假设你现在手头上有一个用户的观影历史数据矩阵,这个矩阵的行表示用户,列表示电影,矩阵中的元素为观众给电影的星级,1-5代表着用户对电影的喜爱程度递增。矩阵局部见下图:
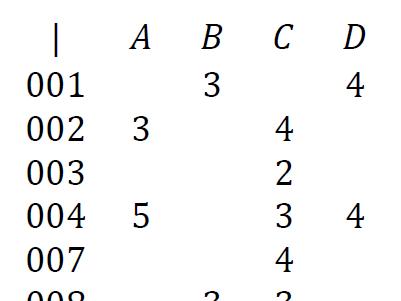
如果需要设计一个简单的算法向观众001推荐他可能喜欢的电影,在协同过滤推荐算法里,如果使用基于基于用户的协同过滤,我们需要先找到与观众001相似的另一个用户B,并将B感兴趣而001没有看过的电影推荐给001,此时就是将用户-商品矩阵中对应的空白元素位置进行填充值。因此,基于协同过滤的推荐算法本质上是矩阵补全。
一、简介
矩阵补全(matrix completion),顾名思义就是将一个含有缺失值的矩阵通过一定的方法将其恢复为一个完全的矩阵。目前该领域比较完全的理论是由Candes等人在2008年的论文《Exact Matrix Completion via Convex Optimization》,通过解一个凸优化问题实现将一个低秩矩阵恢复。
为什么要求是低秩呢?我们知道矩阵的秩度量的是矩阵行列之间的相关性,如果矩阵各行或各列是线性无关的,那么其是一个满秩的矩阵,这里的低秩相对于矩阵的行数和列数而言的,如果矩阵的秩远小于此,则矩阵就是一个低秩的矩阵。可见,低秩矩阵其实包含有很多的冗余信息,在矩阵补全里面,为了借助已有的观测到的数据来恢复成完全的矩阵,我们需恰恰要这种冗余。
目前矩阵补全主要被应用在图像恢复(SR)和推荐系统(协同过滤)两个方面。在推荐中的知名应用是Netflix的矩阵补全比赛,获奖的文章《The BellKor Solution to the Netflix Grand Prize》,这一篇文章用到了矩阵分解(Matrix Factorization)等多种算法的结合。(注意:矩阵分解(Matrix Factorization)是指用 A*B 来近似不完全的矩阵M,那么 A*B 的元素就可以用于估计M中对应空缺位置的元素值,而A*B可以看做是M的分解。显然,矩阵分解可以用于矩阵补全任务。)
二、数学原理
经过上面的简单描述,矩阵补全问题可以表述为:假如M是现有的数据集(大部分缺失),矩阵补全的目的就是找到一个和矩阵M观测到的部分差距尽量小并且秩(rank)最小的矩阵X。其数学形式如下:
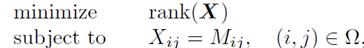
但这是一个非凸的问题(NP-hard),所以Candes等人提出了用rank(X)的最优途径式nuclear norm形式来替代rank,形如:
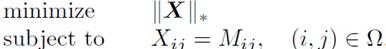
其中,目标函数表示矩阵X的singular value之和:
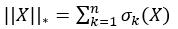
三、算法实现
参考文献:《A singular value thresholding algorithm for matrix completion》,是Candes等人在2008年完成的论文。
3.1 基本思路
(1)当τ很大的时候,可以用下式来近似核范式(nuclear norm):
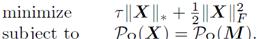
(2)singular value shrinkage
将一个秩为r的矩阵X进行奇异值分解(SVD):
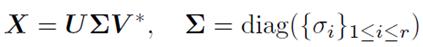
对于每个T>=0,有软阈值操作(soft-thresholding operator)DT:
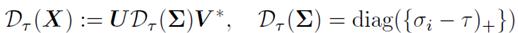
(其中 T>=0 ,这个软阈值操作仅仅应用于矩阵X的奇异值上,使它们趋于零,因此也将其称为singular value shrinkage operator)
(3)据证明singular value shrinkage是nuclear norm的近似,则将上式变形为:
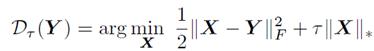
(4)运用拉格朗日乘子法得到迭代解:
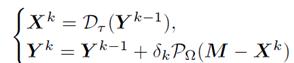
3.2 算法实现
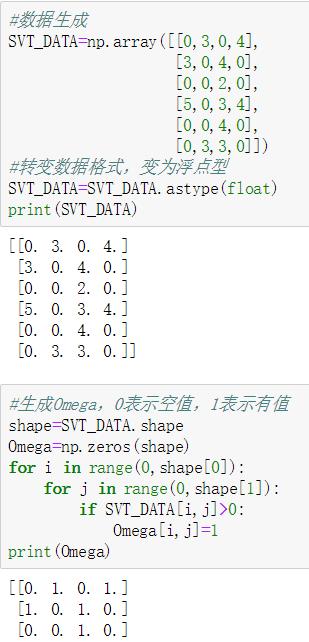
3.2.1 数据生成
3.2.2 SVT
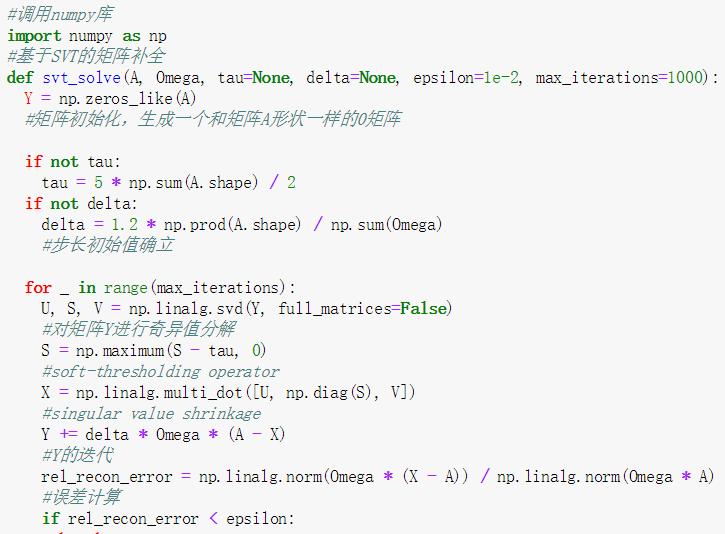

补充(一)函数介绍
(1) maximum函数
——比较两个array的大小,生成一个包含较大元素的新array
语法:numpy.maximum(x1, x2)
示例:

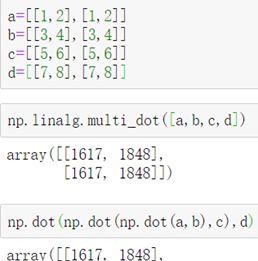
(2)numpy.linalg.multi_dot
——计算两个及以上array的乘积,并且自动选择最快的求积顺序,和numpy.dot的区别在于,后者只可以乘两个序列。
语法:numpy.linalg.multi_dot(arrays)
示例:
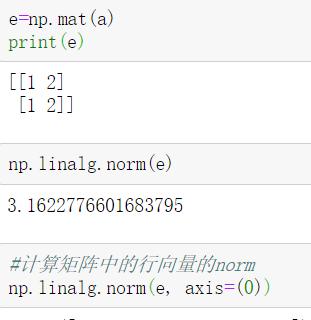
(3)np.linalg.norm
——计算矩阵或者向量的norm
语法:numpy.linalg.norm(x, ord=None, axis=None, keepdims=False)
示例:
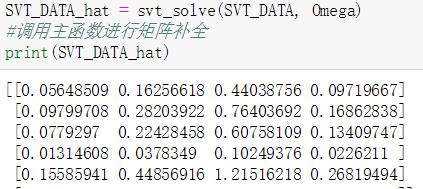
3.2.3 运行结果
四、应用实例
4.1 推荐方法
回到我们最初的问题,因为现实中,某一个用户看过的电影数量相对于总电影数目来说是非常小的,这也造成了在用户-电影矩阵中将包含有比较多的空白(0),但是我们又知道用户对电影是有一定偏好的,比如喜欢悬疑、喜据或者科幻类,这样一类用户他们的偏好的给与较高的电影评分,造成用户与用户之间会有一定的线性关系,这说明了这个稀疏矩阵同时也是一个低秩矩阵。那么,问题就变成了针对这样一个非常稀疏并且低秩的大矩阵,如何实现比较准确同时速度比较快的推荐呢?
推荐方法:
本文的推荐方法参考Zhao Kang等人的文章《Top-N Recommender System via Matrix Completion》“To use the estimated matrix ??X to make recommendation for user i, we just sort i’s non-purchased/-rated items based on their scores in decreasing order and recommend the Top-N items.”)
4.2 算法实现
Movies-Lens的rating数据,局部见下图:
4.2.2 数据预处理
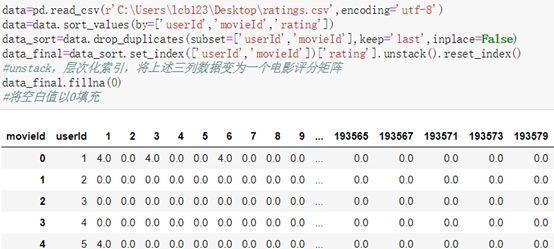
将数据转置为一个矩阵,其中行索引为用户ID,列索引为电影ID,矩阵内元素为用户对电影的评级。将矩阵中空白元素以0填充。这样一个低秩、稀疏的矩阵就构造好了。
4.2.3 数据准备
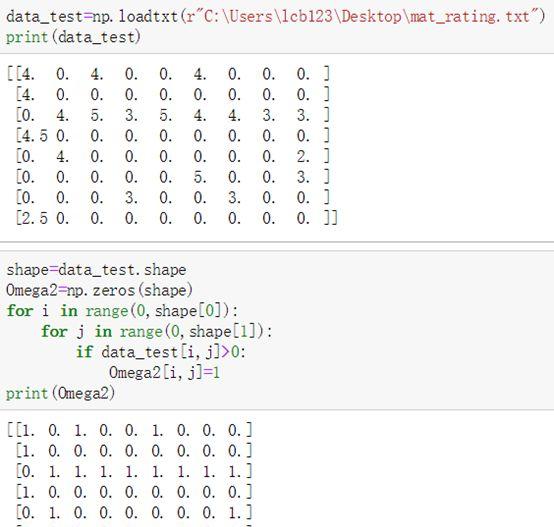
为了计算快捷,这里就不用全部数据集进行,而是从中摘取部分数据进行演示。
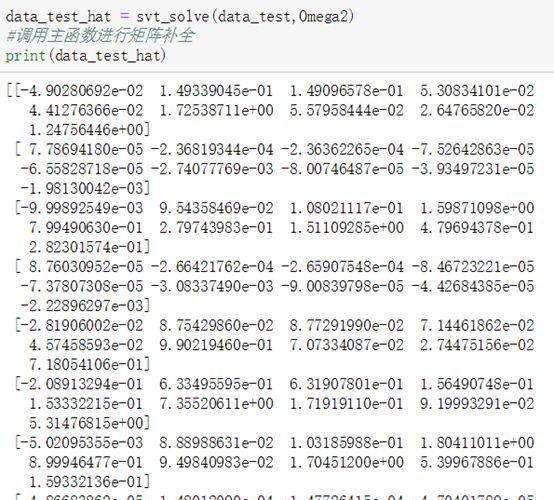
4.2.4 算法运行
4.3 推荐实现
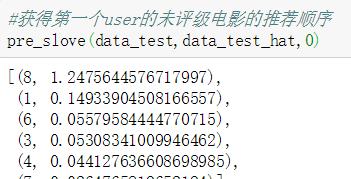
4.3.1 推荐过程

4.3.2 推荐结果
责编 | 罗
指导 | 老薛