有哪些有趣的反爬虫机制吗?
说下我以前爬某电影评分网站时遇到的反爬机制吧,感觉还挺有趣的。
爬数据时遇到的问题
首先来说说我在爬数据时遇到的问题,看图:

页面上正确显示了评分为9.5,按F12打开调试模式,找到该元素节点时发现显示的是两个框框,再打开源码发现是一串乱码。
页面数字显示正常,在源码中却显示乱码,可以肯定该网站肯定采取了反爬虫机制,有点意思!
反爬虫机制原理
下面分析一下这个反爬虫机制的原理。
做过web前端开发的人知道显示框框一般都是由于引用了字体文件引起,那么这个网站反爬虫机制会不会跟字体文件有关呢?
刷新一下页面,发现一个字体文件的请求:
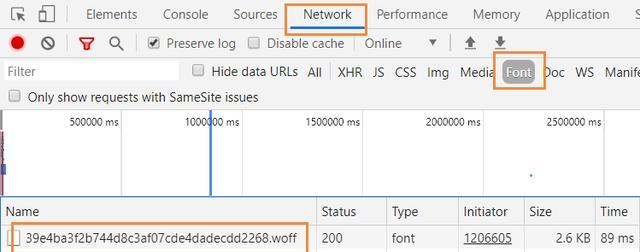
我们手动将这个字体文件下载下来,使用字体编辑工具打开:

虽然我不是太懂字体文件的原理,但是按我的理解其实就是一个字符和数字关系映射文件,例如字符E282对应数字9、字符F11B对应数字5。
现在我们再来看一下源码里的乱码:

有没有看出什么端倪?
是的,它们并不是什么乱码,而是而字体文件里的字符一一对应的!

根据对应关系可以推断出乱码“.”对应数字9.5,正好和页面上显示的是一致的。
总结
这个反爬虫机制的现象是页面显示数字正常,但是源码里显示乱码;这个反爬虫机制的工作原理就是通过字体文件将乱码和数字建立好映射关系。
python爬虫数据预处理步骤?
1.第一步:获取网页链接
1.观察需要爬取的多网页的变化规律,基本上都是只有小部分有所变化,如:有的网页只有网址最后的数字在变化,则这种就可以通过变化数字将多个网页链接获取;
2.把获取得到的多个网页链接存入字典,充当一个临时数据库,在需要用时直接通过函数调用即可获得;
3.需要注意的是我们的爬取并不是随便什么网址都可以爬的,我们需要遵守我们的爬虫协议,很多网站我们都是不能随便爬取的。如:淘宝网、腾讯网等;
4.面对爬虫时代,各个网站基本上都设置了相应的反爬虫机制,当我们遇到拒绝访问错误提示404时,可通过获取User-Agent 来将自己的爬虫程序伪装成由人亲自来完成的信息的获取,而非一个程序进而来实现网页内容的获取。
第二步:数据存储
1.爬虫爬取到的网页,将数据存入原始页面数据库。其中的页面数据与用户浏览器得到的HTML是完全一样的;
2.引擎在抓取页面时,会做一定的重复内容检测,一旦遇到访问权重很低的网站上有大量抄袭、采集或者复制的内容,很可能就不再爬行;
3.数据存储可以有很多方式,我们可以存入本地数据库也可以存入临时移动数据库,还可以存入txt文件或csv文件,总之形式是多种多样的;
第三步:预处理(数据清洗)
1.当我们将数据获取到时,通常有些数据会十分的杂乱,有许多必须要的空格和一些标签等,这时我们要将数据中的不需要的东西给去掉,去提高数据的美观和可利用性;
2.也可利用我们的软件实现可视化模型数据,来直观的看到数据内容;
第四步:数据利用
我们可以把爬取的数据作为一种市场的调研,从而节约人力资源的浪费,还能多方位进行对比实现利益及可以需求的最大化满足。