的区别:
l 一个表只能有一个主键索引,但是可以有多个唯一索引。
l 主键索引一定是唯一索引,唯一索引不是主键索引。
l 主键可以与外键构成参照完整性约束,防止数据不一致。
l 复合索引将多个列组合在一起创建索引,可以覆盖多个列。
l 外键索引:只有InnoDB类型的表才可使用外键索引,保证数据的一致性、完整性和级联操作(基本不用)
l 全文索引:MySQL自带的全文索引只能用于MyISAM,并且只能对英文进行全文检索 (基本不用)。
SQL视图
定义:
视图是基于 SQL 语句的结果集的可视化的表
视图是虚拟的表,本身不包含数据,也就不能对其进行索引操作。对视图的操作和对普通表的操作一样。
作用:
简化复杂的 SQL 操作,比如复杂的联结
只使用实际表的一部分数据
通过只给用户访问视图的权限,保证数据的安全性
更改数据格式和表示
创建视图:
CREATEOR REPLACE VIEW emp_info
AS
SELECTd.dept_name,j.job_title, e.emp_name, e.sex, e.email
FROM employee e
JOIN department d ON (d.dept_id = e.dept_id)
JOIN job j ON (j.job_id = e.job_id);
SELECT*
FROM emp_info
WHERE emp_name = ‘数据部’;
删除视图:
DROPVIEW emp_info;
SQL函数
字符串函数:

日期和时间函数:

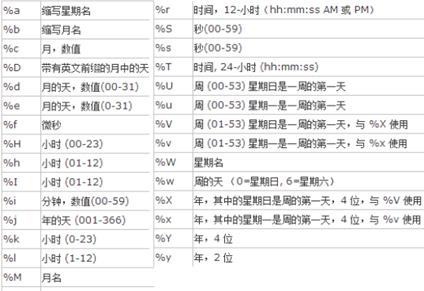
## 日期转化为时间戳 ##
select unix_timestamp(‘2020-03-21 17:13:39’):得到1584782019
select unix_timestamp(‘20200321 13:01:03′,’yyyyMMdd HH:mm:ss’) 得到 1584766863
select unix_timestamp(‘20200321′,’yyyyMMdd’) 得到 1584720000
## 时间戳转化为日期 ##
select from_unixtime (1584782175) 得到2020-03-21 17:16:15
select from_unixtime (1584782175,’yyyyMMdd’) 得到20200321
select from_unixtime (1584782175,’yyyy-MM-dd’)得到2020-03-21
## 日期和日期之间,也可以通过时间戳来进行转换 ##
selectfrom_unixtime(unix_timestamp(‘20200321′,’yyyymmdd’),’yyyy-mm-dd’) 得到2020-03-21
selectfrom_unixtime(unix_timestamp(‘2020-03-21′,’yyyy-mm-dd’),’yyyymmdd’)得到20200321
#日期(2020-03-21 17:13:39)怎么转换为想要的格式(2020-03-21)
select to_date(‘2020-03-21 17:13:39’) 得到 2020-03-21
select substr(‘2020-03-21 17:13:39’,1,10) 得到 2020-03-21
日期之间怎么进行加减操作?
## 使用date_sub (string startdate,int days)得到开始日期startdate减少days天后的日期##
select date_sub(‘2012-12-08’, 10) 得到2012-11-28
## 使用date_add(string startdate,int days)得到开始日期startdate增加days天后的日期 ##
select date_add(‘2012-12-08’, 10) 得到 2012-12-18
## 使用datediff(string enddate,string startdate)得到 结束日期减去开始日期的天数 ##
select datediff(‘2012-12-08′,’2012-05-09’) 得到 213
(year(curdate()) – year(sage)) as 年龄
timestampdiff(year, sage, curdate()) as 年龄
数值函数:

流程函数:

格式化函数: