前置条件
Hadoop版本: Hadoop 2.6.0-cdh5.15.0
Spark版本: SPARK 1.6.0-cdh5.15.0
概述
源码分析Spark HadoopRDD是如何读取HDFS上的文件
分析HadoopRDD预分区的计算方式,非首个分区的开始位置计算
来三种情况分析,不同情部下HadoopRDD的分区计算方式
HDFS数据文件abkljcanmoHDFS 数据文件图解
HDFS 数据文件图解(对比)图一
图二
断点位置
org.apache.hadoop.mapred.LineRecordReader 241行, 246行, 248行,136行
HadoopRDD partition预划分方式(实际会有小的调整)
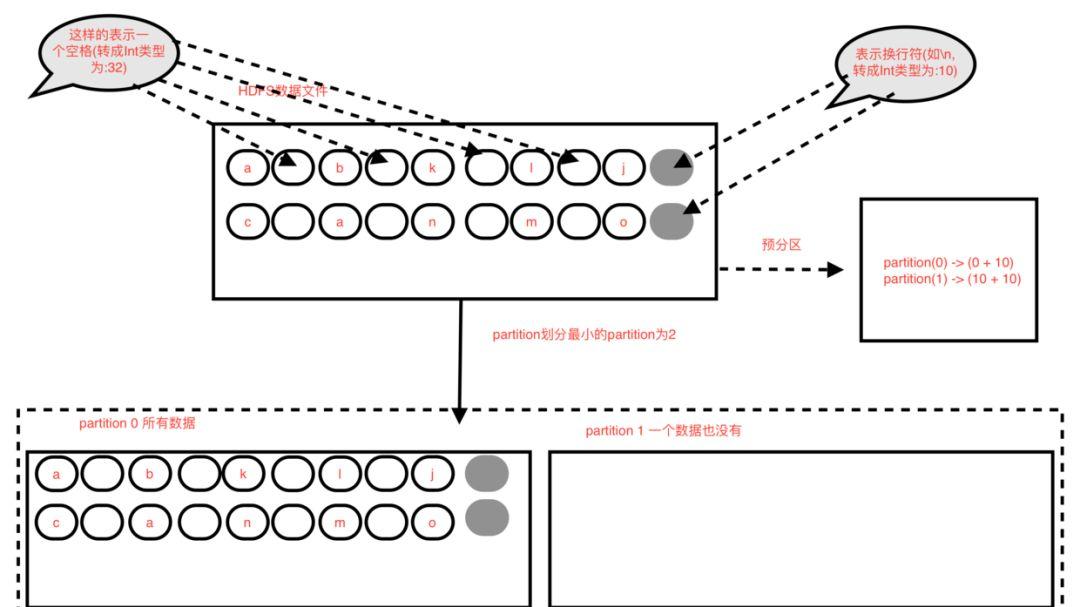
每个partition的长度= 文件的总长度 / 最小的分区数(默认分区数为2) //注意,是除,结果会取整, 即 goalSize = totalSize / numSplits
示例中每个partition的长度 = 20 / 2 =10 // 即为10个byte
然后依次从0开始划分10个byte长度为一个partition,最后一个小于等于10个byte的为最后一个partition
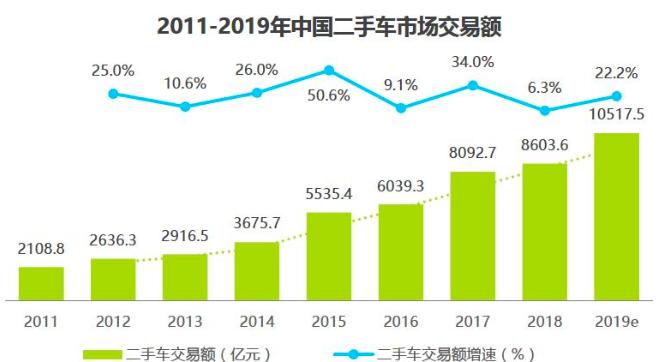
所以 parition(0) = hdfs文件(0 10) //即从文件偏移量为0开始,共10byte,0 <= 值 < 10
所以 parition(1) = hdfs文件(10 10) //即从文件偏移量为10开始,共10byte,10 <= 值 < 20
即 partition(i) = hdfs文件( i * goalSize 10 )
HadoopRDD partition划分原理
由于需要考虑,每个partition谁先执行是不确定的,所以每个partition执行时,都需要可明确计算当前partition的数据范围
由于直接按partition预划分方式,会把有的一行数据拆分,有些场景不适合(如钱金额,词组一般都不希望被拆分,所以一般按行拆分)
所以需要按行做为最小的数据划分单元,来进行partition的数据范围划分
HadoopRDD是这样划分的partition,还是按partition预划分方式进行预先划分,不过在计算时会进行调整
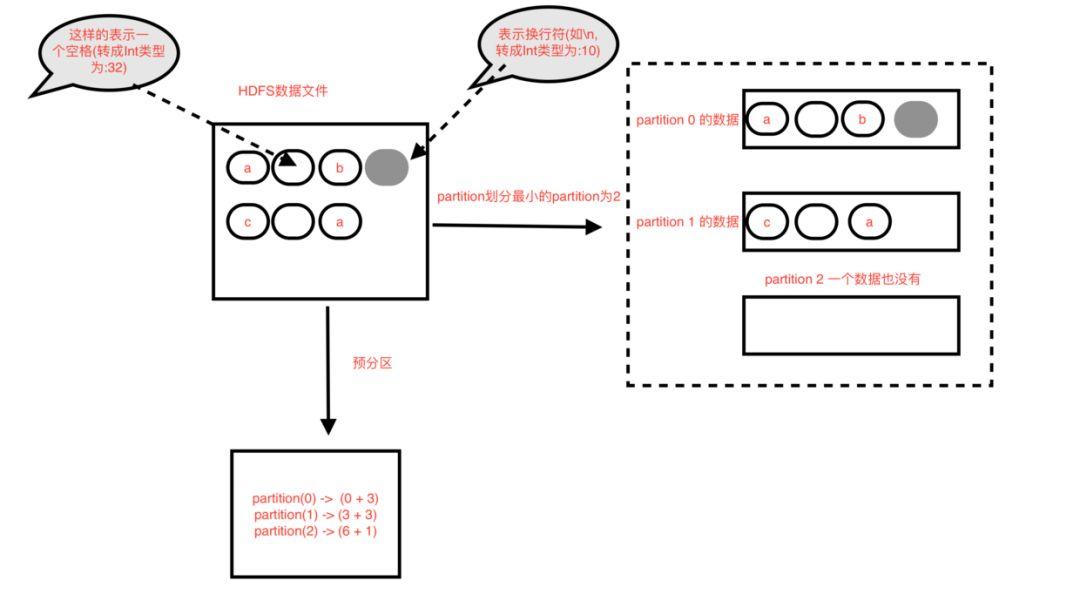
对于首个partition,也就是partition(0),分区数据范围的开始位置就是从0开始(0 goalSize )
对于非首个partition,的开始位置需要从新计算,从预划分的当前partition的开始位置开始找第一个换行符位置(indexNewLine),当前partition的开始位置为= indexNewLine 1,长度还是goalSize
对于首个partition一定能分到数据(只要HDFS文件有数据)
非首个partition,有可能分不到数据的情况,分不到数据的情况,就是数据被上一个partition划分完了
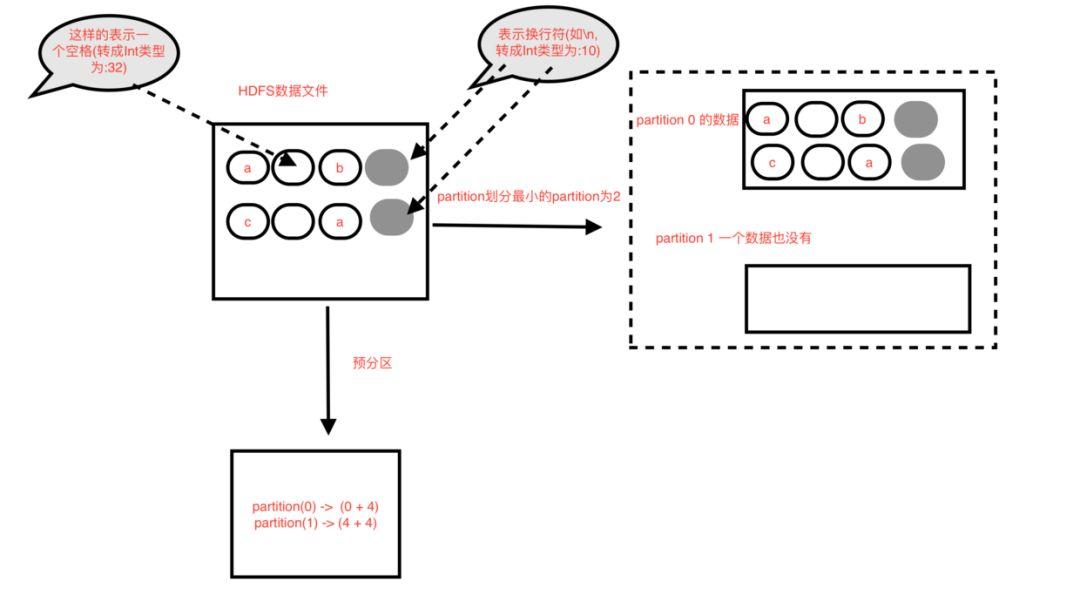
partition分不到数据(以下情况同时满足)
是非首个partition,也就是不是partition为索引为0
partition从预分区开始位置往后读到的第一个换行符大于等于预分区的结束位置 (或者该partition就没有一个换行符)
源码分析
HadoopRdd partition的开始位置计算(文档详情) : https://github.com/opensourceteams/spark-scala-maven/blob/master/md/HadoopRddPartitionDivide.md
HadoopRDD
overridedefcompute(theSplit:Partition,context:TaskContext):InterruptibleIterator[(K,V)]={valiter=newNextIterator[(K,V)]{valsplit=theSplit.asInstanceOf[HadoopPartition]logInfo(“Inputsplit:” split.inputSplit)valjobConf=getJobConf()valinputMetrics=context.taskMetrics.getInputMetricsForReadMethod(DataReadMethod.Hadoop)//Setsthethreadlocalvariableforthefile’snamesplit.inputSplit.valuematch{casefs:FileSplit=>SqlNewHadoopRDDState.setInputFileName(fs.getPath.toString)case_=>SqlNewHadoopRDDState.unsetInputFileName()}//FindafunctionthatwillreturntheFileSystembytesreadbythisthread.Dothisbefore//creatingRecordReader,becauseRecordReader’sconstructormightreadsomebytesvalbytesReadCallback=inputMetrics.bytesReadCallback.orElse{split.inputSplit.valuematch{case_:FileSplit|_:CombineFileSplit=>SparkHadoopUtil.get.getFSBytesReadOnThreadCallback()case_=>None}}inputMetrics.setBytesReadCallback(bytesReadCallback)varreader:RecordReader[K,V]=null//返回TextInputFormat对象valinputFormat=getInputFormat(jobConf)HadoopRDD.addLocalConfiguration(newSimpleDateFormat(“yyyyMMddHHmm”).format(createTime),context.stageId,theSplit.index,context.attemptNumber,jobConf)//实例化对象org.apache.hadoop.mapred.LineRecordReader//newLineRecordReader()实例方法中,并且会重新计算当前partition的开始位置(与预分区的会有出入)reader=inputFormat.getRecordReader(split.inputSplit.value,jobConf,Reporter.NULL)//Registeranon-task-completioncallbacktoclosetheinputstream.context.addTaskCompletionListener{context=>closeIfNeeded()}valkey:K=reader.createKey()valvalue:V=reader.createValue()overridedefgetNext():(K,V)={try{//调用org.apache.hadoop.mapred.LineRecordReader.next()方法finished=!reader.next(key,value)}catch{case_:EOFExceptionifignoreCorruptFiles=>finished=true}if(!finished){inputMetrics.incRecordsRead(1)}//返回当前一对(key,value)对应的值(key,value)}overridedefclose(){if(reader!=null){SqlNewHadoopRDDState.unsetInputFileName()//Closethereaderandreleaseit.Note:it’sveryimportantthatwedon’tclosethe//readermorethanonce,sincethatexposesustoMAPREDUCE-5918whenrunningagainst//Hadoop1.xandolderHadoop2.xreleases.Thatbugcanleadtonon-deterministic//corruptionissueswhenreadingcompressedinput.try{reader.close()}catch{casee:Exception=>if(!ShutdownHookManager.inShutdown()){logWarning(“ExceptioninRecordReader.close()”,e)}}finally{reader=null}if(bytesReadCallback.isDefined){inputMetrics.updateBytesRead()}elseif(split.inputSplit.value.isInstanceOf[FileSplit]||split.inputSplit.value.isInstanceOf[CombineFileSplit]){//Ifwecan’tgetthebytesreadfromtheFSstats,fallbacktothesplitsize,//whichmaybeinaccurate.try{inputMetrics.incBytesRead(split.inputSplit.value.getLength)}catch{casee:java.io.IOException=>logWarning(“UnabletogetinputsizetosetInputMetricsfortask”,e)}}}}}newInterruptibleIterator[(K,V)](context,iter)}
TextInputFormat
返回LineRecordReader
publicRecordReader<LongWritable,Text>getRecordReader(InputSplitgenericSplit,JobConfjob,Reporterreporter)throwsIOException{reporter.setStatus(genericSplit.toString());Stringdelimiter=job.get(“textinputformat.record.delimiter”);byte[]recordDelimiterBytes=null;if(null!=delimiter){recordDelimiterBytes=delimiter.getBytes(Charsets.UTF_8);}returnnewLineRecordReader(job,(FileSplit)genericSplit,recordDelimiterBytes);}
LineRecordReader
实例方法中,重新定位当前partition的开始位置
如果是partition(0),开始位置是0
如果不是partition(0),开始位置重新计算
调用 in.readLine()方法,等于调用 UncompressedSplitLineReader.readLine(),注意此时传的maxLineLength参数为0
publicLineRecordReader(Configurationjob,FileSplitsplit,byte[]recordDelimiter)throwsIOException{this.maxLineLength=job.getInt(org.apache.hadoop.mapreduce.lib.input.LineRecordReader.MAX_LINE_LENGTH,Integer.MAX_VALUE);start=split.getStart();end=start split.getLength();finalPathfile=split.getPath();compressionCodecs=newCompressionCodecFactory(job);codec=compressionCodecs.getCodec(file);//openthefileandseektothestartofthesplitfinalFileSystemfs=file.getFileSystem(job);fileIn=fs.open(file);if(isCompressedInput()){decompressor=CodecPool.getDecompressor(codec);if(codecinstanceofSplittableCompressionCodec){finalSplitCompressionInputStreamcIn=((SplittableCompressionCodec)codec).createInputStream(fileIn,decompressor,start,end,SplittableCompressionCodec.READ_MODE.BYBLOCK);in=newCompressedSplitLineReader(cIn,job,recordDelimiter);start=cIn.getAdjustedStart();end=cIn.getAdjustedEnd();filePosition=cIn;//takeposfromcompressedstream}else{in=newSplitLineReader(codec.createInputStream(fileIn,decompressor),job,recordDelimiter);filePosition=fileIn;}}else{fileIn.seek(start);//读取文件,定位的文件偏移量为,当前partition预分区的开始位置in=newUncompressedSplitLineReader(fileIn,job,recordDelimiter,split.getLength());filePosition=fileIn;}//Ifthisisnotthefirstsplit,wealwaysthrowawayfirstrecord//becausewealways(exceptthelastsplit)readoneextralinein//next()method.if(start!=0){//调用in.readLine()方法,等于调用UncompressedSplitLineReader.readLine(),//注意此时传的maxLineLength参数为0//定位当前分区的开始位置,等于预分区的位置 读到的第一个换行符的长度//也就是从当前partition开始位置计算,到读到的第一次换行符,属于上一个partition,在向后位置偏移位置 1,就是当前分区的实时开始位置start =in.readLine(newText(),0,maxBytesToConsume(start));}this.pos=start;}
HadoopRDD.compute() 重写迭代器getNext()方法
计算下一个(key,value)的值
具体reader.next()方法为 LineRecordReader.next() 方法
overridedefgetNext():(K,V)={try{finished=!reader.next(key,value)}catch{case_:EOFExceptionifignoreCorruptFiles=>finished=true}if(!finished){inputMetrics.incRecordsRead(1)}(key,value)}
LineRecordReader.next()
遍历当前分区的(key,value)值,就是去计算每个key,对应的值,每计算完一个(key,value)的值后,会把下一个key的索引位置进行更新
/**Readaline.*/publicsynchronizedbooleannext(LongWritablekey,Textvalue)throwsIOException{//Wealwaysreadoneextraline,whichliesoutsidetheupper//splitlimiti.e.(end-1)//getFilePosition()等于pos位置while(getFilePosition()<=end||in.needAdditionalRecordAfterSplit()){key.set(pos);//调置本次的偏移位置intnewSize=0;if(pos==0){//第一个partition(0)newSize=skipUtfByteOrderMark(value);}else{newSize=in.readLine(value,maxLineLength,maxBytesToConsume(pos));pos =newSize;}if(newSize==0){returnfalse;}if(newSize<maxLineLength){returntrue;}//linetoolong.tryagainLOG.info(“Skippedlineofsize” newSize “atpos” (pos-newSize));}returnfalse;}
UncompressedSplitLineReader.readLine()
调用LineReader.readLine()方法
@OverridepublicintreadLine(Textstr,intmaxLineLength,intmaxBytesToConsume)throwsIOException{intbytesRead=0;if(!finished){//onlyallowatmostonemorerecordtobereadafterthestream//reportsthesplitendedif(totalBytesRead>splitLength){finished=true;}bytesRead=super.readLine(str,maxLineLength,maxBytesToConsume);}returnbytesRead;}
LineReader.readLine()方法
调用 LineReader.readDefaultLine()方法
/***ReadonelinefromtheInputStreamintothegivenText.**@paramstrtheobjecttostorethegivenline(withoutnewline)*@parammaxLineLengththemaximumnumberofbytestostoreintostr;*therestofthelineissilentlydiscarded.*@parammaxBytesToConsumethemaximumnumberofbytestoconsume*inthiscall.Thisisonlyahint,becauseifthelinecross*thisthreshold,weallowittohappen.Itcanovershoot*potentiallybyasmuchasonebufferlength.**@returnthenumberofbytesreadincludingthe(longest)newline*found.**@throwsIOExceptioniftheunderlyingstreamthrows*/publicintreadLine(Textstr,intmaxLineLength,intmaxBytesToConsume)throwsIOException{if(this.recordDelimiterBytes!=null){returnreadCustomLine(str,maxLineLength,maxBytesToConsume);}else{returnreadDefaultLine(str,maxLineLength,maxBytesToConsume);}}
LineReader.readDefaultLine()方法
具体计算partition的开始位置的方法
注意,此时传过来的maxLineLength参数值为0,也就是先不实际读取数据放到(key,value)的value中
调用 UncompressedSplitLineReader.fillBuffer()方法,实际读取HDFS上的文件
/***ReadalineterminatedbyoneofCR,LF,orCRLF.*当maxLineLength=0时,也就是partition不为0时,定位开始位置的时候,该方法会读取到*/privateintreadDefaultLine(Textstr,intmaxLineLength,intmaxBytesToConsume)throwsIOException{/*We’rereadingdatafromin,buttheheadofthestreammaybe*alreadybufferedinbuffer,sowehaveseveralcases:*1\.Nonewlinecharactersareinthebuffer,soweneedtocopy*everythingandreadanotherbufferfromthestream.*2\.Anunambiguouslyterminatedlineisinbuffer,sowejust*copytostr.*3\.Ambiguouslyterminatedlineisinbuffer,i.e.bufferends*inCR.InthiscasewecopyeverythinguptoCRtostr,but*wealsoneedtoseewhatfollowsCR:ifit’sLF,thenwe*needconsumeLFaswell,sonextcalltoreadLinewillread*fromafterthat.*WeuseaflagprevCharCRtosignalifpreviouscharacterwasCR*and,ifithappenstobeattheendofthebuffer,delay*consumingituntilwehaveachancetolookatthecharthat*follows.*/str.clear();inttxtLength=0;//tracksstr.getLength(),asanoptimizationintnewlineLength=0;//lengthofterminatingnewlinebooleanprevCharCR=false;//trueofprevcharwasCRlongbytesConsumed=0;do{intstartPosn=bufferPosn;//startingfromwhereweleftoffthelasttimeif(bufferPosn>=bufferLength){startPosn=bufferPosn=0;if(prevCharCR){//bytesConsumed:总计读取的数据长度(包括换行符) bytesConsumed;//accountforCRfrompreviousread}/***实际读取HDFS文件的方法*buffer:缓冲区*bufferLength:这一次读到的数据长度*/bufferLength=fillBuffer(in,buffer,prevCharCR);if(bufferLength<=0){break;//EOF}}//对读到的buffer数组数据进行遍历,找找第一个换行符//bufferPosn:读到换行符时的位置(索引),同一个分区中这个值是会保存的for(;bufferPosn<bufferLength; bufferPosn){//searchfornewlineif(buffer[bufferPosn]==LF){//调试时prevCharCR=false,当找到换行符\n时,newlineLength=1newlineLength=(prevCharCR)?2:1; bufferPosn;//atnextinvocationproceedfromfollowingbytebreak;}if(prevCharCR){//CR notLF,weareatnotLFnewlineLength=1;break;}//在linux平台测试数据中没看到等于\r的,也就是调试prevCharCR一直等于falseprevCharCR=(buffer[bufferPosn]==CR);}intreadLength=bufferPosn-startPosn;//这一次读取的数据长度(包括换行符)if(prevCharCR&&newlineLength==0){–readLength;//CRattheendofthebuffer}//总计读取的数据长度(包括换行符)bytesConsumed =readLength;//这一次读取的数据长度(不包括换行符)intappendLength=readLength-newlineLength;if(appendLength>maxLineLength-txtLength){//如果读到的数据长度,大于最大长度限制,做个控制//如果maxLineLength=0,txtLength=0时,此时是不需要读数据的,就给appendLength赋值为0appendLength=maxLineLength-txtLength;}if(appendLength>0){//如果计算appendLength>0时,把值赋值给str,也就是我们读到的值str.append(buffer,startPosn,appendLength);//txtLength变量累加每次实际读到的长度(不包括换行符)txtLength =appendLength;}//循环条件,是没有读到换行符,并且}while(newlineLength==0&&bytesConsumed<maxBytesToConsume);if(bytesConsumed>Integer.MAX_VALUE){thrownewIOException(“Toomanybytesbeforenewline:” bytesConsumed);}return(int)bytesConsumed;}
UncompressedSplitLineReader.fillBuffer()方法
protectedintfillBuffer(InputStreamin,byte[]buffer,booleaninDelimiter)throwsIOException{intmaxBytesToRead=buffer.length;//缓冲的大小,默认为64KB//splitLength当前partition的预分区大小(长度)//totalBytesRead当前partitition总共读取了的数据长度if(totalBytesRead<splitLength){//说明当前partition预分区长度还没有读完,还需要继续读取剩下的长度longleftBytesForSplit=splitLength-totalBytesRead;//checkifleftBytesForSplitexceedInteger.MAX_VALUEif(leftBytesForSplit<=Integer.MAX_VALUE){//做个比较,当前分区剩余的长度小于等于Integer.MAX_VALUE),取64KB默认长度和实际长度的一个小的值maxBytesToRead=Math.min(maxBytesToRead,(int)leftBytesForSplit);}}//实际读取的数据长度intbytesRead=in.read(buffer,0,maxBytesToRead);//Ifthesplitendedinthemiddleofarecorddelimiterthenweneed//toreadoneadditionalrecord,astheconsumerofthenextsplitwill//notrecognizethepartialdelimiterasarecord.//Howeverifusingthedefaultdelimiterandthenextcharacterisa//linefeedthennextsplitwilltreatitasadelimiterallbyitself//andtheadditionalrecordreadshouldnotbeperformed.if(totalBytesRead==splitLength&&inDelimiter&&bytesRead>0){if(usingCRLF){needAdditionalRecord=(buffer[0]!=’\n’);}else{needAdditionalRecord=true;}}if(bytesRead>0){//读到了数据,当前partitition读到的总数据长度做个累加totalBytesRead =bytesRead;}returnbytesRead;}