“12306”是如何支撑百万QPS的?
个人简单谈一下百万QPS下的12306如何架构,算是抛砖引玉,下图是我画的一张网络拓扑图:
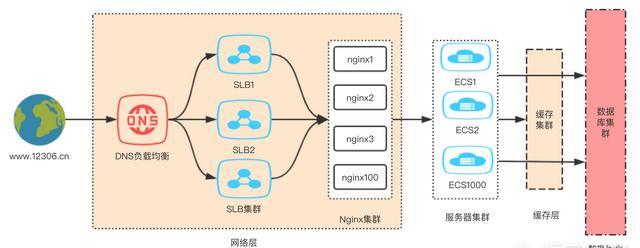
我们知道当国庆节、春节来临的时候,12306会在每天的早上8点、12点、16点等各个时间点放票,这时候在极短的时间内涌入大量的流量请求,可是说是中国互联网甚至世界互联网上最大的高并发请求量了。
网络要承受的住
那首先要保证的就是网络不能挂,大家都先不用考虑服务端具体业务怎么实现的,应该首先要考虑的是多大的网络带宽能够承受住这么大的请求量?
我们常用的方式就是一个域名解析到一个ip地址,这个ip有可能是SLB,或者我们自己装的nginx,然后通过slb再将请求均衡分发到我们的服务器上,这是最简单常见的负载均衡策略。
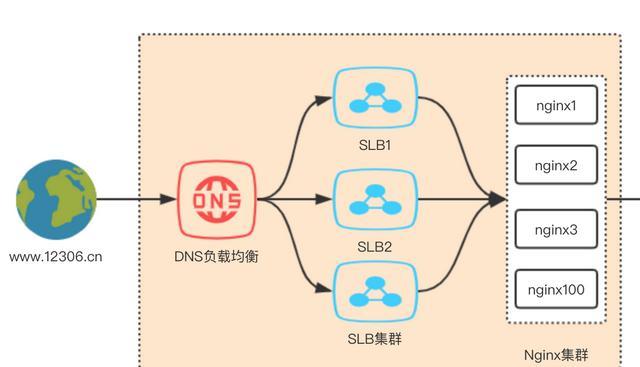
但是这样的单台机器负载均衡是不可能承受的住12306千百万级高并发的。所以必须在域名解析处做好DNS负载均衡,再搭建好SLB集群和Nginx集群,且是多个集群,不同的集群去处理不同的业务。大家可以看到图中网络层,第一步也是最重要的一步就是要把所有的流量均摊出来,避免单机器甚至单集群无法承受住网络流量的瞬时轰炸导致网站瘫痪。
车票查询
车票查询是最核心的业务,也是请求量最大的业务,不仅仅自家网站的大量请求查询,还有一个第三方开发的抢票软件也在不断地请求12306的车票查询业务。
下面有别的答主回答说需要用缓存,这是必然的,但也在抱怨明明有票但是就是显示没票,或者显示有票下单时候就提示没票了。这不是说12306的缓存一致性有问题,或者说这块只保证高并发了,对一致性就肯定做不到强一致性了。
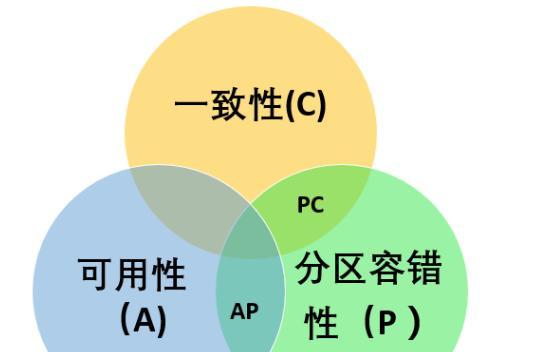
分布式系统中的CAP理论大家应该都知道,CAP理论只能同时满足CP和AP或者CA,其中分区容忍性不可抛弃,那就剩CP和AP了。所以无法做到高并发高可用的同时还得做到强一致性。
另外12306也不是一次就放票出来的,需要保证车站有票、各个小站点保留一部分票,再分时间段逐次发放,既然做不到所有人都可以买到自己最想买到的那一张票,那就保证整体大部分用户买票体验嘛。
核心就是分流
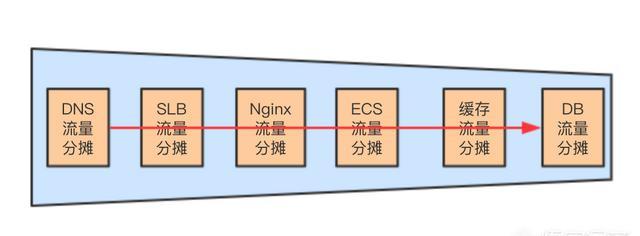
大家都知道国家在治理洪水的时候,会在河流的各个地方设立大坝,逐级控制水流量,而不会把所有的水都蓄在一个地方,水位低的时候,一个大坝就搞定了,水位高的时候,各级大坝都储蓄一部分水,控制整体的洪流,这样就很少发生严重的大范围的洪灾了。
网络也是如此,将整体的网络流量请求逐级分发、均衡到各层,能在这层处理的就不要在传递到下一层,尽量保证整体的服务高可用,即使损失一些强一致性,只要保证最终的一致性就好了。
这里我没有讲各个点的技术细节,只说了个人理解的一个整体思想,按照这个思路去做整体的架构,每一个环节做到编码质量最优、高可用、高并发,再整体串起来,即可承载百万QPS的访问。
以上就是个人的一些拙见,当然实际上的12306远比我说的这些要复杂的多。这里就当抛砖引玉了,欢迎各位大佬批评指正,讨论学习,共同成长!
我是【Java架构设计】,关注我,持续为您提供优质内容!









