背景数据库作为核心数据的重要存储,很多时候都会面临数据迁移的需求,例如:业务从本地迁移上云、数据中心故障需要切换至灾备中心、混合云或多云部署下的数据同步、流量突增导致数据库性能瓶颈需要拆分……
而传统的开源数据库迁移工具SSMA、imp/exp等为了保证迁移数据的一致性,必须要在迁移之前停止服务,容易造成业务中断。对于有些用户,迁移数据量非常大可能达TB级别,即便有了这些开源工具还需要规划磁盘空间大小、传输的网络带宽、CPU资源等等。另外由于这些开源工具的参数配置也相对比较复杂,对用户而言这部分学习成本也较高。
相比传统的迁移工具,UDTS更加灵活弹性,对于正在迁移的任务,用户如果不想迁移了可随时停止,如果任务信息填错等需要修改的时候,用户也可以随时进行修改重启。UDTS还能提供完善的运行信息,例如迁移任务的起始时间、剩余时间、数据量等。在安全可靠性方面,UDTS在公有云平台上进行数据迁移不仅支持外网的迁移,还提供UCloud内网的数据迁移。
支持丰富的迁移类型
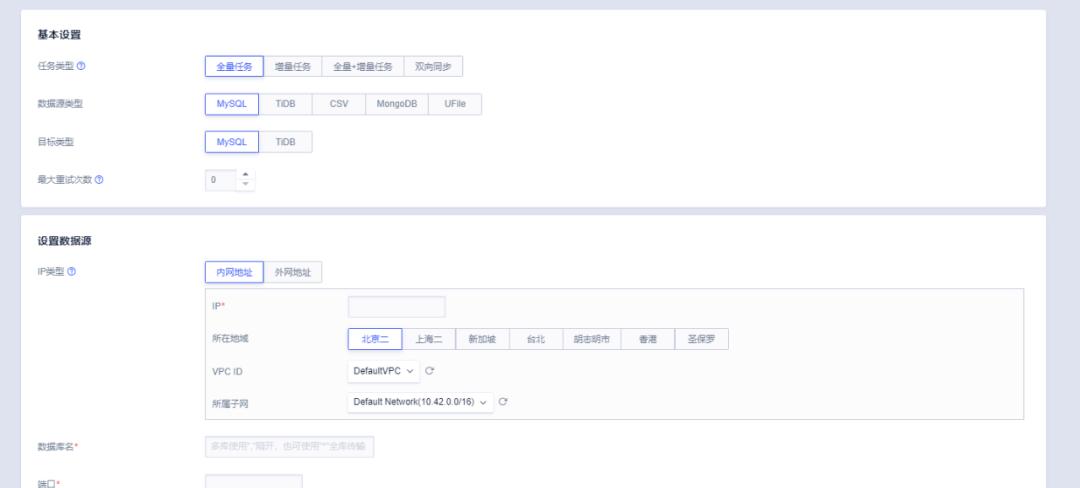
 如上图所示,目前UDTS支持主流数据库MySQL、TiDB、PgSQL、SQLServer、MongoDB、Redis的同构数据源之间的迁移,以及异构数据源的迁移MySQL->TiDB。还支持一些其他类型的迁移,例如从CSV->UDW(UCloud数据仓库)、CSV->MySQL。了解到很多UFile用户有数据迁移的需求,因此UDTS新增了UFile之间的数据迁移,包括支持全bucket迁移、按prefix迁移、断点续传,同时可以与UCloud工作流服务StepFlow结合实现增量同步。
如上图所示,目前UDTS支持主流数据库MySQL、TiDB、PgSQL、SQLServer、MongoDB、Redis的同构数据源之间的迁移,以及异构数据源的迁移MySQL->TiDB。还支持一些其他类型的迁移,例如从CSV->UDW(UCloud数据仓库)、CSV->MySQL。了解到很多UFile用户有数据迁移的需求,因此UDTS新增了UFile之间的数据迁移,包括支持全bucket迁移、按prefix迁移、断点续传,同时可以与UCloud工作流服务StepFlow结合实现增量同步。
UDTS的三次重要升级
迁移维度从表到库
经过调研我们发现有些用户的表比较少且集中,有些用户一个表有上百G的数据,如果按库迁移的话,一个库里面上TB的数据迁移在导出阶段一旦出问题就得从头再来,因此UDTS最初是从表的维度开始迁移,一次只能迁移一个库里面的一张表。
后来又调研到有用户的一个MySQL实例有十几个库,每个库有二十几张表,如果按表迁移可能要创建几百个任务,对于该用户来说按表迁移的显然任务量巨大。于是我们很快开发支持了按库进行迁移,将这个用户库里面所有表一次全部迁移过去。另外UDTS还支持多库及全库的迁移,可以将一个实例下除系统库(mysql, information_schema, performance_schema, test, sys)以外的所有库一次性迁移过去。
支持ETL数据过滤
有些用户会面临这样的需求:在数据迁移的时候不希望或者不需要将所有数据完整的迁移到目标库,因此UDTS开发了按条件(行)选择及按列选择功能。还有一些数据整合的场景,用户原来的数据分散在不同的数据库中,现在希望整合到同一个高性能数据库中。但有时会遇到数据库名重复冲突导致无法整合。于是UDTS提供了迁移时重命名的功能,可以针对数据库也可以针对表,这样就帮助这类用户解决了数据整合的难题。同时我们还提供了列级的映射,让用户有更灵活的迁移服务。
 使用过MySQL的用户可能经常会遇到这种情况,如果业务量大,从库老是追不上主库。我们遇到有用户在做完全量迁移后,做增量迁移的时候发现老是追不上主库,经过分析发现该用户有一个批量计算在里面,有一张表有几千万条数据,每隔一段时间做一次批量计算,将那张表拷贝一份在里面做大量的运算,用完了之后再删掉,不断的重复做这件事情。但由于这些表都是临时生成的只知道前缀不知道名字,于是UDTS增加了一个数据过滤功能,支持按特定的前缀来排除特定的表,这样运行出来速度就很快,任务一旦启动就从来没有掉过队,一直是实时保持同步的。
使用过MySQL的用户可能经常会遇到这种情况,如果业务量大,从库老是追不上主库。我们遇到有用户在做完全量迁移后,做增量迁移的时候发现老是追不上主库,经过分析发现该用户有一个批量计算在里面,有一张表有几千万条数据,每隔一段时间做一次批量计算,将那张表拷贝一份在里面做大量的运算,用完了之后再删掉,不断的重复做这件事情。但由于这些表都是临时生成的只知道前缀不知道名字,于是UDTS增加了一个数据过滤功能,支持按特定的前缀来排除特定的表,这样运行出来速度就很快,任务一旦启动就从来没有掉过队,一直是实时保持同步的。

从单地域到多地域
UDTS 从最初的北京单地域逐渐扩展了很多其他地域,这里涉及到跨地域甚至跨国迁移的问题。单地域迁移,比如在北京几个可用区之间的延时最多可能一两毫秒,而跨国迁移中有些国家网络延时可能达到几十毫秒,而低延时对于数据迁移的服务来说非常关键。第一个大问题就是带宽问题,同一地域内无论是内网还是外网带宽可以认为是无限的,但跨国迁移不同,云厂商的网络出口流量出于成本或安全的考虑都会做一些限制,因此最开始经常遇到一些失败的情形,迁移过程中网络突然断掉,这是由于流量超过了云厂商机房的网络阈值导致IP被限制了,因此我们要保证整个迁移过程中网速不能超过数据中心的阈值。
第二个问题是高延迟,例如数据库连接中间丢包产生的现象比较多就必须做一些改进,因此UDTS产品需要更健壮,断点续传的功能一定要非常稳健。第三个问题是我们发现有很多跨国迁移用户对数据非常敏感不愿意走公网,需要单独拉一条专线,但是由于专线的厂商有一些保活机制在里面,会对数据库连接产生干扰,经常遇到网络突然中断的情况。因此专线之间的保活措施如果确实有问题可以把机制关掉,另外数据库的错误连接数一定要设置的很高,不然很容易达到阈值导致连接连不上去。
UDTS在多地域的支持上,除了UCloud国内的节点(含台湾,香港),也陆续开通了如新加坡、越南、巴西圣保罗等海外节点,后续还会逐步扩展UDTS服务至UCloud全地域节点实现全球化级别的服务。UDTS双向迁移为什么要做双向迁移呢?假如一个用户要确保迁移万无一失,一旦迁过去一段时间后出错了,立马要回切,这里面就涉及到一个问题,一般数据迁移都是从源到目的做一个全量,然后增量同步,才会把业务切过去。但是这个过程流量只会写一边,导致不断产生的新数据并没有写到源端。有些场景很复杂,不只是一个关系型数据库,迁移下来有一整套比如缓存、DNS服务或者其他服务,万一整个迁移过来后工作一段时间发现出问题了,就需要立马把业务切回去,这时从数据库的角度来说基本切不回去了,因为目的端已经产生了很多增量数据而源端没有。如果有双向同步,数据写到目标端就可以实时同步到源端,将业务随时切回来。
 还有异地双活的场景,有些用户可能一部分业务跑在这家云厂商另外一部分业务跑在另外一家云厂商上面,或两边厂商都要跑一模一样的环境,这些都需要数据同步,从而达到跨云协同或者跨云容灾。一家云商出问题以后,快速将业务切换到另外一家云商上,保证业务可用。双活怎么做?不管哪家云厂商数据库都支持高可用,不用同云厂商做了不同的架构改造,每一家都有自己的模式。UCloud的关系型数据库UDB高可用的结构不能和AWS的高可用结构通过主从做实时同步,一个主库可以有很多个从库,但是一个从库只能有一个主库。如果有了双向同步,就可以实现业务的双活部署,无论从哪边写都可以实时的同步。
还有异地双活的场景,有些用户可能一部分业务跑在这家云厂商另外一部分业务跑在另外一家云厂商上面,或两边厂商都要跑一模一样的环境,这些都需要数据同步,从而达到跨云协同或者跨云容灾。一家云商出问题以后,快速将业务切换到另外一家云商上,保证业务可用。双活怎么做?不管哪家云厂商数据库都支持高可用,不用同云厂商做了不同的架构改造,每一家都有自己的模式。UCloud的关系型数据库UDB高可用的结构不能和AWS的高可用结构通过主从做实时同步,一个主库可以有很多个从库,但是一个从库只能有一个主库。如果有了双向同步,就可以实现业务的双活部署,无论从哪边写都可以实时的同步。
 双向同步有一个难点就是流量循环,为了避免这个问题,我们一般用打标签的方法,给一条语记做一个标记,迁移的时候就能识别出来这个是从哪边迁移过来直接扔掉不迁。
双向同步有一个难点就是流量循环,为了避免这个问题,我们一般用打标签的方法,给一条语记做一个标记,迁移的时候就能识别出来这个是从哪边迁移过来直接扔掉不迁。
方案一:修改数据库源码,在binlog中给源加标记;
方案二:要求表有主键,将 insert/update 修改为 replace into;
方案三:将每一条语句打包成带特殊TAG语句的事务,同步服务识别出TAG,忽略整条事务。