数据采集是进行大数据分析的前提也是必要条件,在整个流程中占据重要地位。本文将介绍大数据三种采集形式:系统日志采集法、网络数据采集法以及其他数据采集法。
(一)系统日志采集法
系统日志是记录系统中硬件、软件和系统问题的信息,同时还可以监视系统中发生的事件。用户可以通过它来检查错误发生的原因,或者寻找受到攻击时攻击者留下的痕迹。系统日志包括系统日志、应用程序日志和安全日志。目前此类的采集技术大约可以每秒传输数百MB的日志数据信息,满足了目前人们对信息速度的需求。一般而言与我们相关的并不是此类采集法,而是网络数据采集法。
(二)网络数据采集法
做自然语言的同学可能对这点感触颇深,除了目前已经存在的公开数据集,用于日常的算法研究外,有时为了满足项目的实际需求,需要对现实网页中的数据进行采集,预处理和保存。目前网络数据采集有两种方法一种是API,另一种是网络爬虫法。
1.API
API又叫应用程序接口,是网站的管理者为了使用者方面,编写的一种程序接口。该类接口可以屏蔽网站底层复杂算法仅仅通过简简单单调用即可实现对数据的请求功能。目前主流的社交媒体平台如新浪微博、百度贴吧以及Facebook等均提供API服务,可以在其官网开放平台上获取相关DEMO。但是API技术毕竟受限于平台开发者,为了减小网站(平台)的负荷,一般平台均会对每天接口调用上限做限制,这给我们带来极大的不便利。为此我们通常采用第二种方式——网络爬虫。
2.网络爬虫
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOFA社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。(百度百科)最常见的爬虫便是我们经常使用的搜索引擎,如百度,360搜索等。此类爬虫统称为通用型爬虫,对于所有的网页进行无条件采集。通用型爬虫具体工作原理见图1。
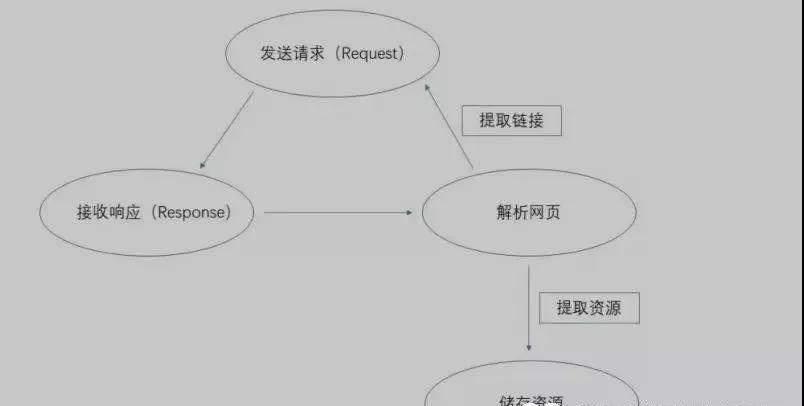
图1爬虫工作原理[2]
(三)其他采集法
其他采集法是指对于科研院所,企业政府等拥有机密信息,如何保证数据的安全传递?可以采用系统特定端口,进行数据传输任务,从而减少数据被泄露的风险。
【结语】大数据采集技术是大数据技术的开端,好的开端是成功的一半,因此在做数据采集时一定要谨慎选择方法,尤其是爬虫技术,主题爬虫应该是对于大部分数据采集任务而言是较好的方法,可以深入研究。

联系我们
公司名称:长春富林科技有限公司